Fundamental Data Structures
Algorithm Engineering — L04
The choice decides the layout
Same sixteen integers, two containers — two very different shapes in memory.

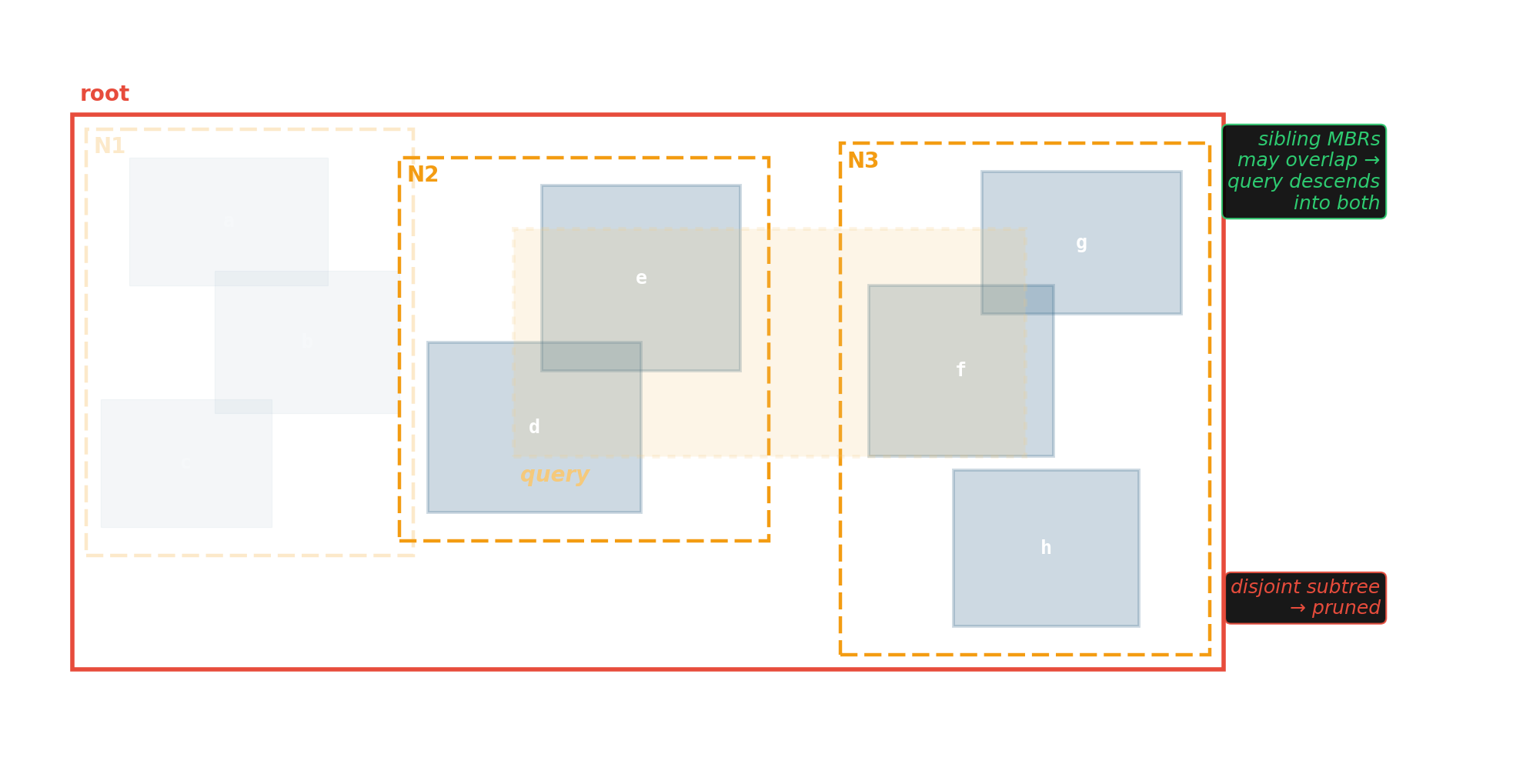
std::deque — the Swiss army knife nobody should open
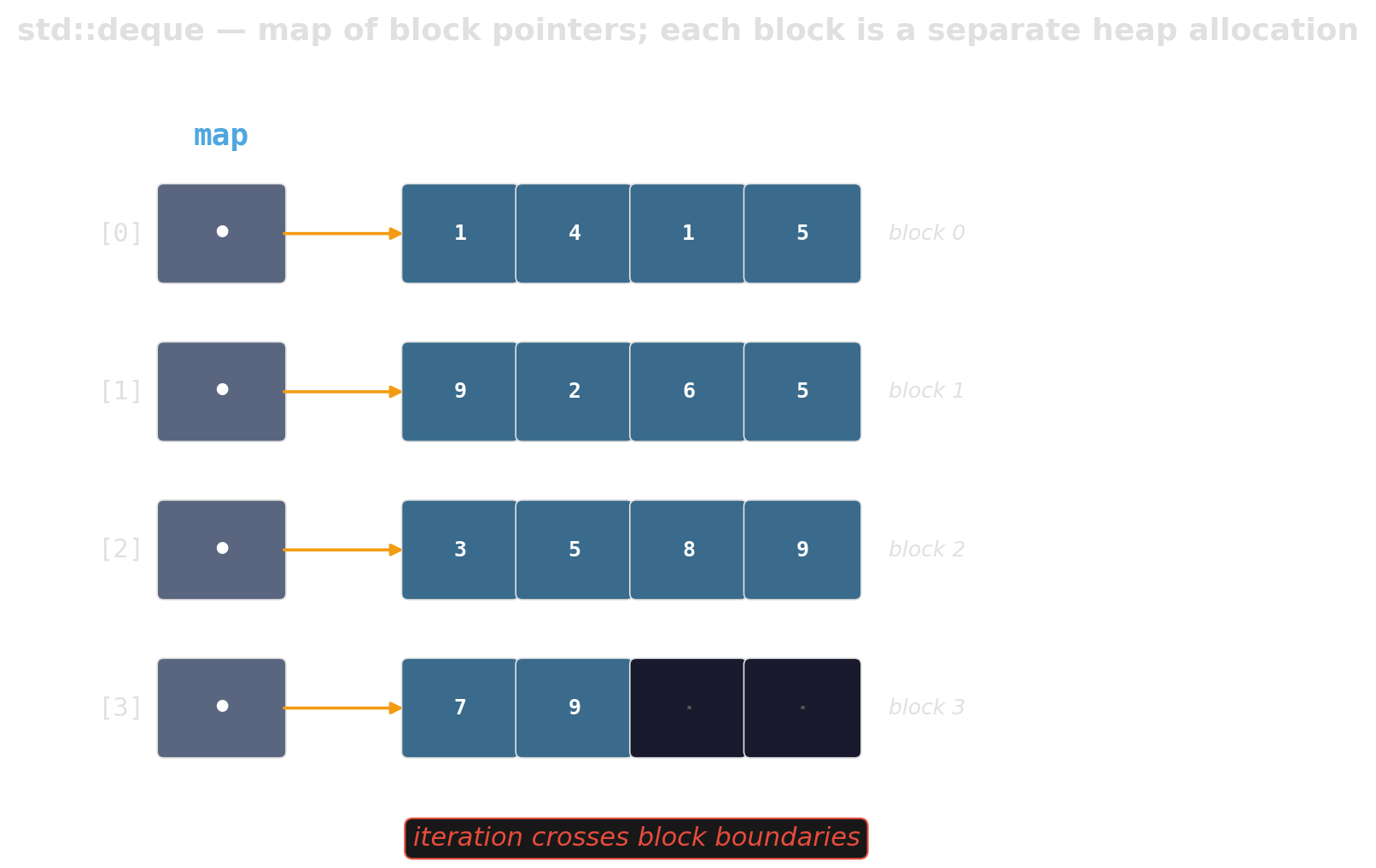
A map of pointers to blocks. Every iterator increment risks crossing a block boundary; every implementation is slightly different and usually slower than its specification suggests.
Prefer vector-as-queue
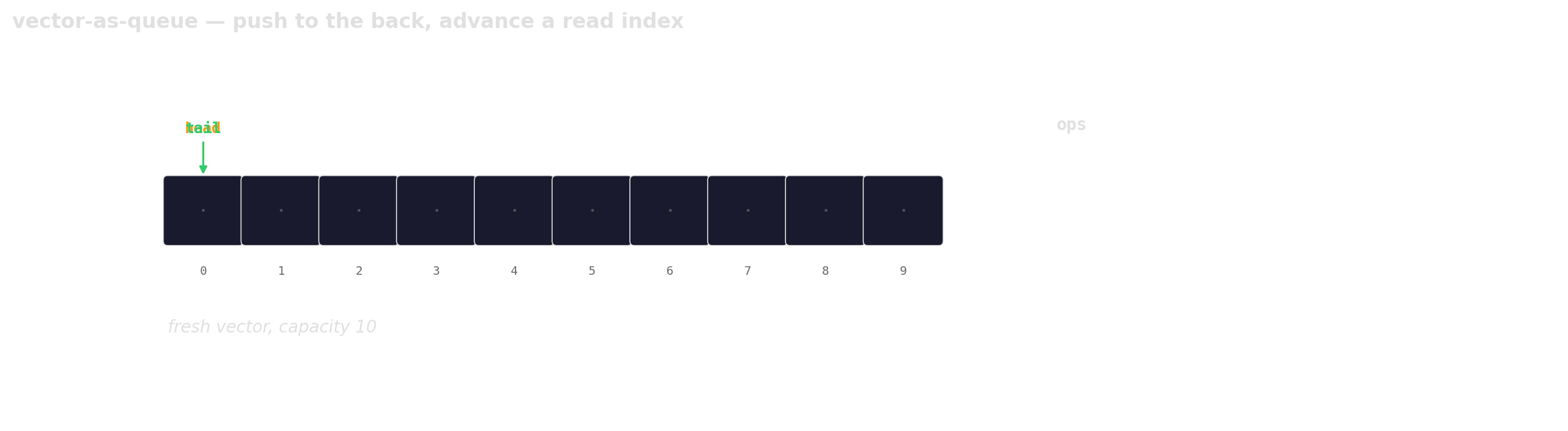
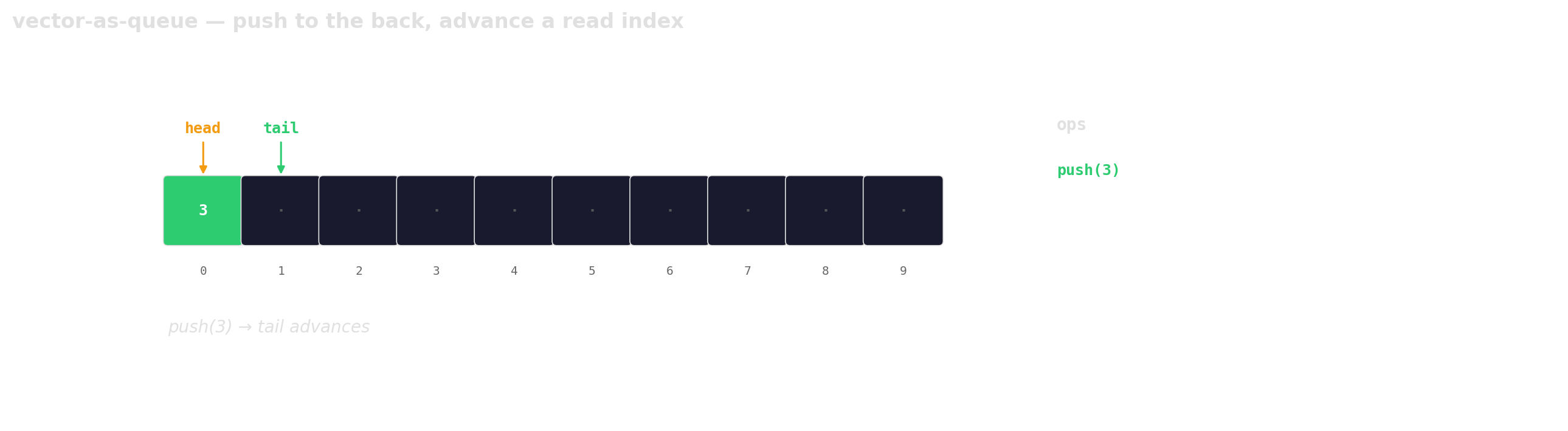
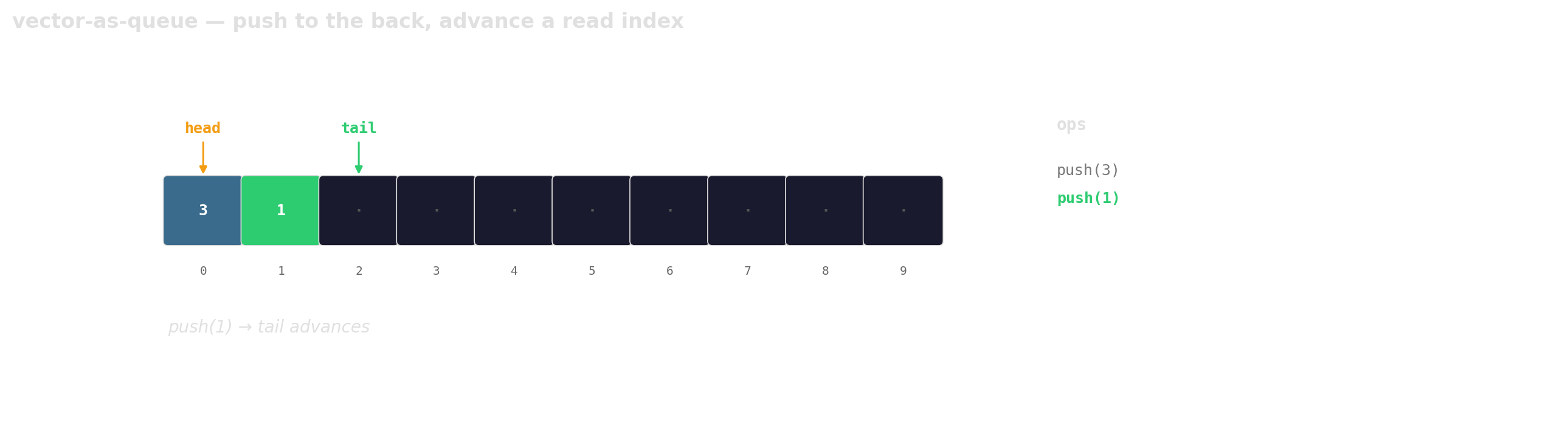
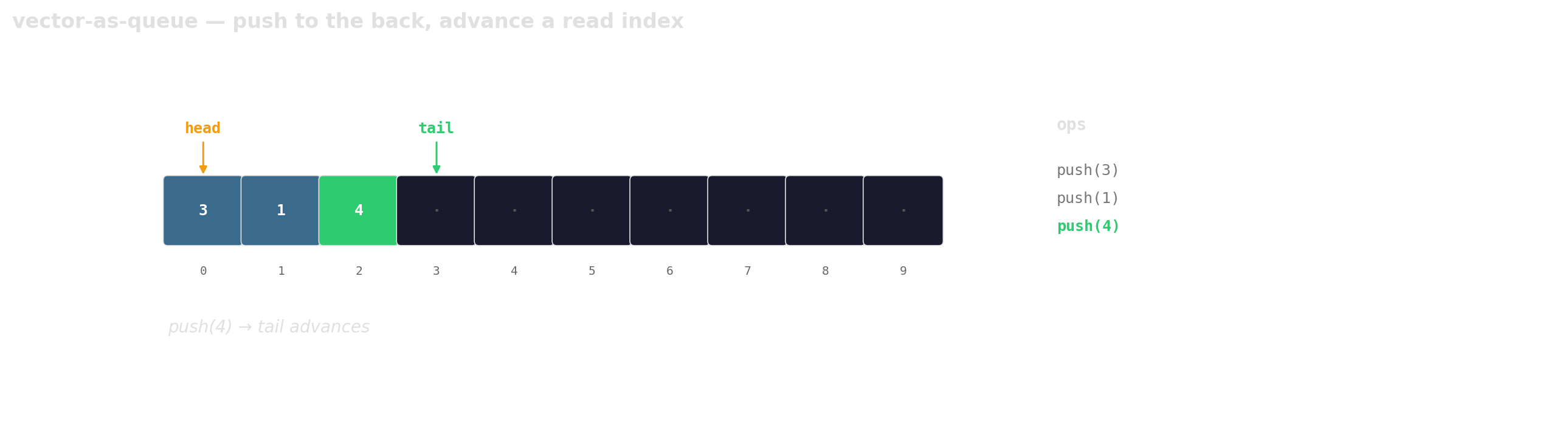
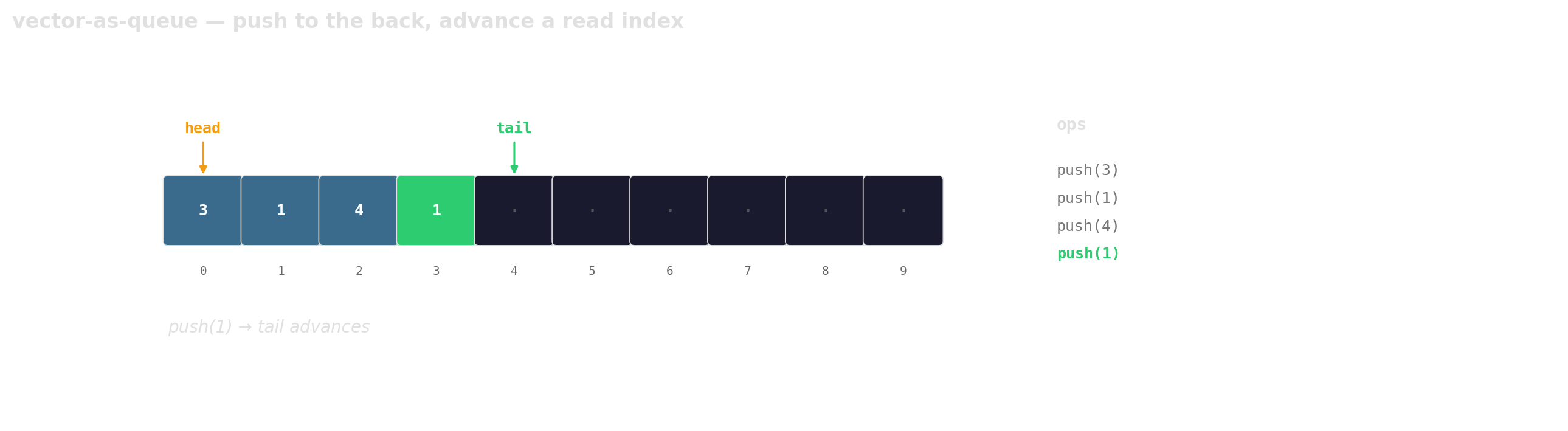
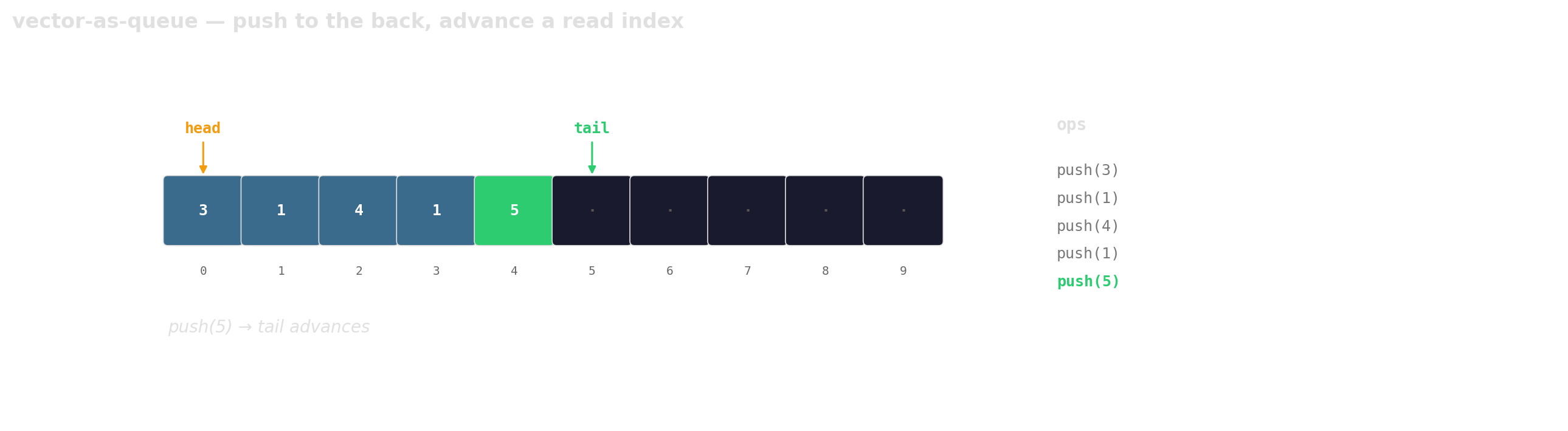
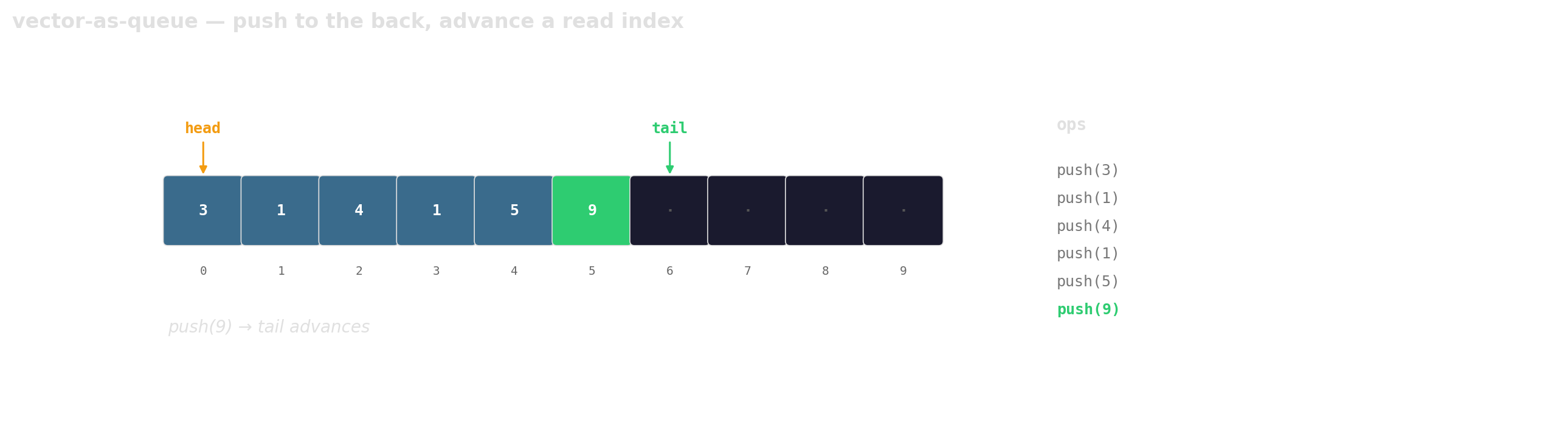
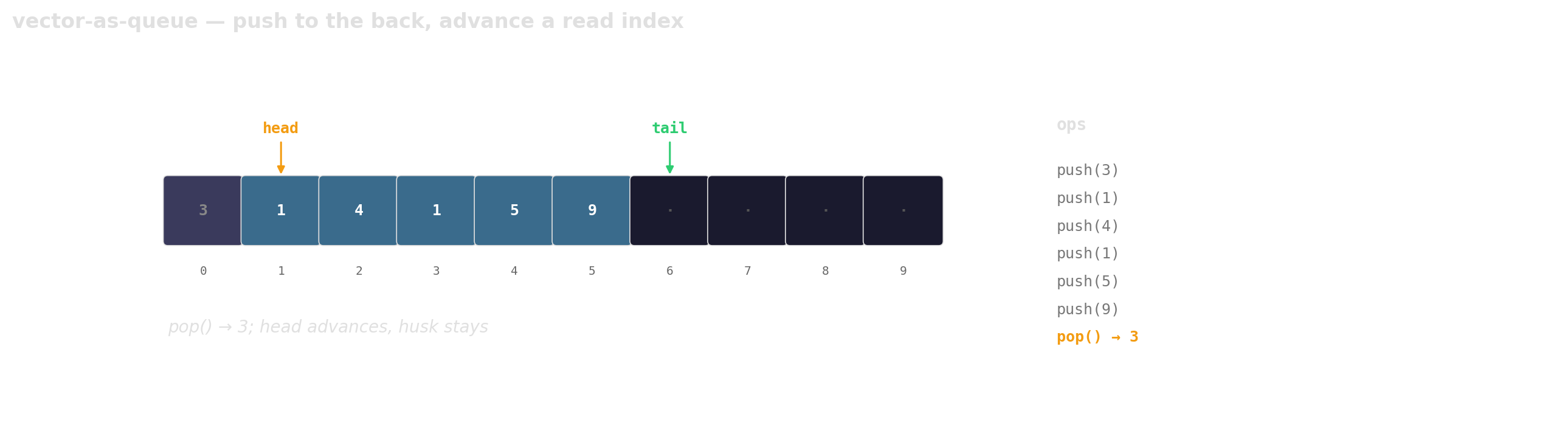
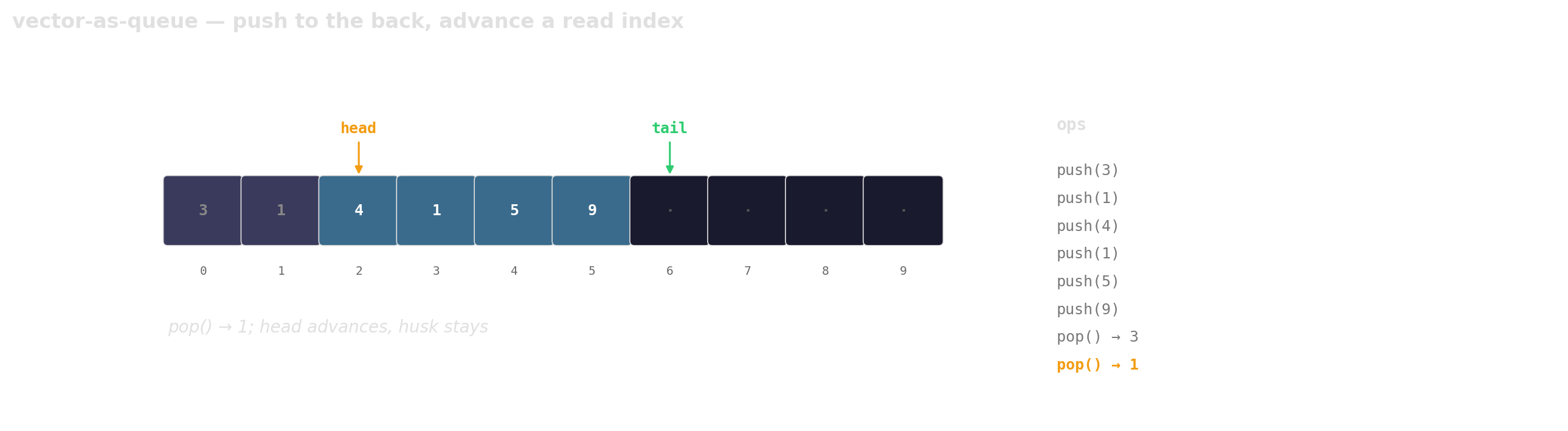
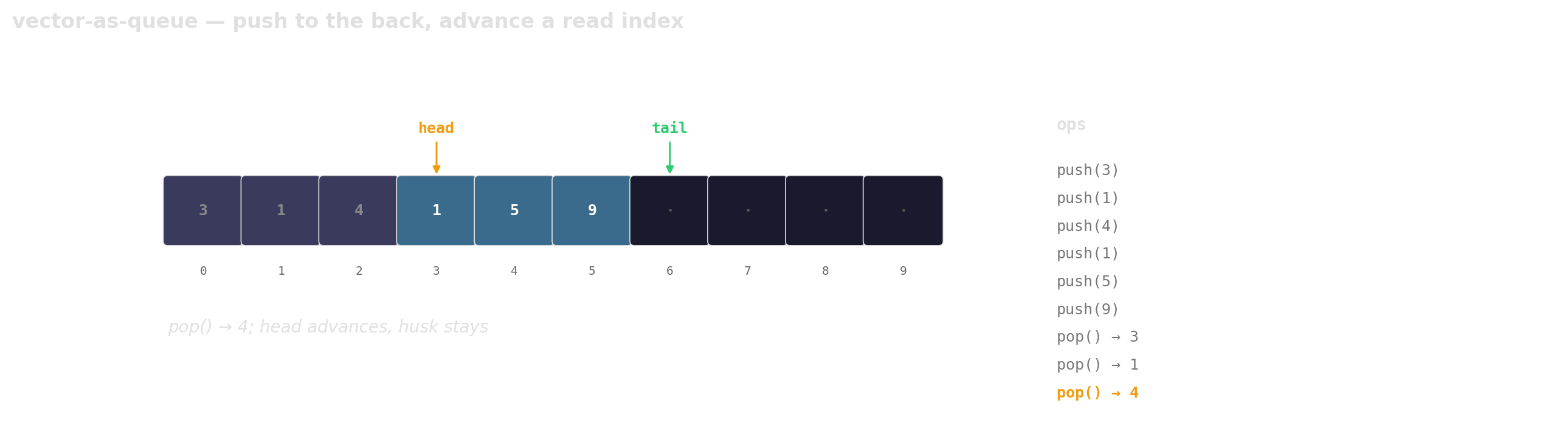
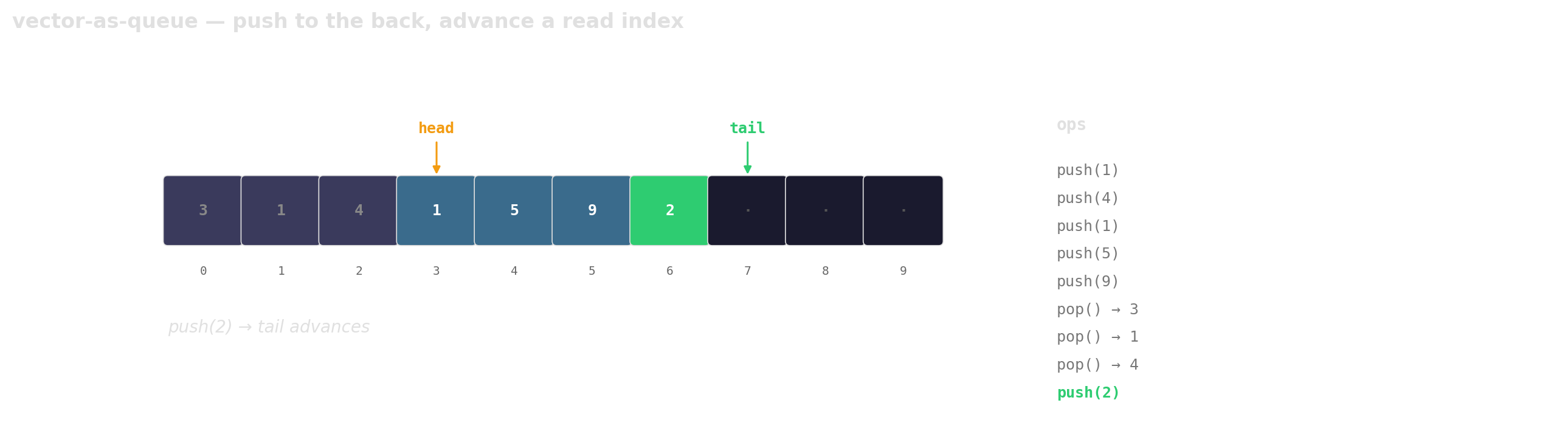
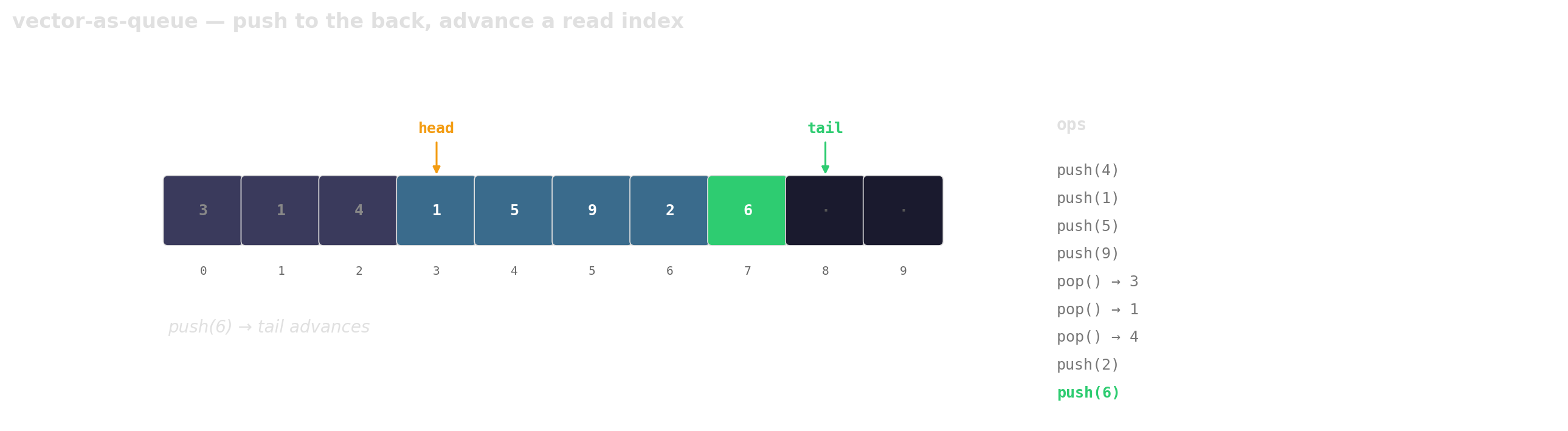

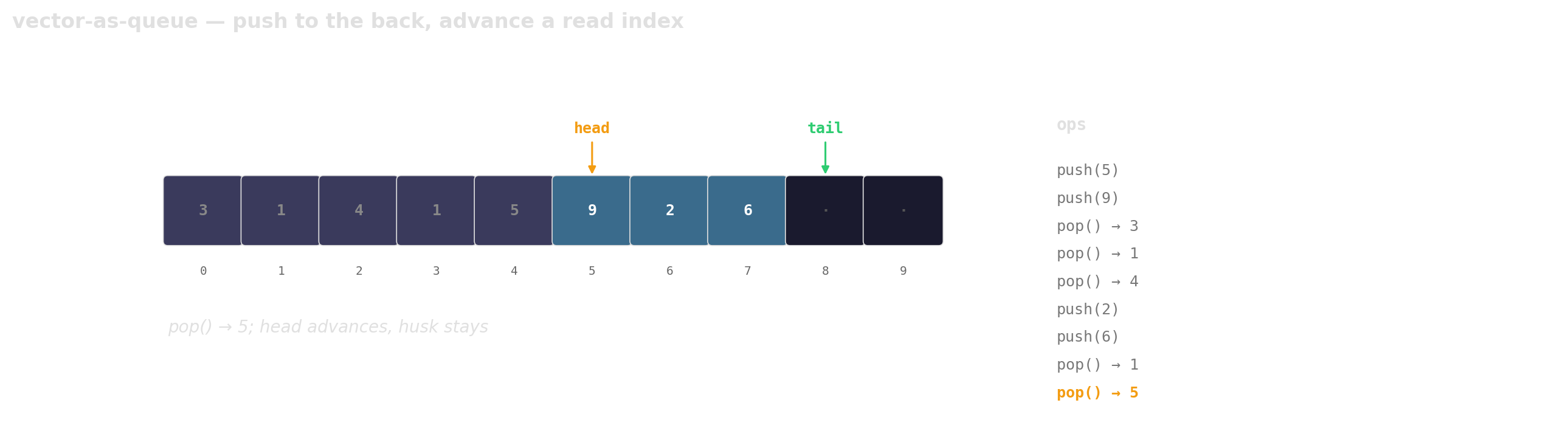
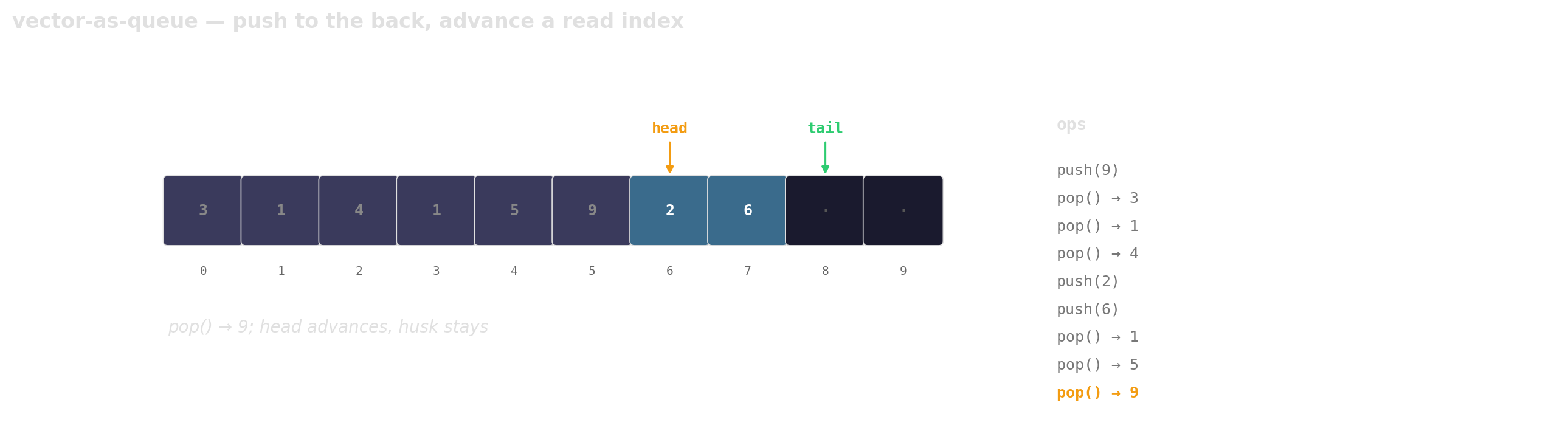
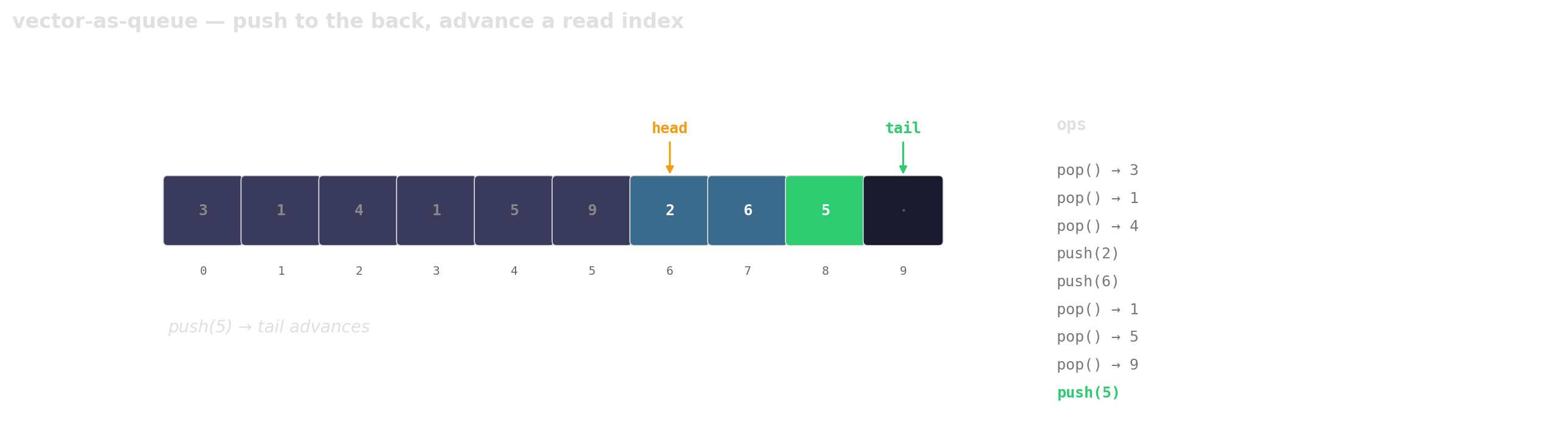
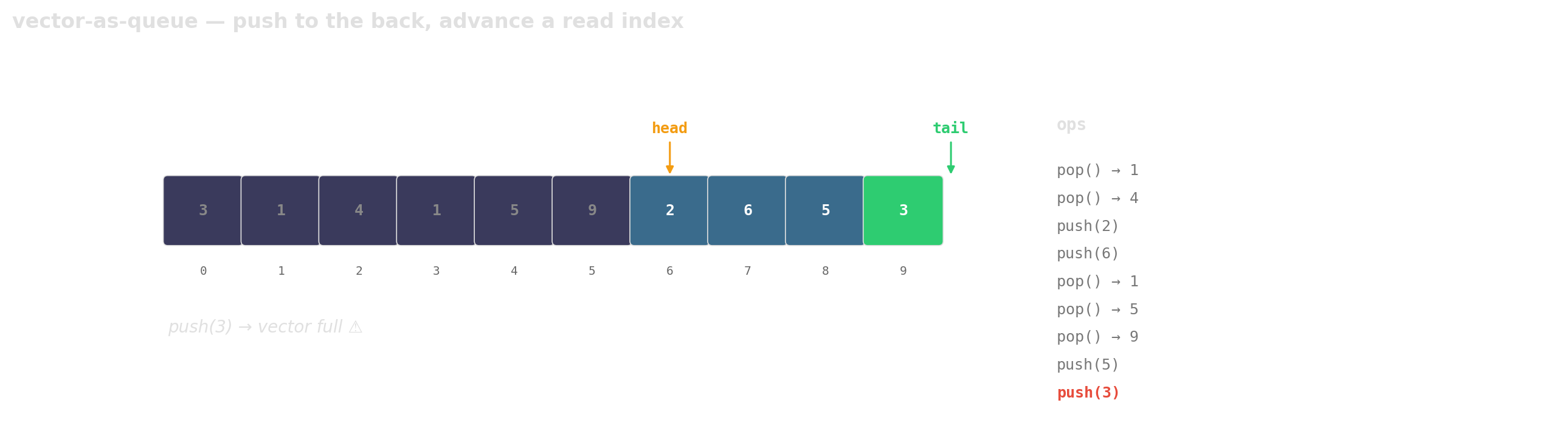
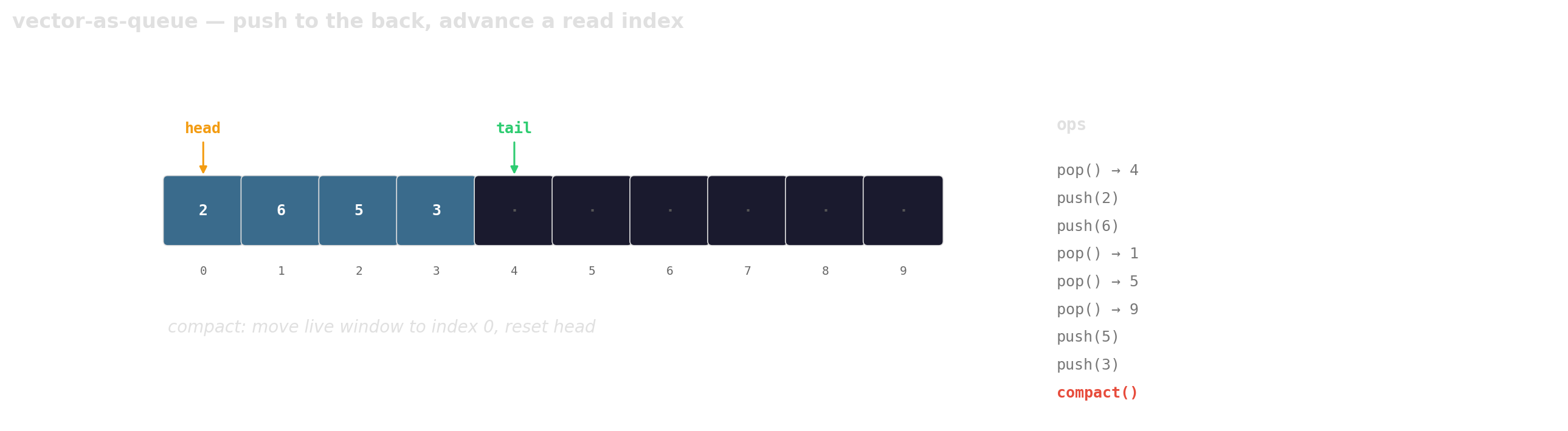
Trade a little memory (the husks) for contiguous layout, a single allocation, and one cache line per hop.
Small-buffer optimization
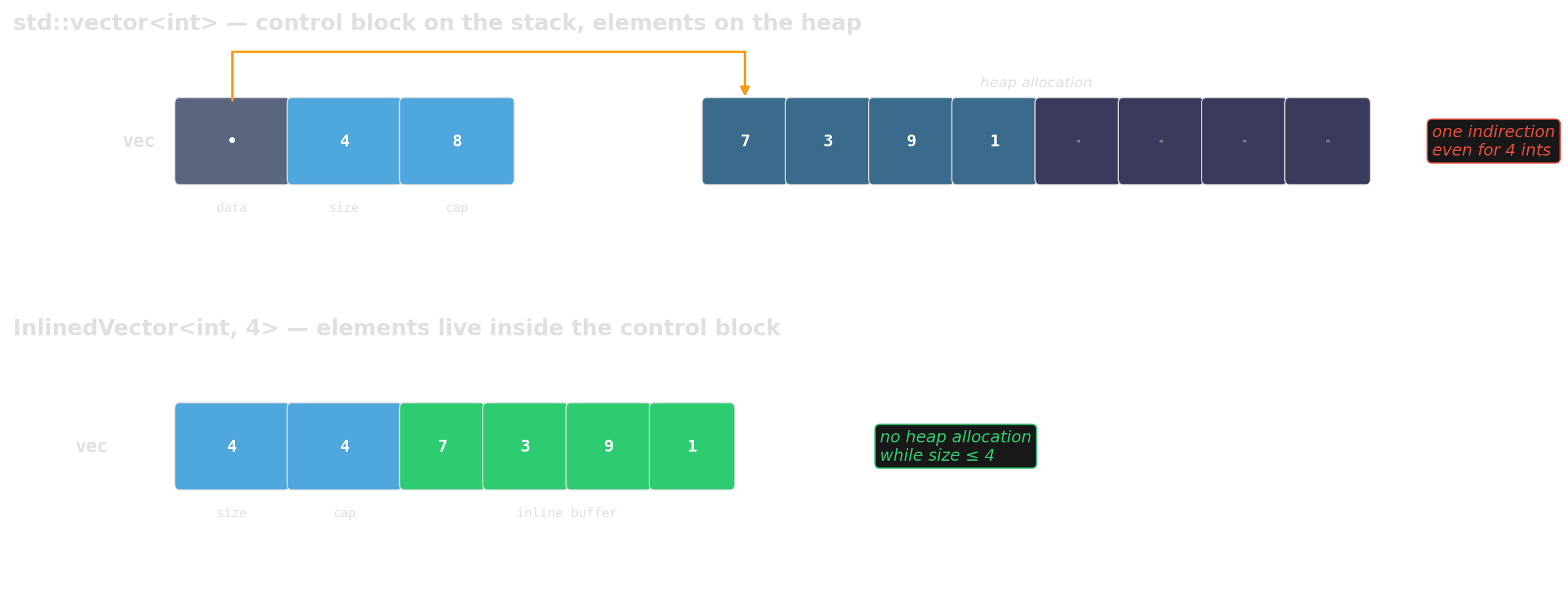
Worth reaching for: absl::InlinedVector, boost::small_vector, llvm::SmallVector.
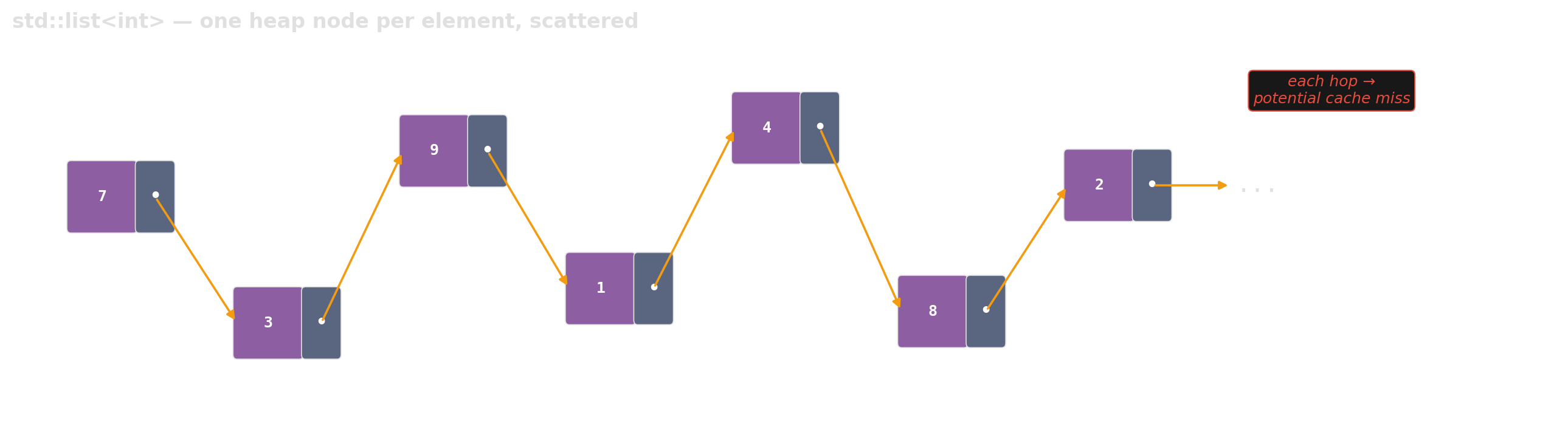
std::unordered_map is a linked list in disguise
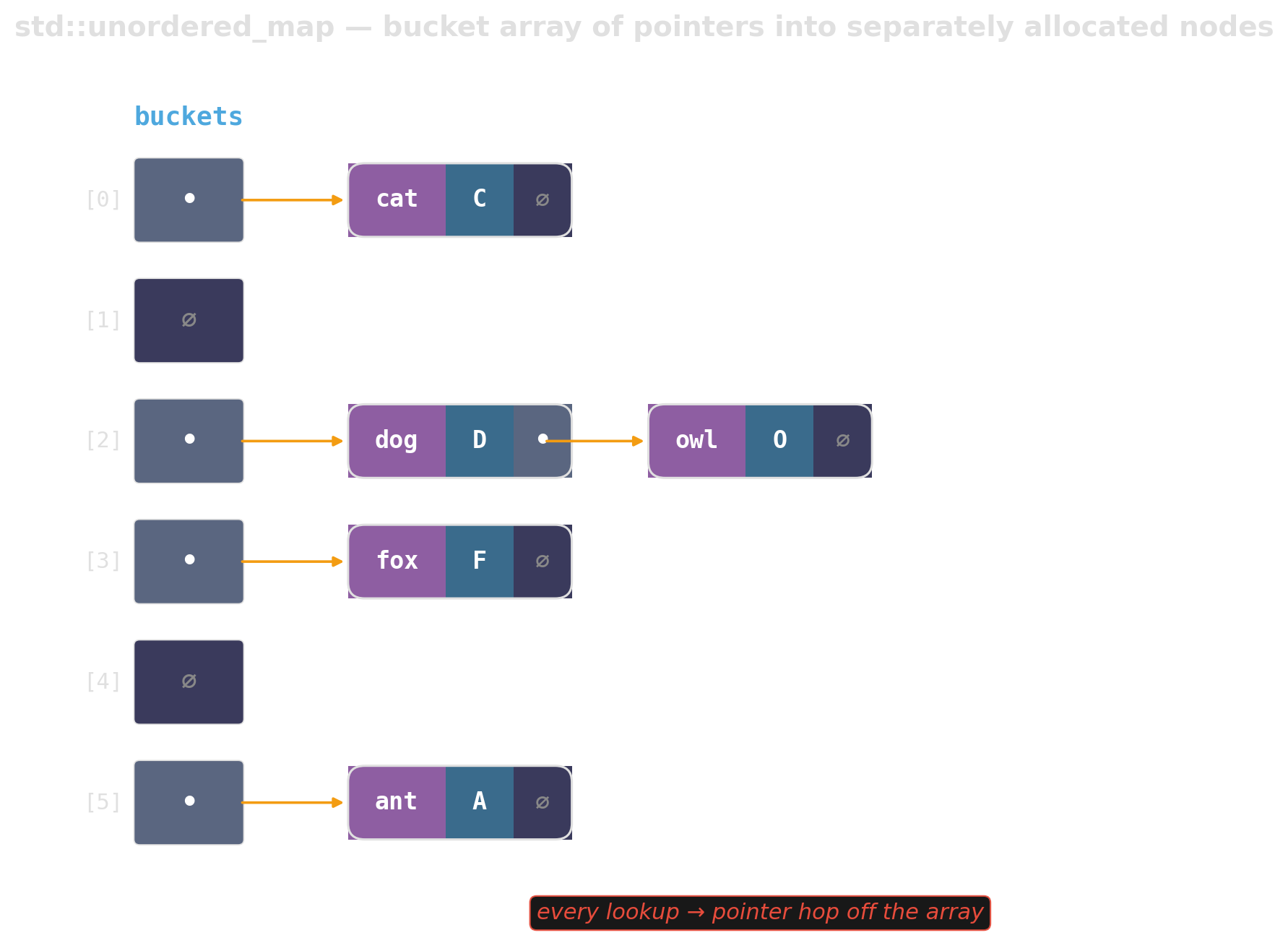
The bucket array holds pointers to heap-allocated nodes. Every insert allocates; every lookup chases a pointer off the array.
Open addressing — keep collisions local
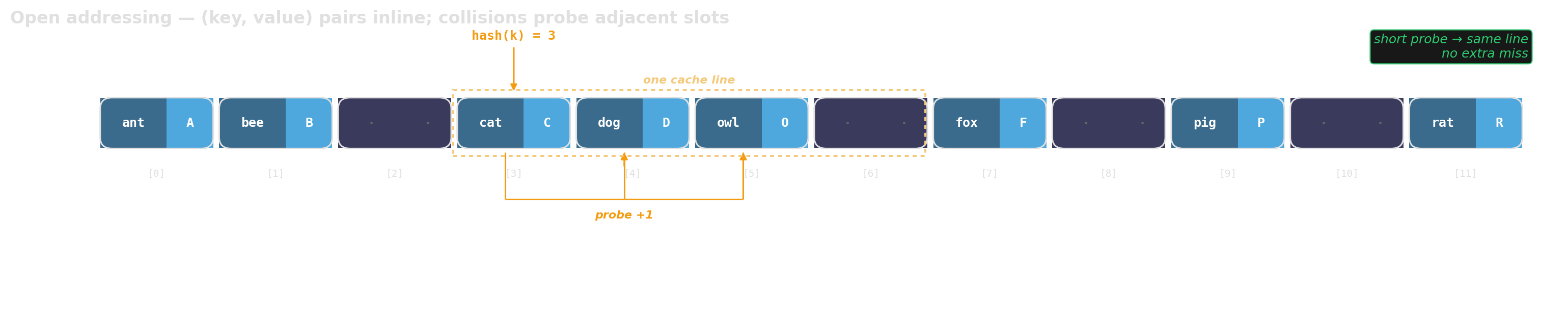
One allocation. Collisions probed in adjacent slots. A miss stays in the same cache line.
But: wide values → few slots per cache line. Every probe step = fresh cache line.

Swiss tables — split metadata from data
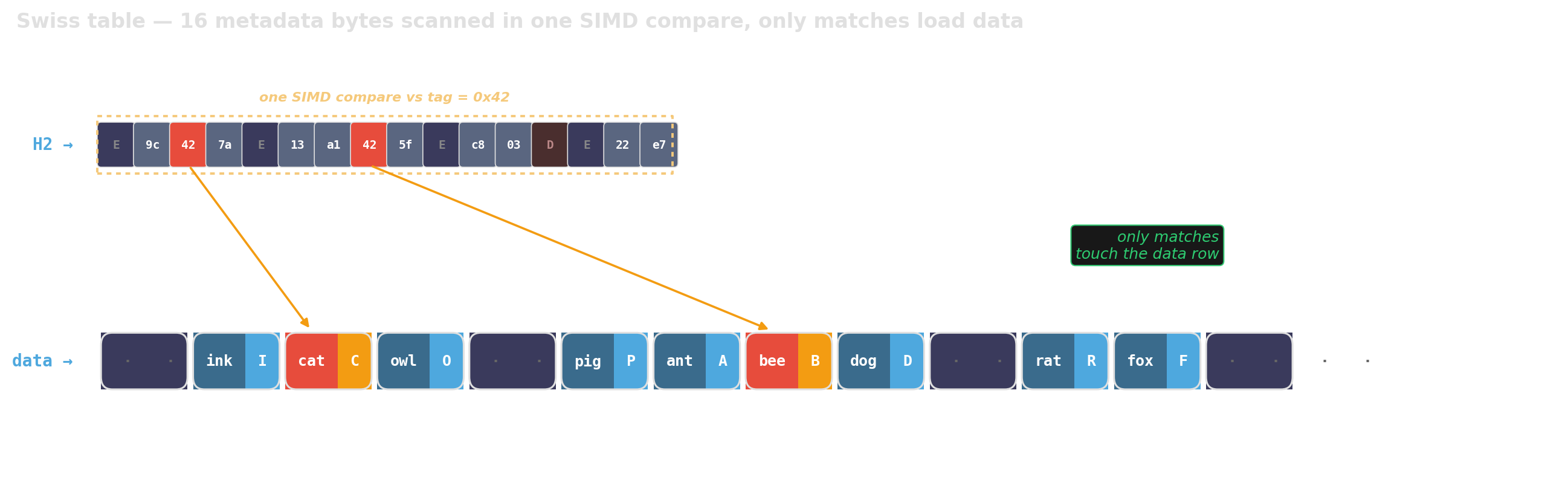
Tiny metadata array scanned before any key is touched — 16 slots per cache line, regardless of value width.
A single SIMD instruction checks all 16 tags at once; only matches pay to read the full key-value pair.
std::map is a red-black tree
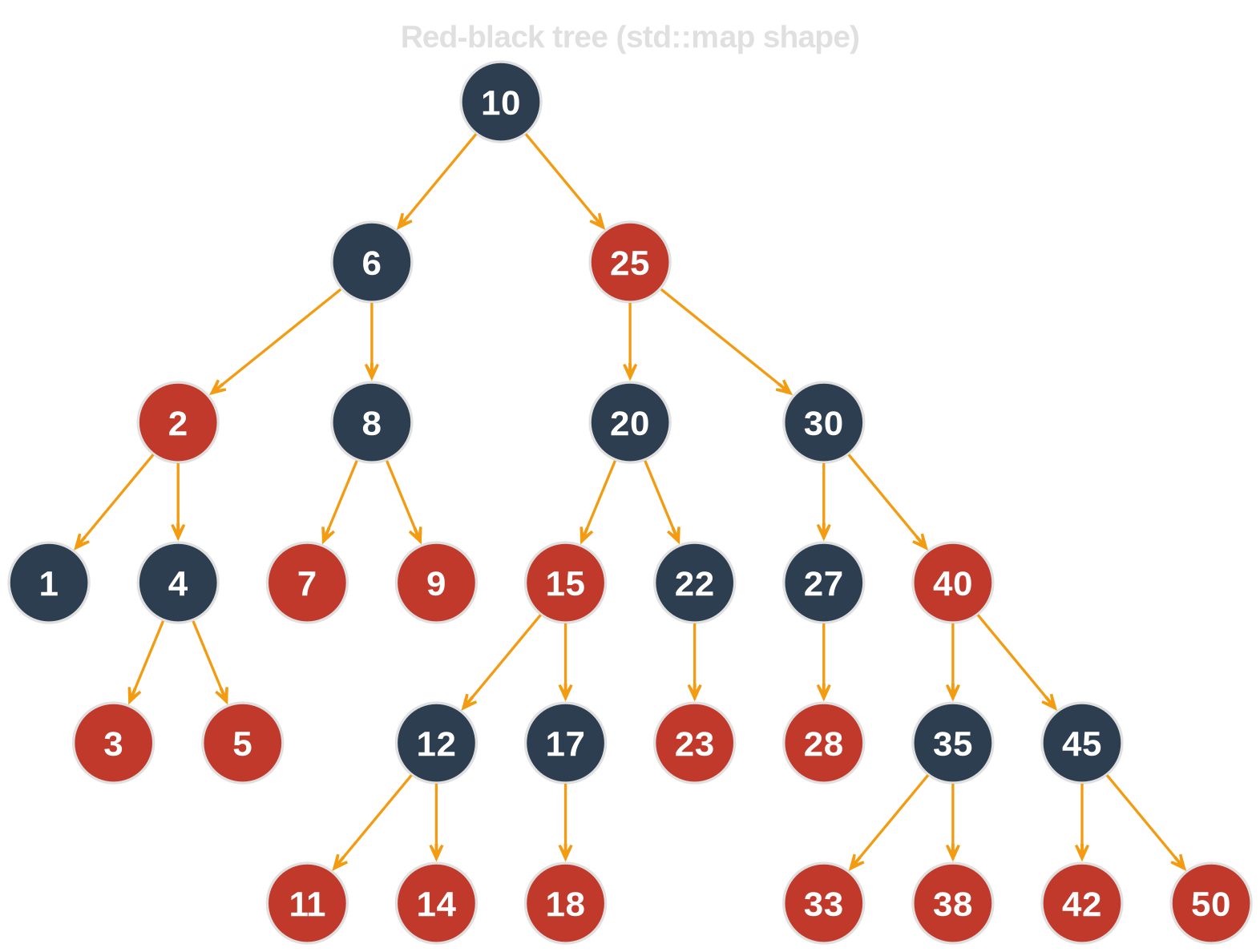
30 keys → 30 separate allocations, 6 levels deep. std::map is std::list with a sorting invariant — per-node malloc, plus rebalancing on every insert.
B-tree: same keys, one cache line per node
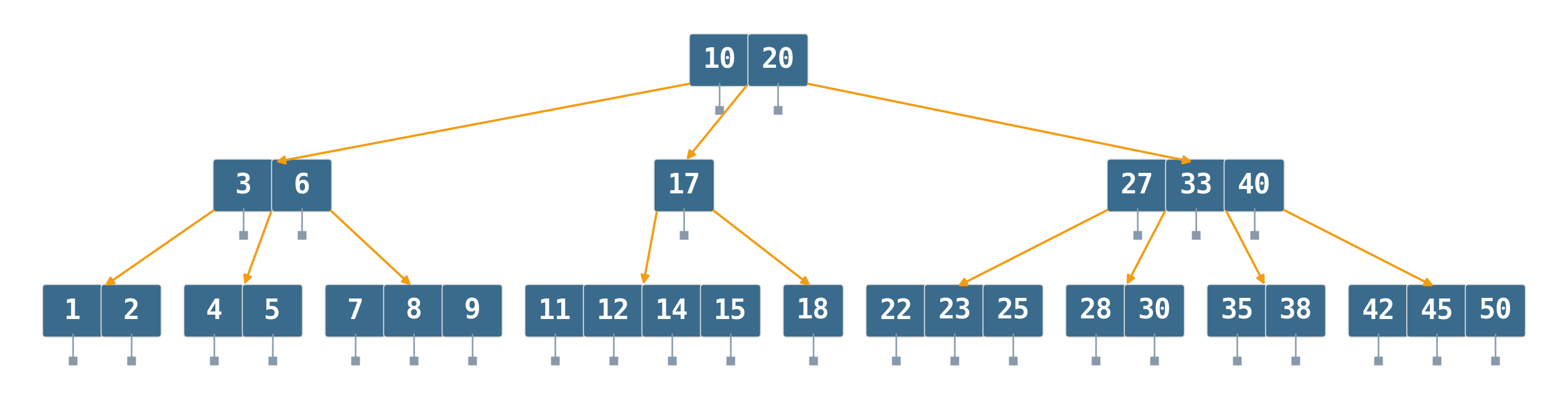
30 keys → 13 nodes, 3 levels (order 5). Every key still carries its own value pointer (gray stubs).
Node sized to one cache line ⇒ one cache miss per level ⇒ logarithm in the branching factor, not in two.
B+ tree: routing on top, values in leaves

Internal nodes = pure routing. All values live in leaves. Leaves linked for range scans.
Range query = one tree descent + a linear walk over the leaf chain. This is why every database uses B+.
Binary heap: implicit tree in a flat array
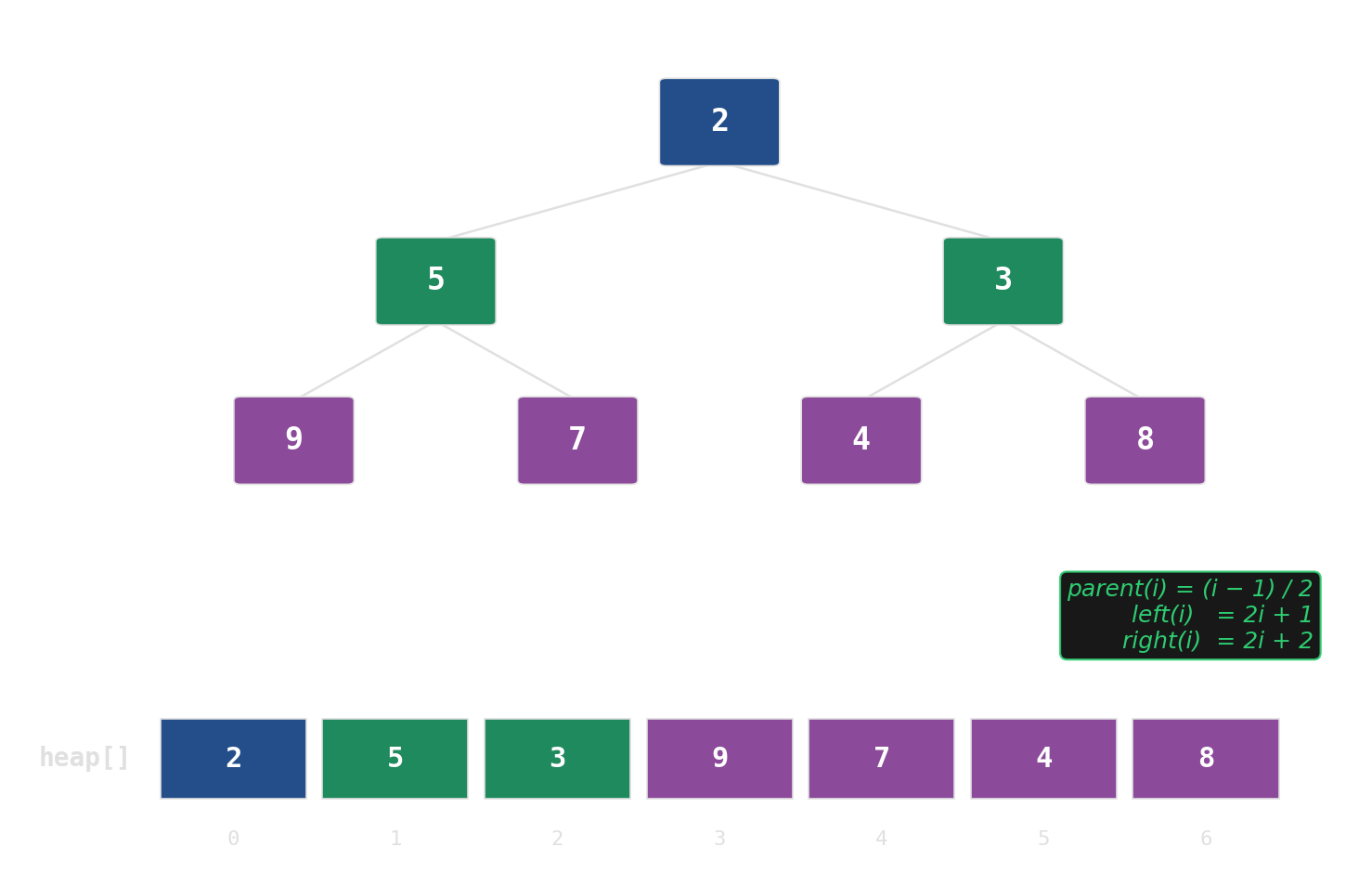
No pointers, no per-node allocations. The tree is index arithmetic on a std::vector.
push: append, then bubble up
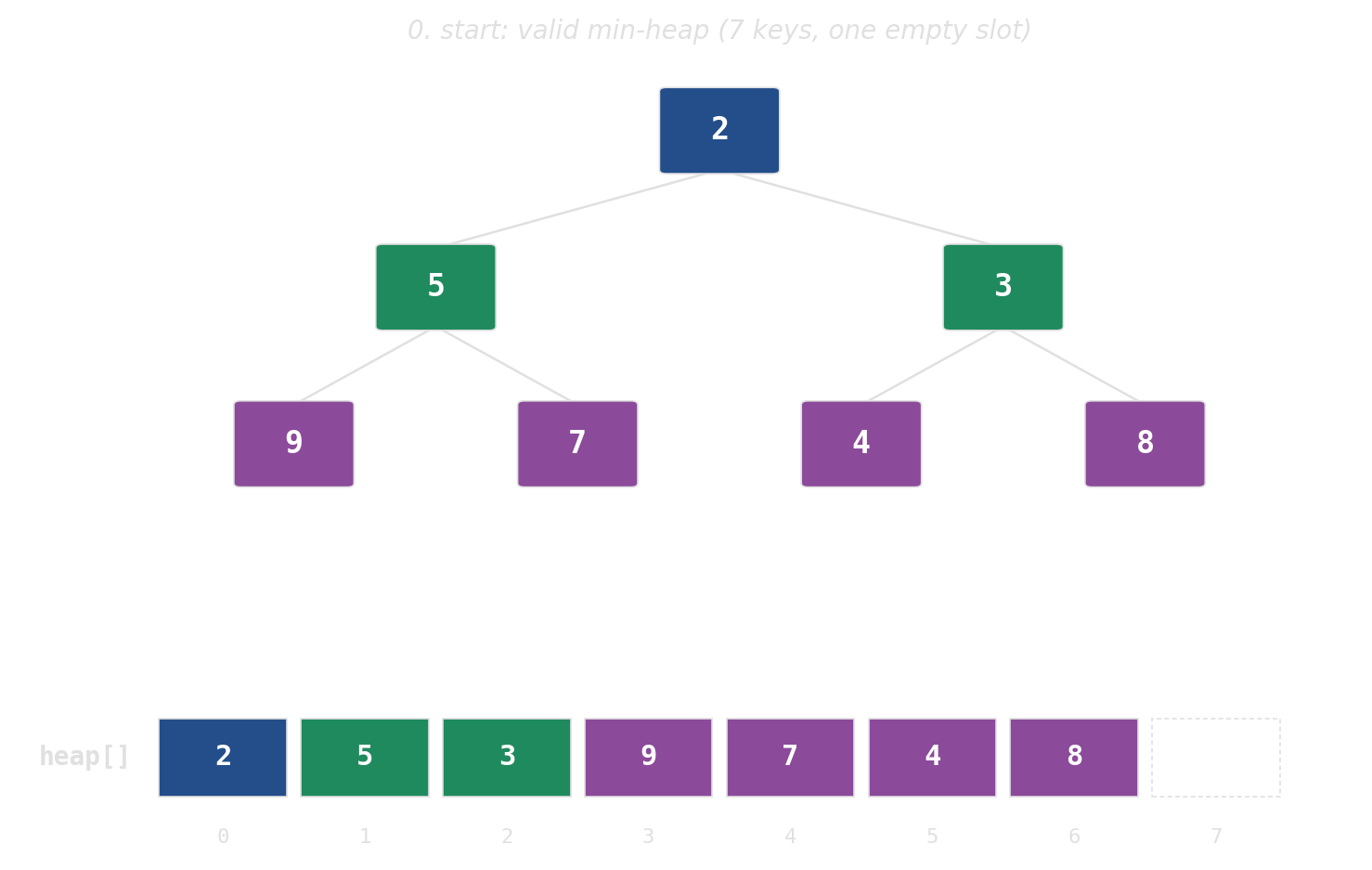
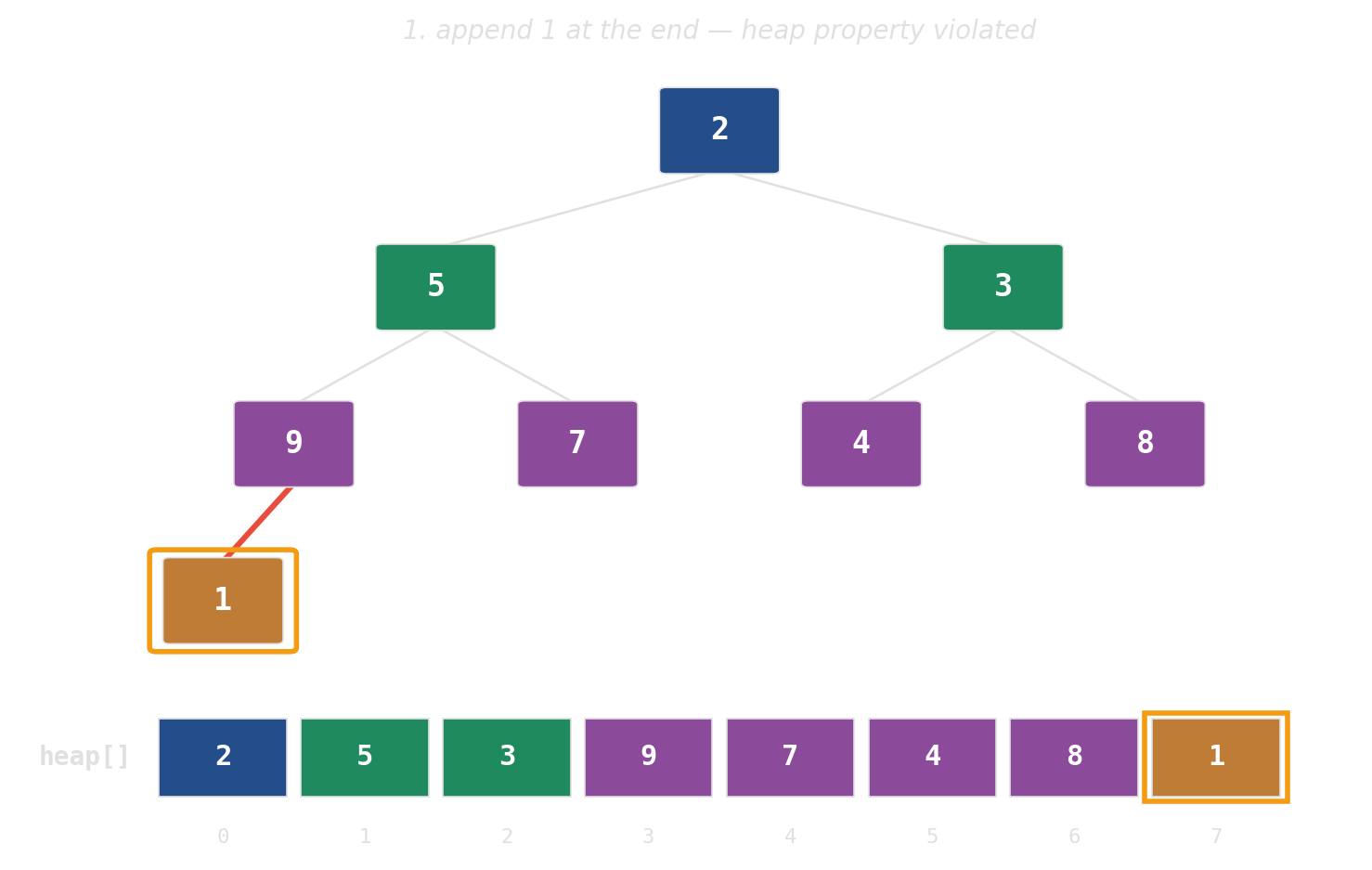
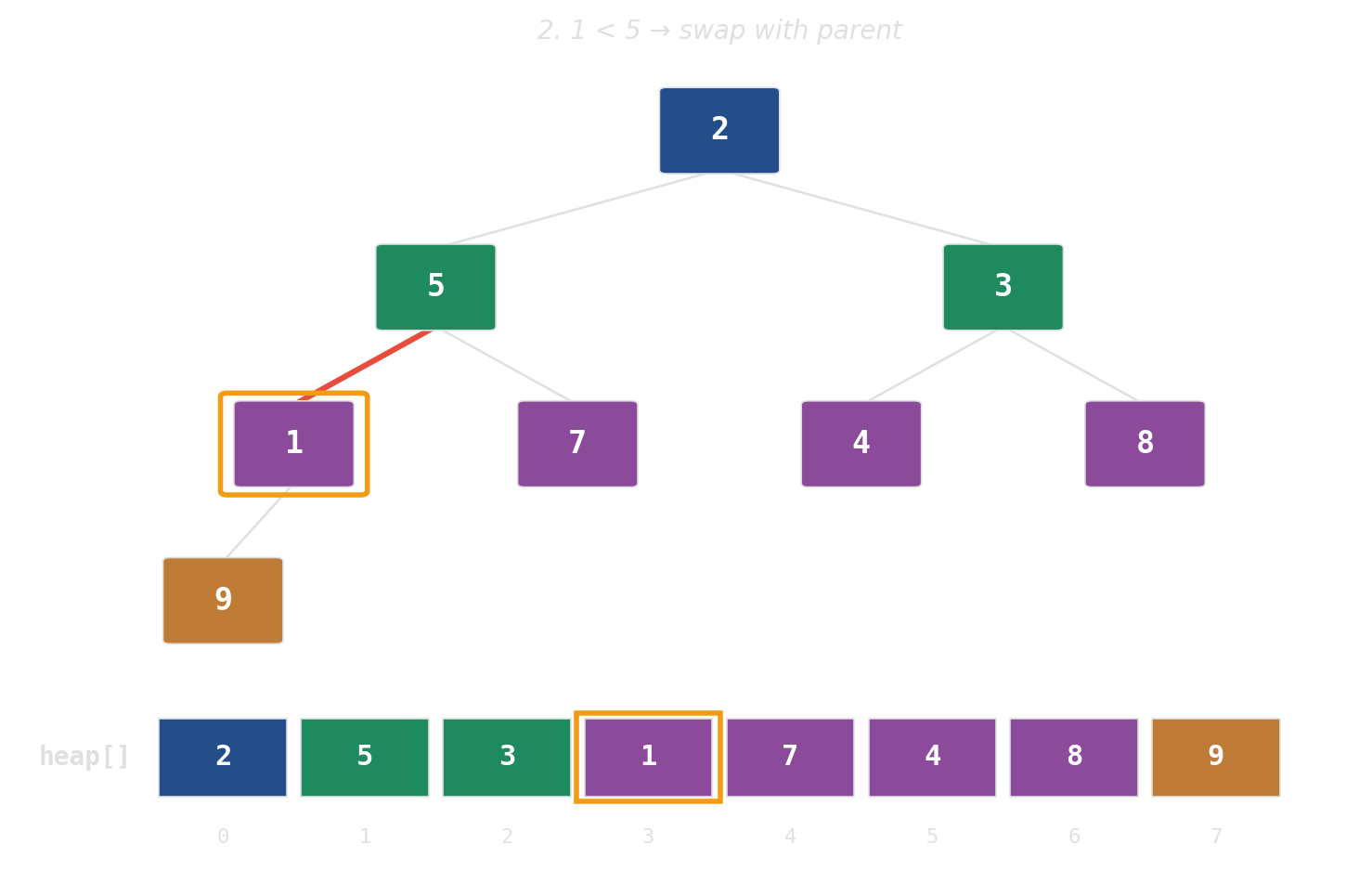
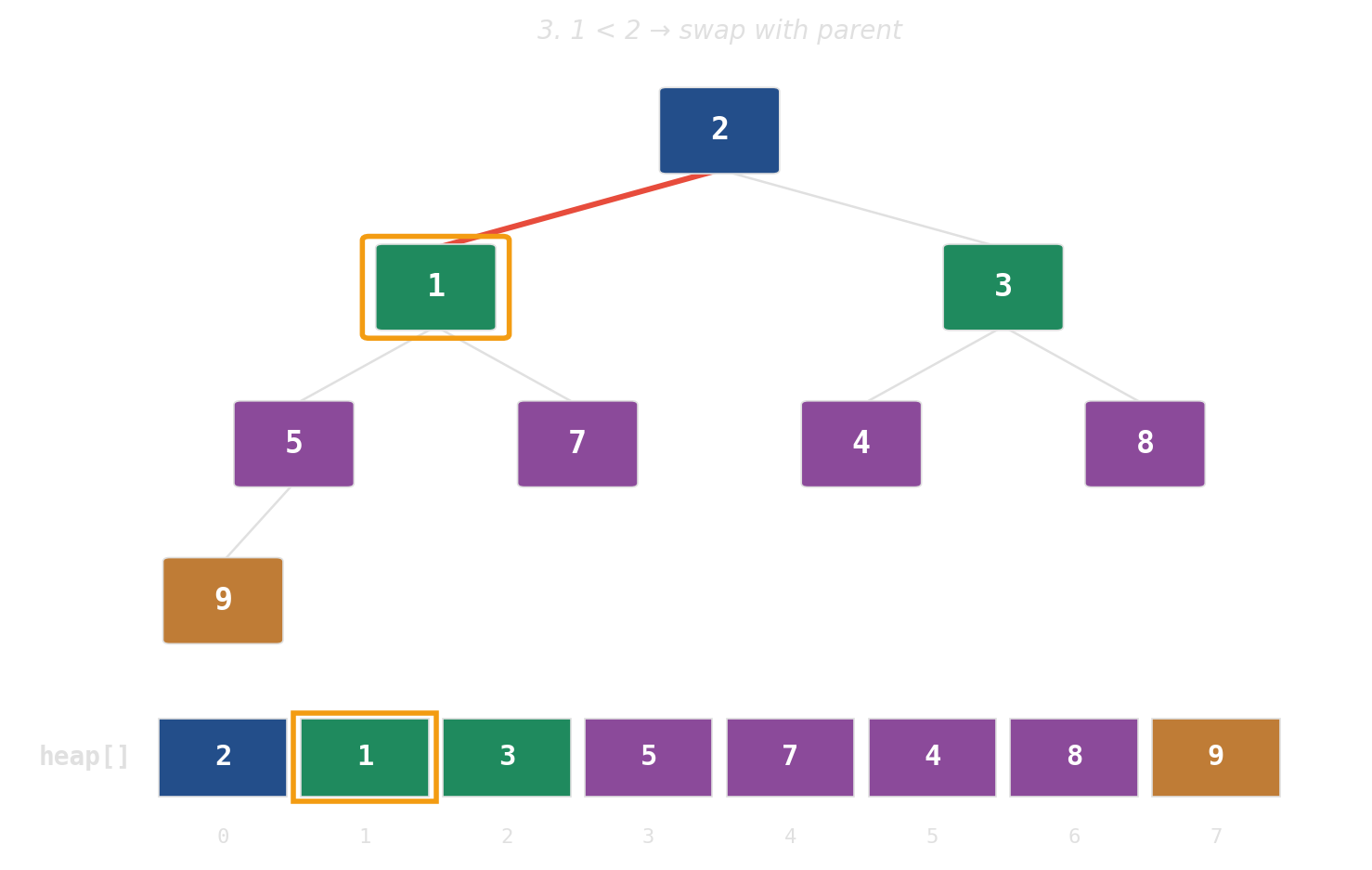
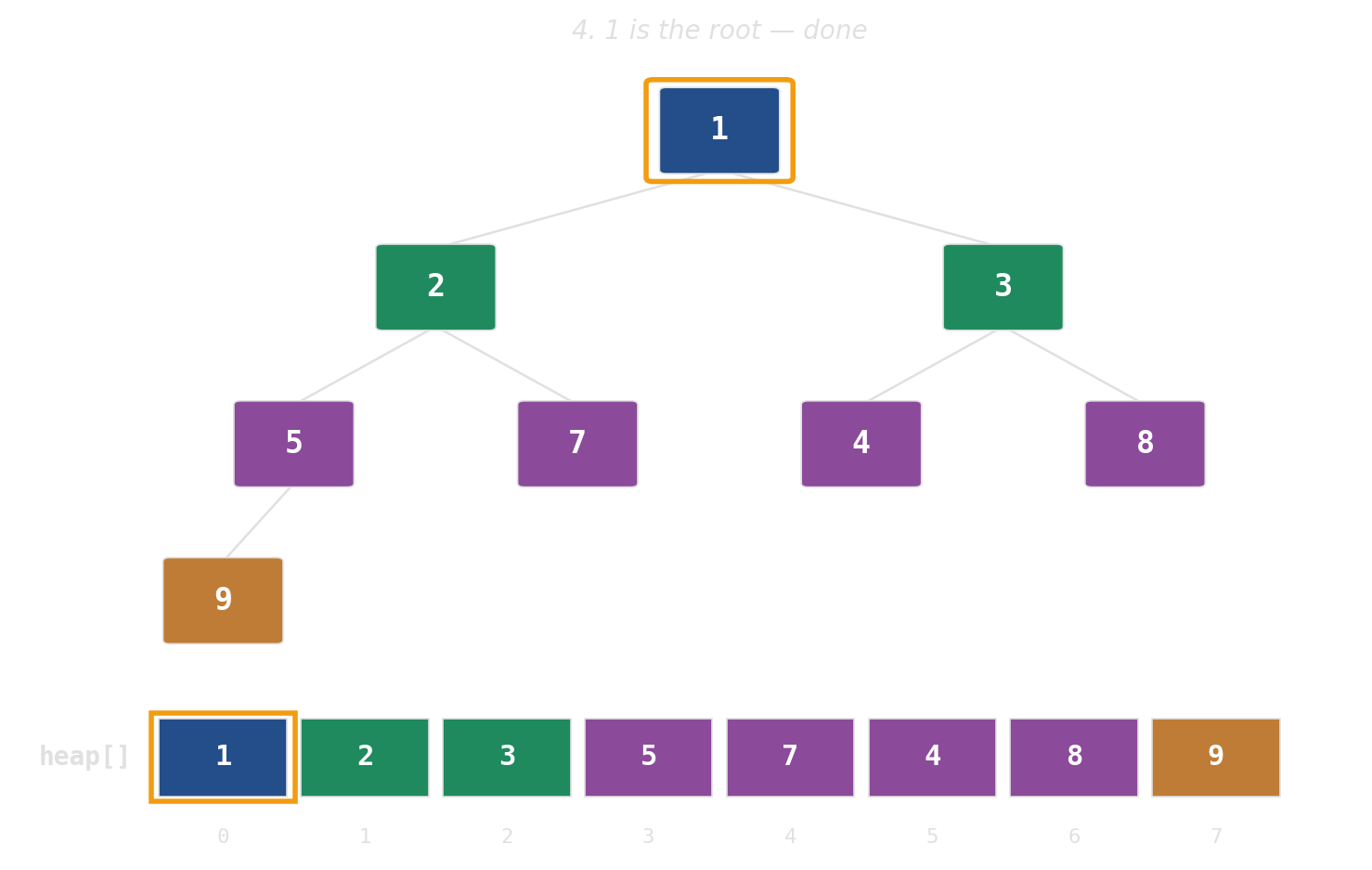
pop: swap root with last, then sift down
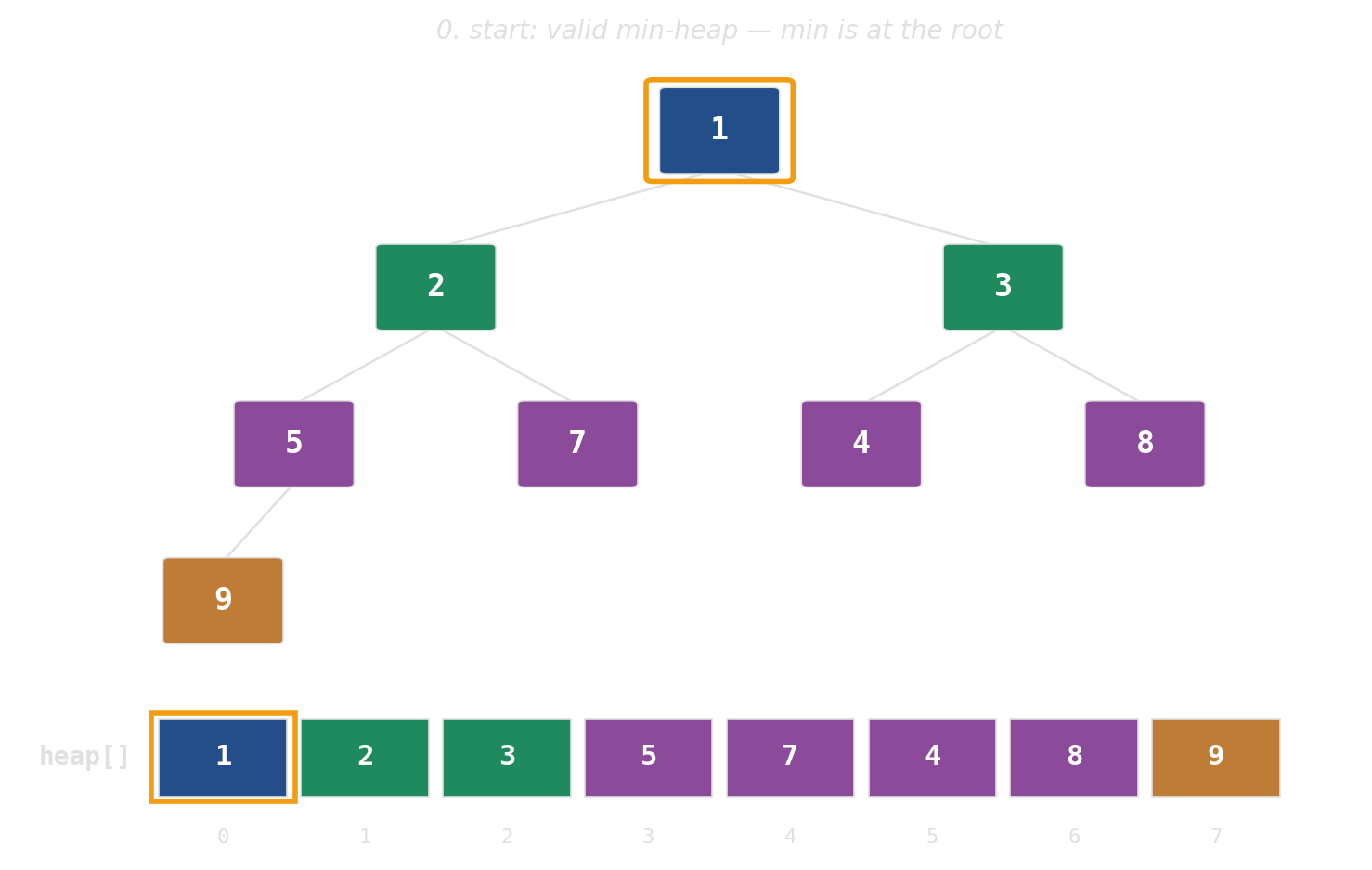
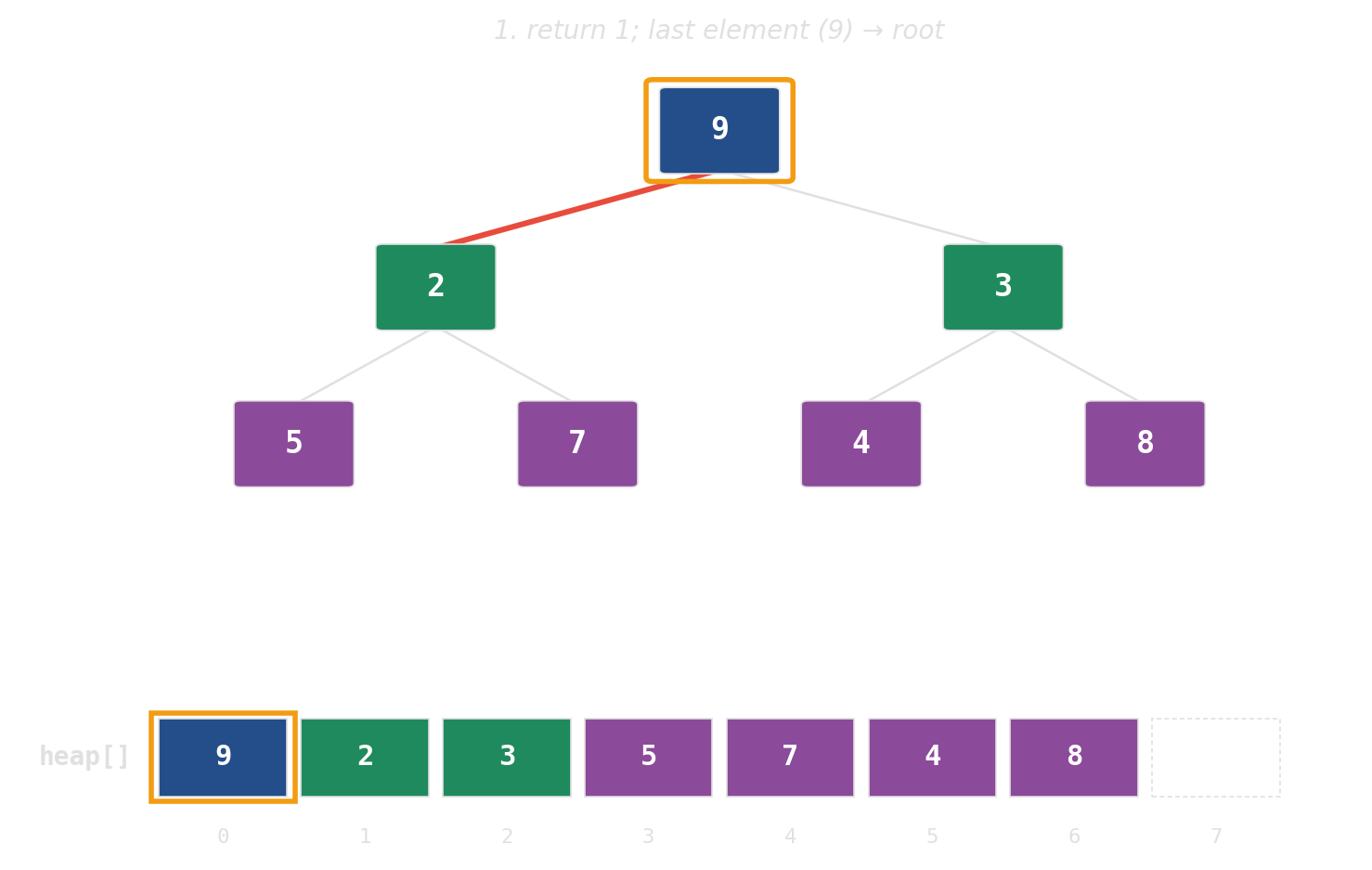
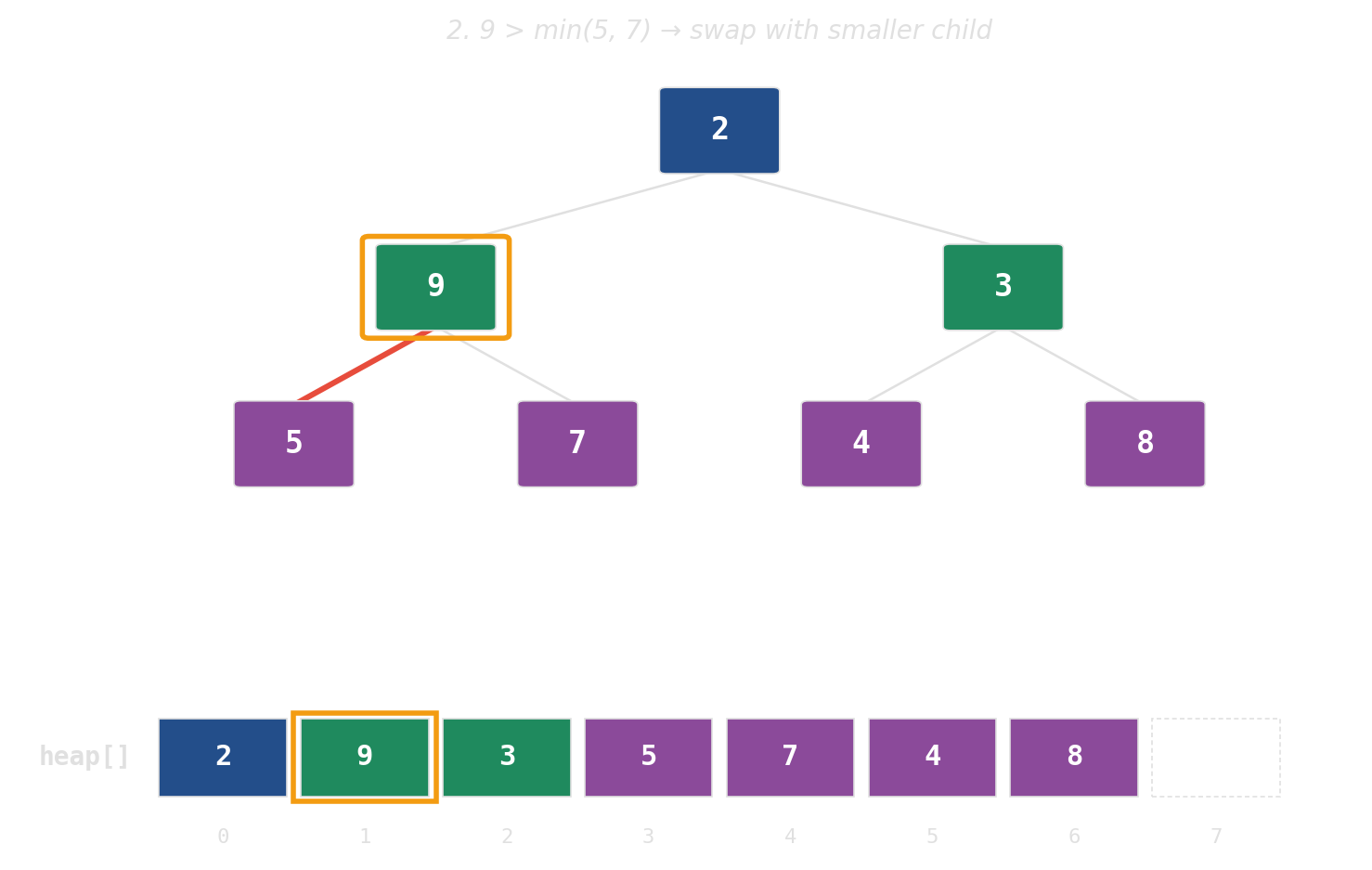
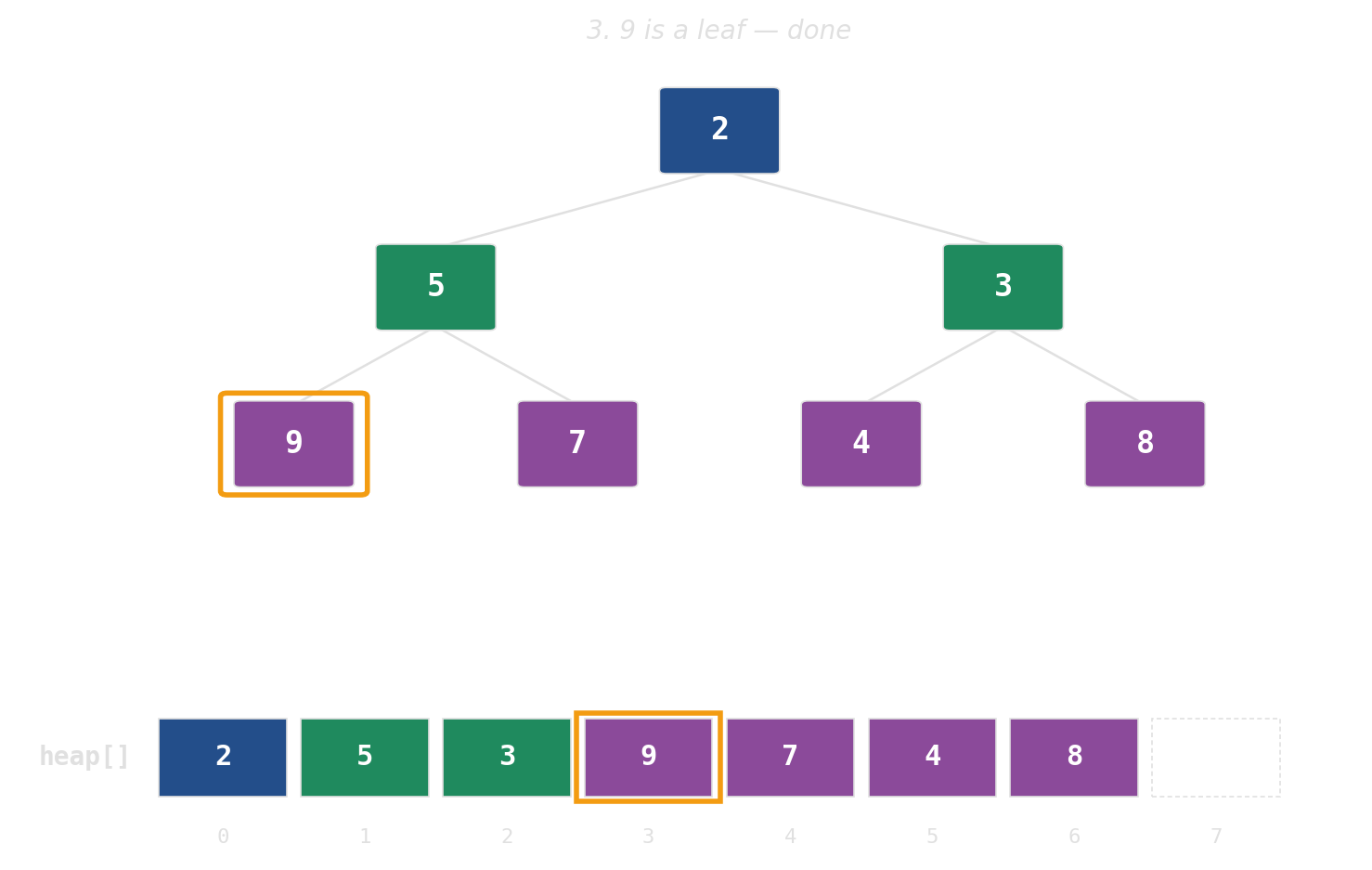
Height is the cost — widen the tree
A binary heap over one million keys is ~20 levels deep. Each level is a potential cache miss per push / pop. Widen the tree, shrink the height.
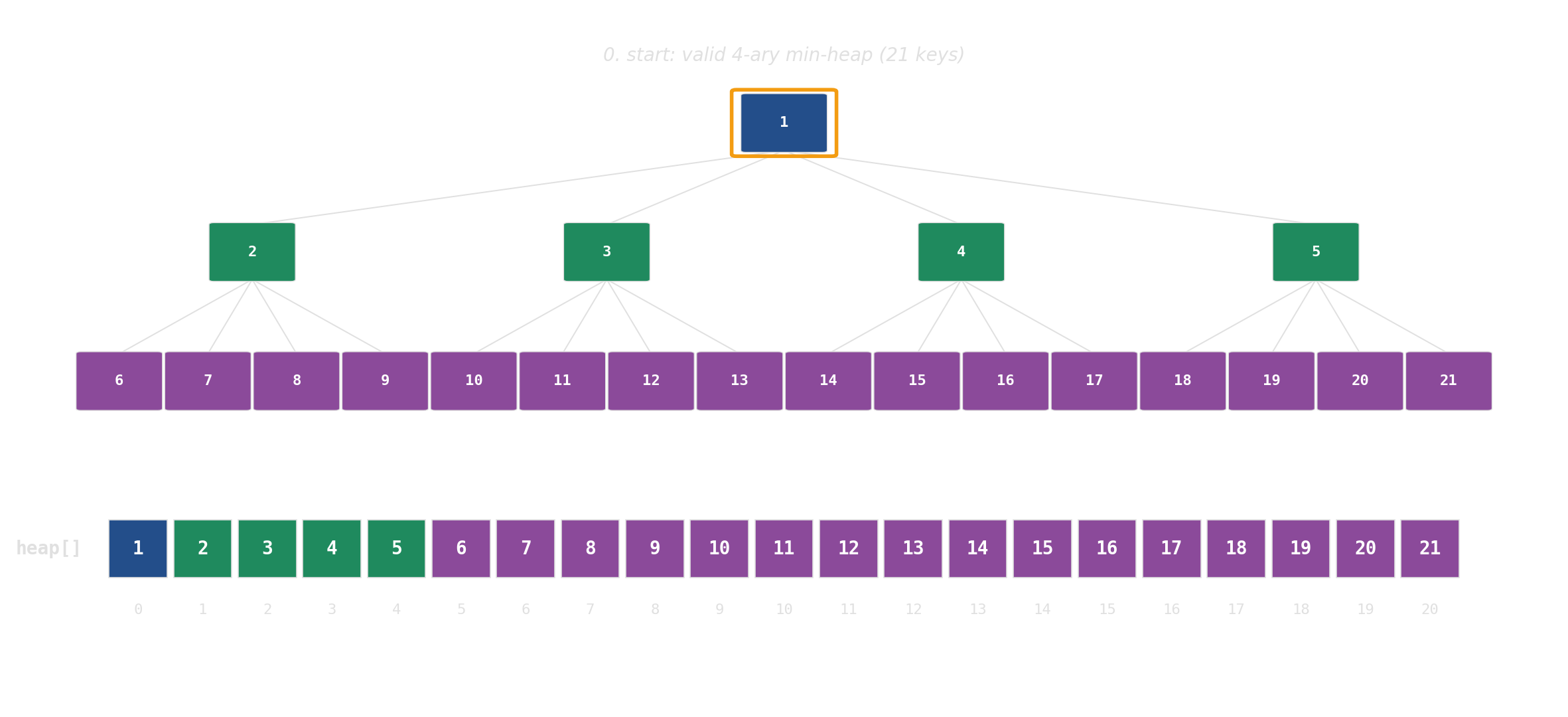
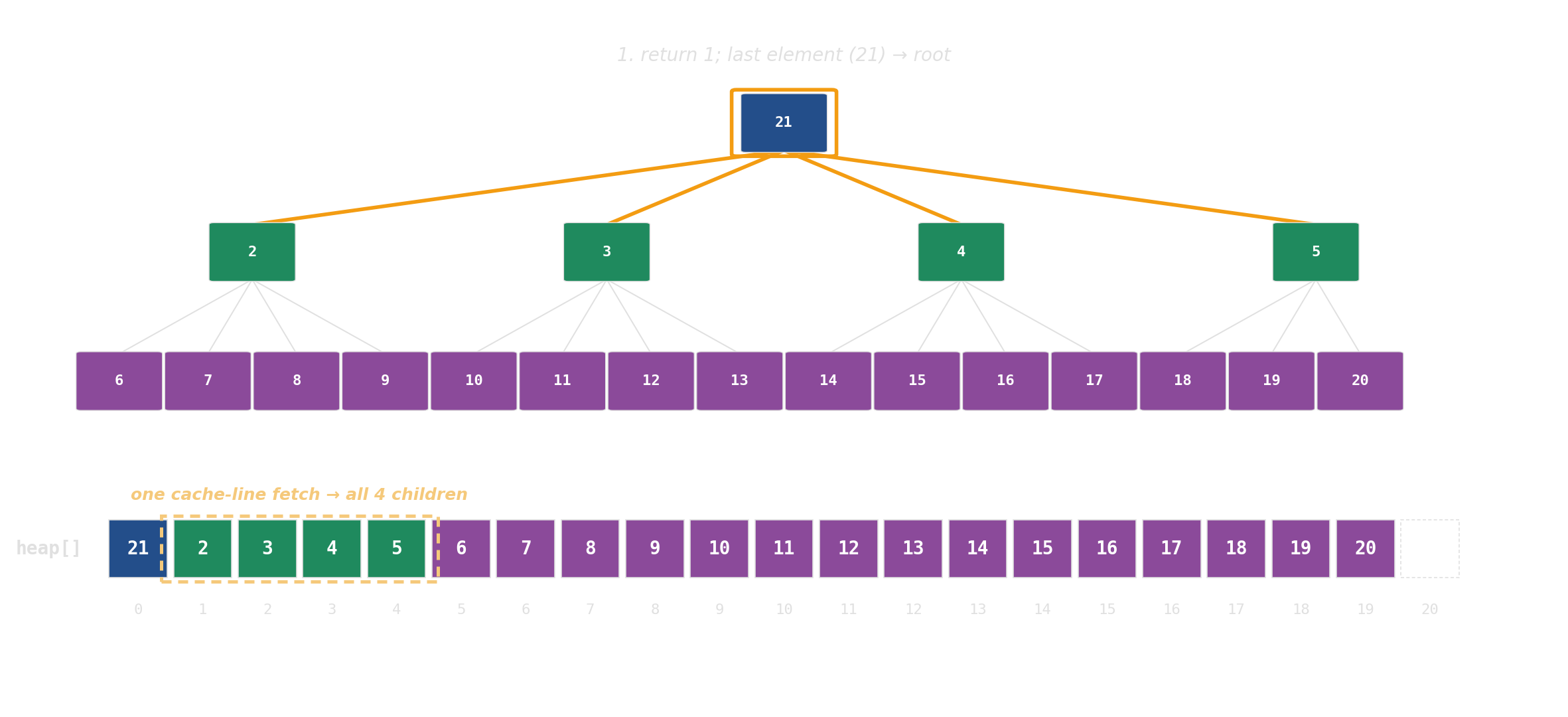
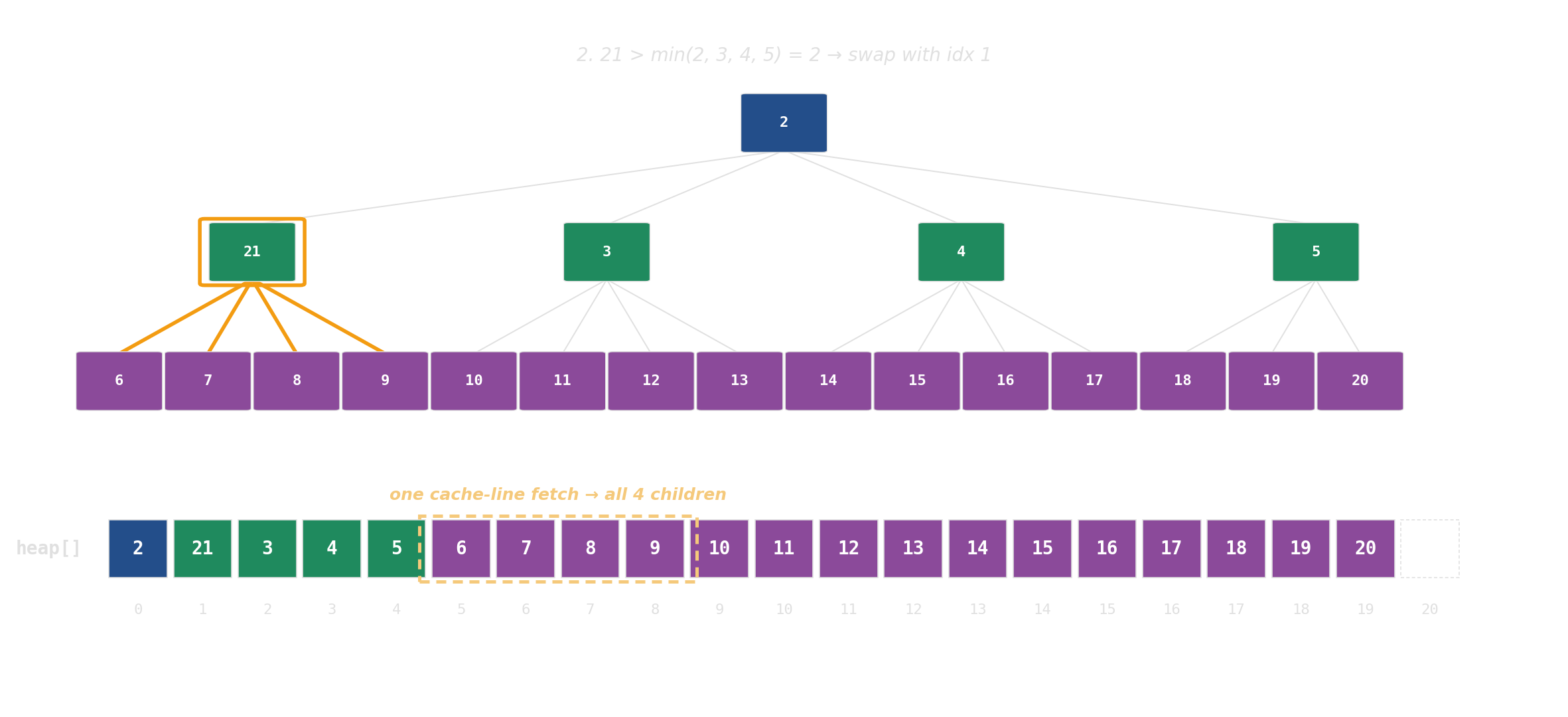
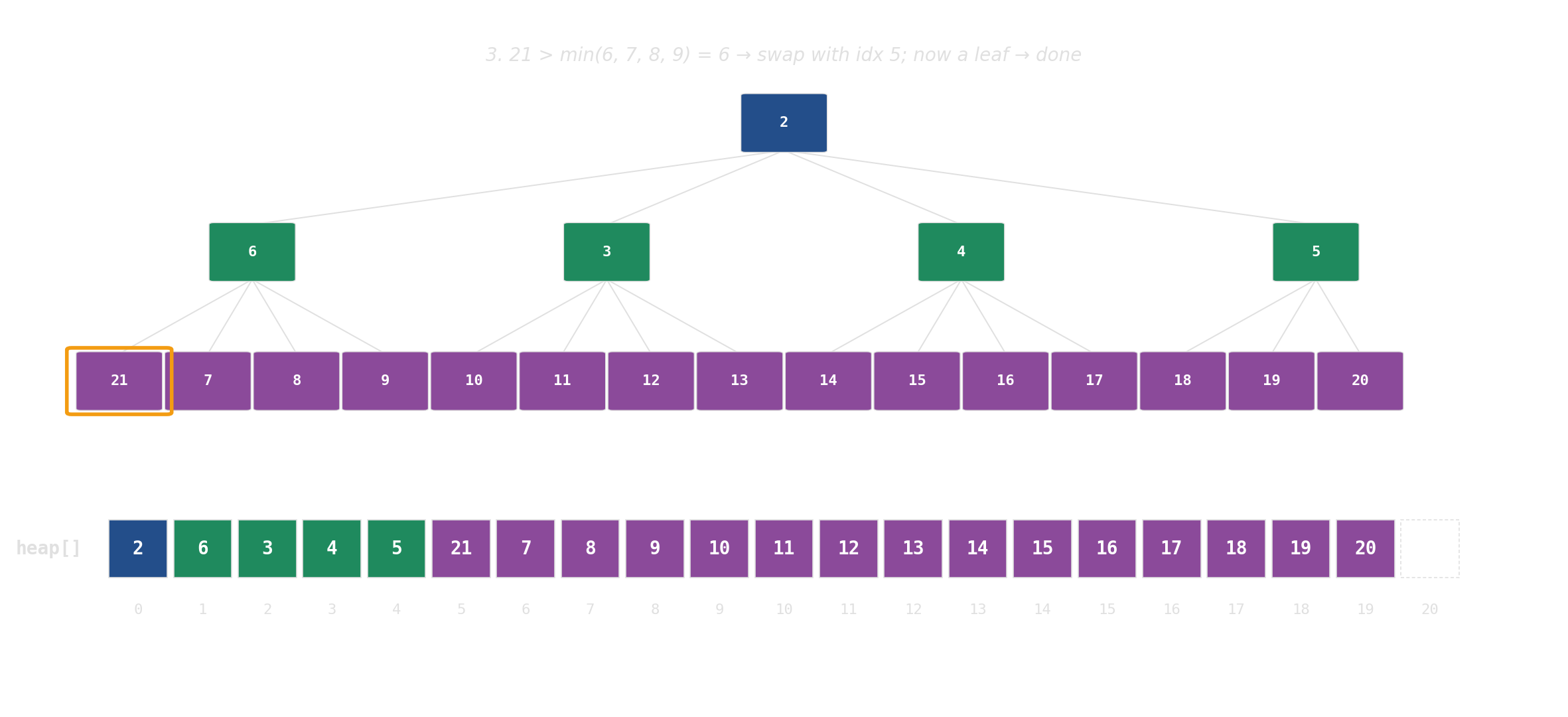
d-ary heap: each node has d children instead of 2. Same array, same index arithmetic — just d·i + k instead of 2i + 1. The d children sit in one cache line; height drops from log₂ N to log_d N.
Two operations
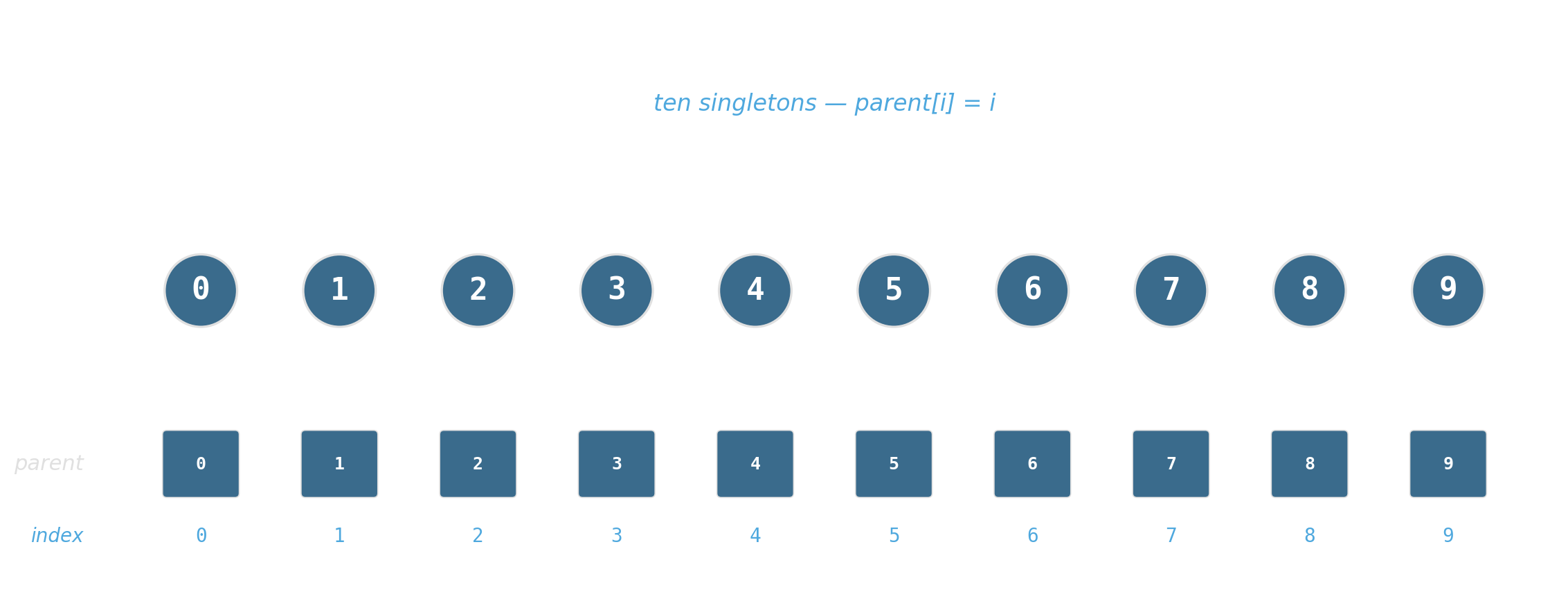
Maintain a partition of {0, …, 7} under:
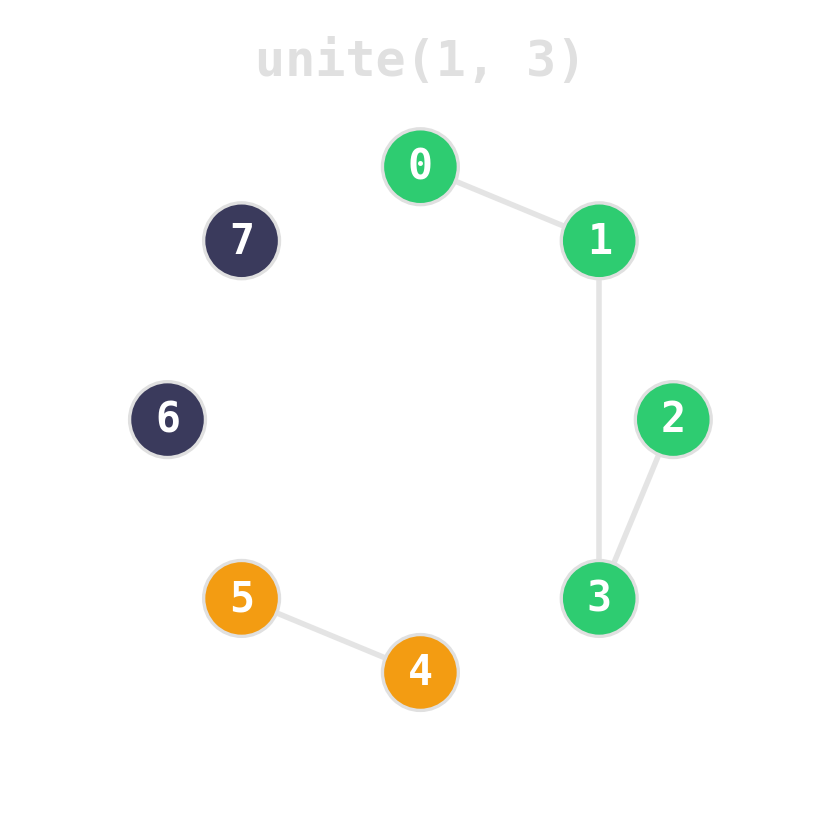
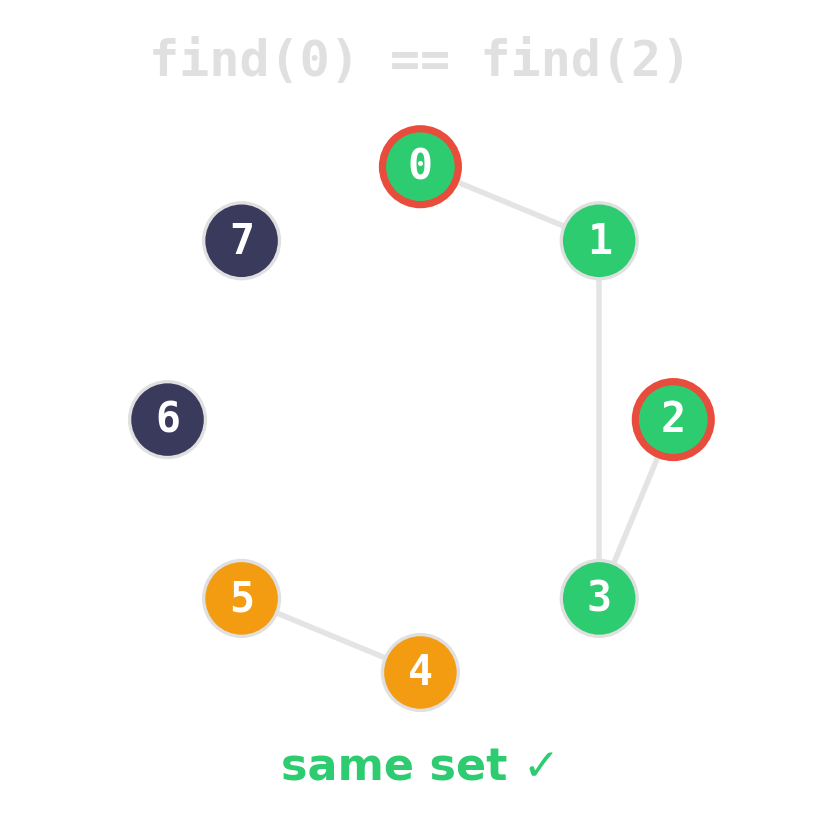
find(x)— which set isxin?unite(x, y)— merge the two sets.

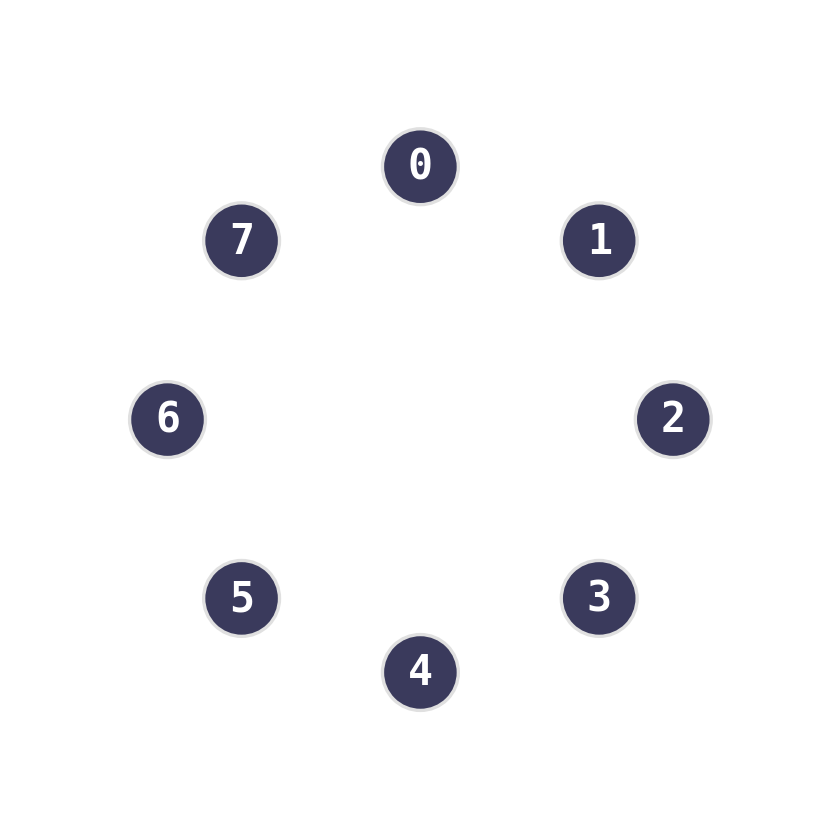
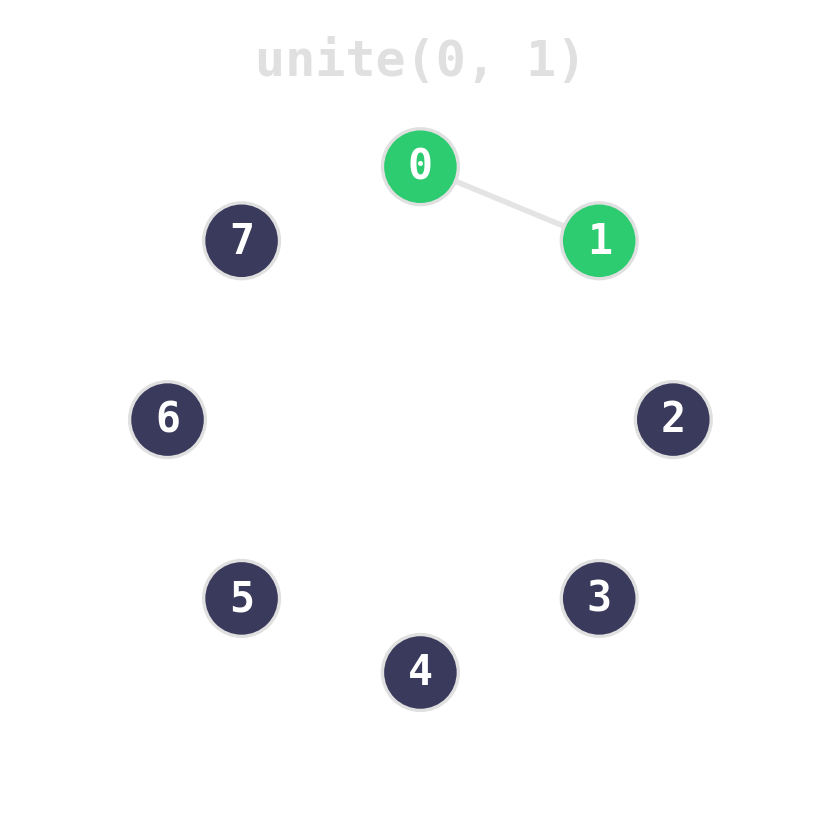
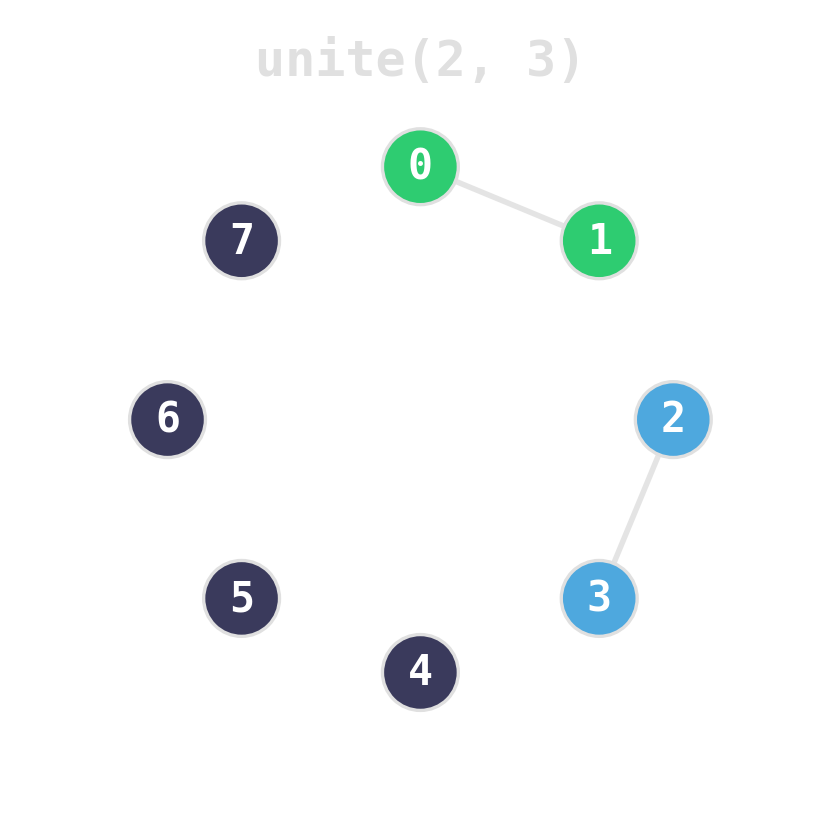
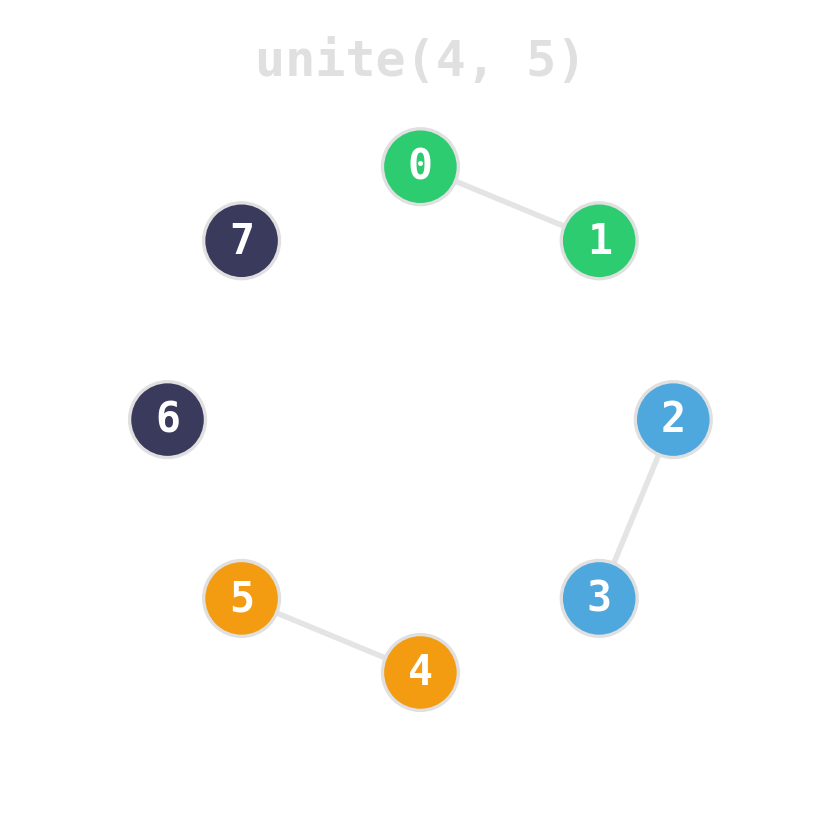
Two ideas, near-constant time
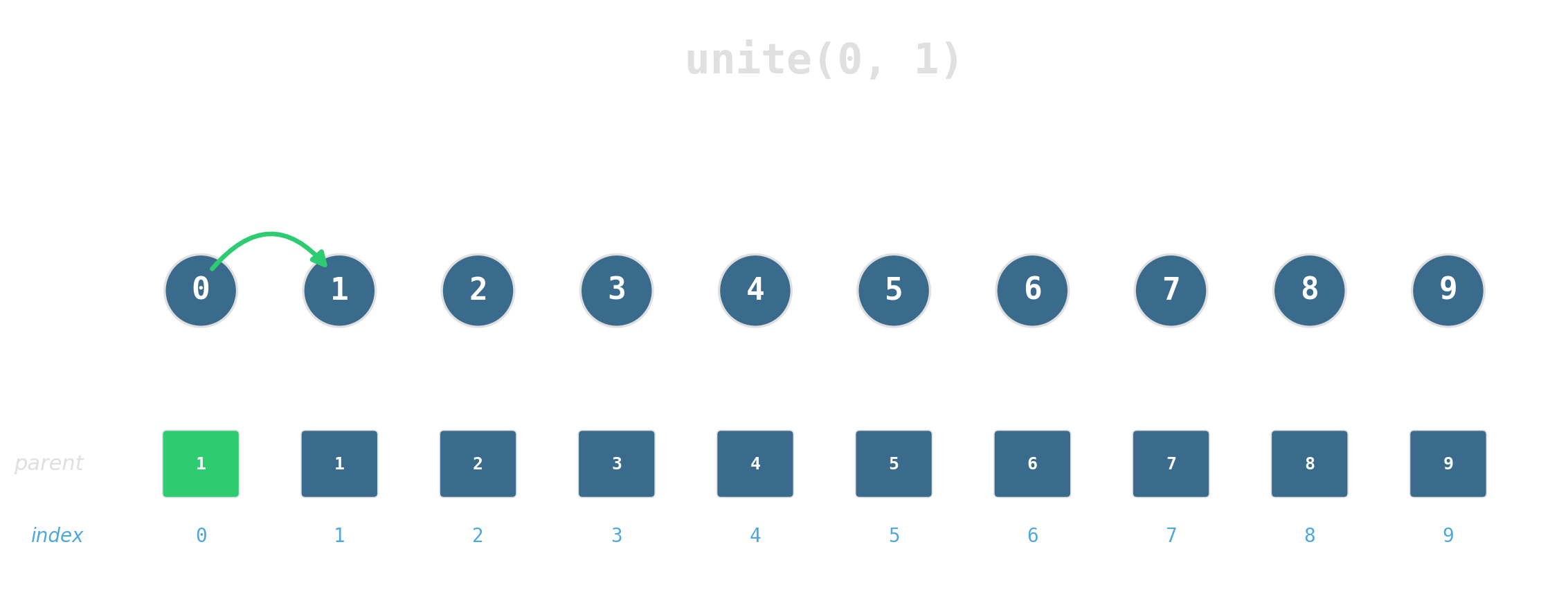
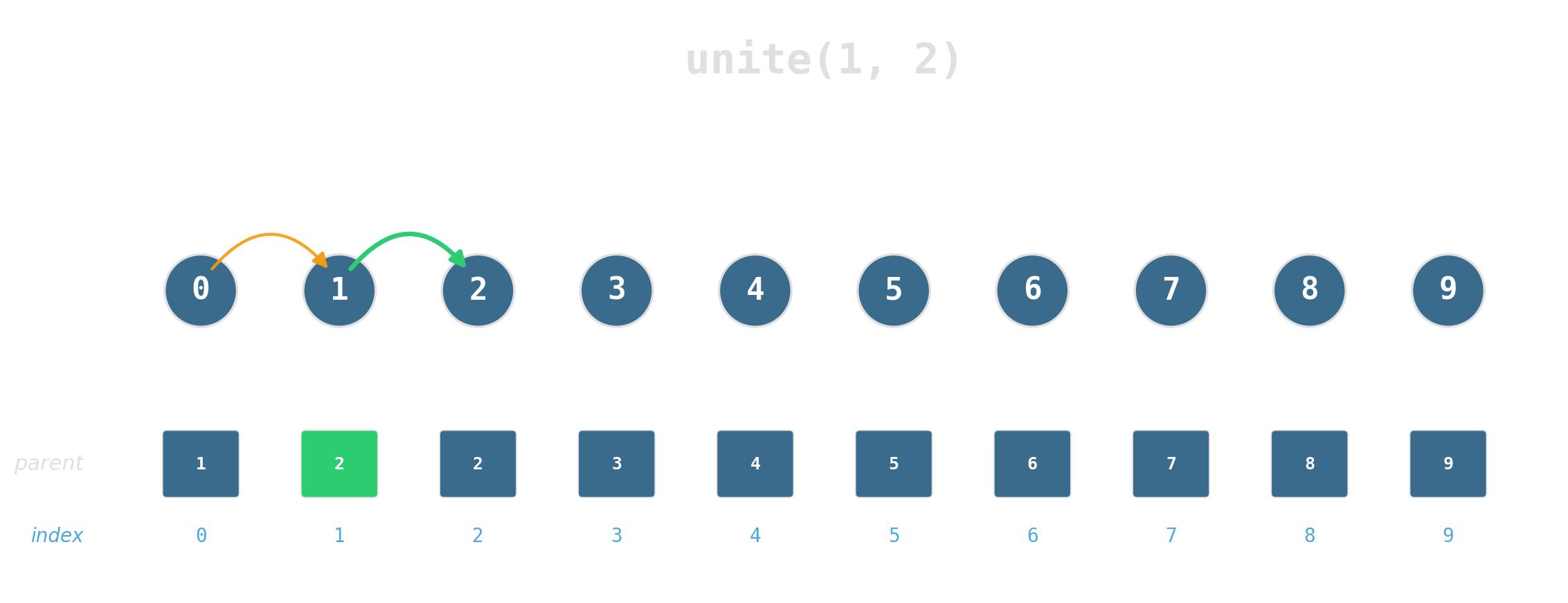
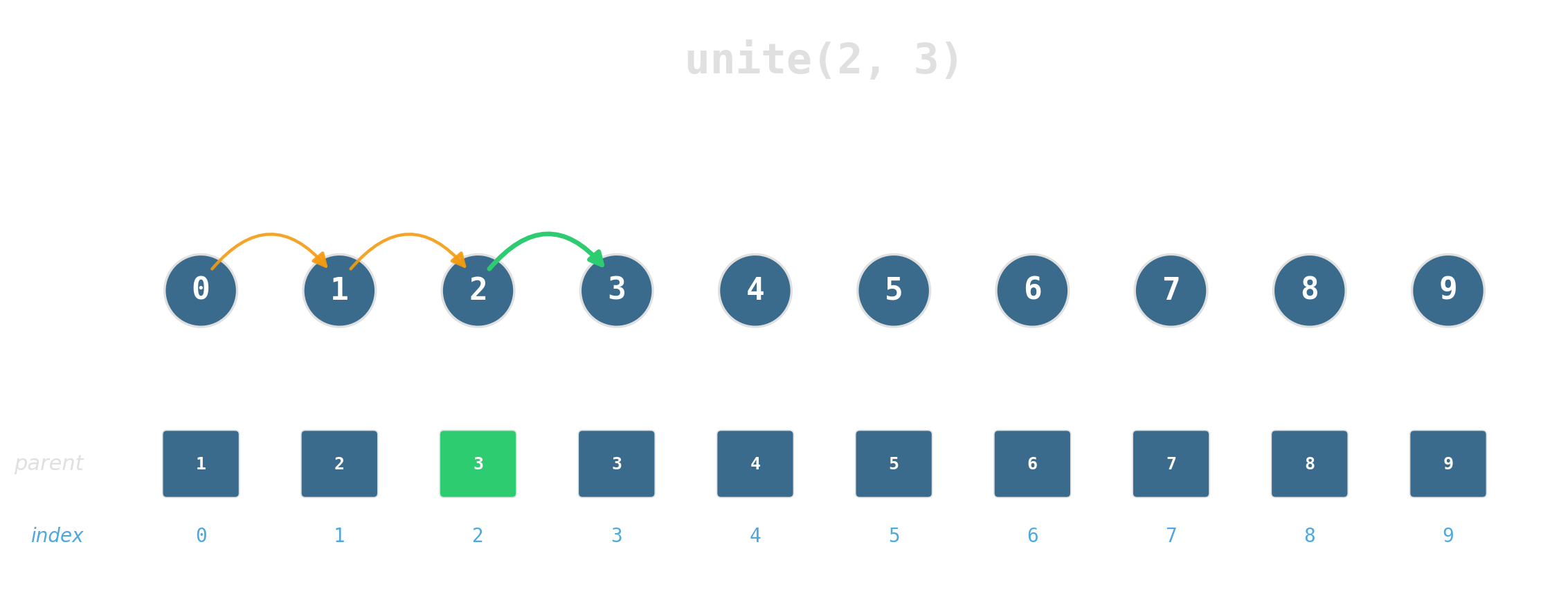
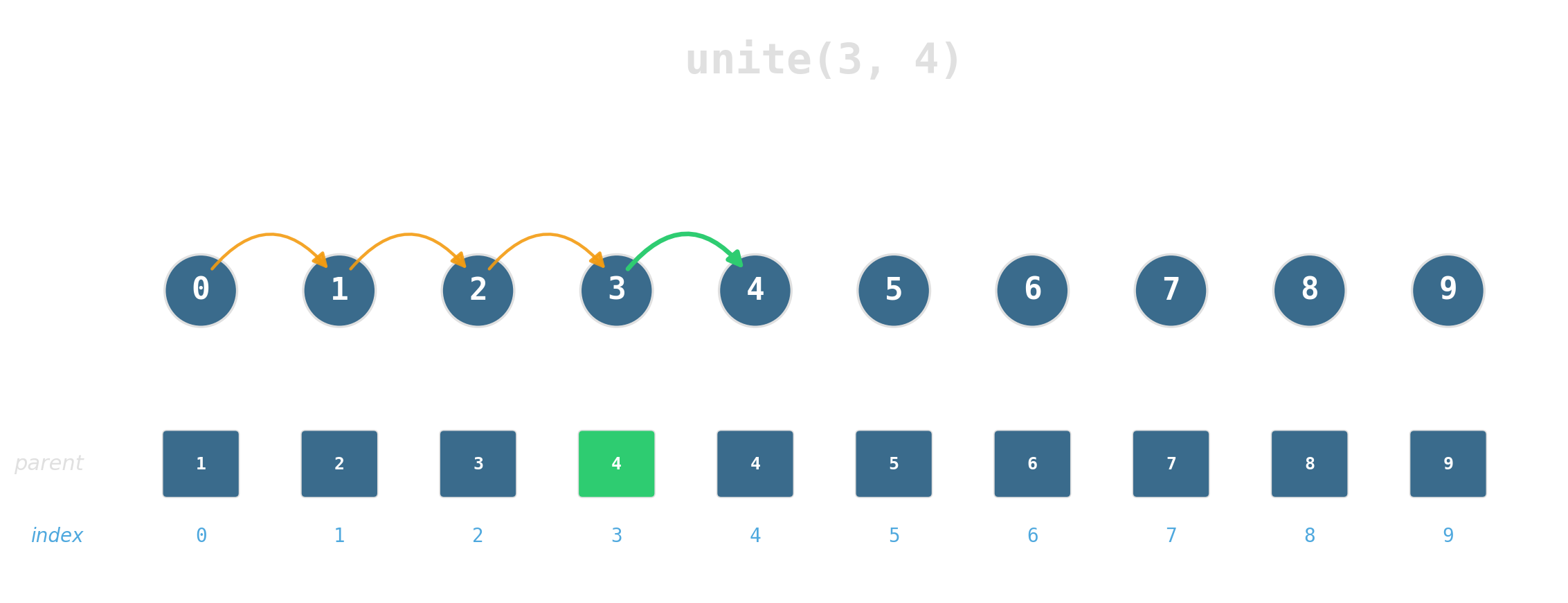
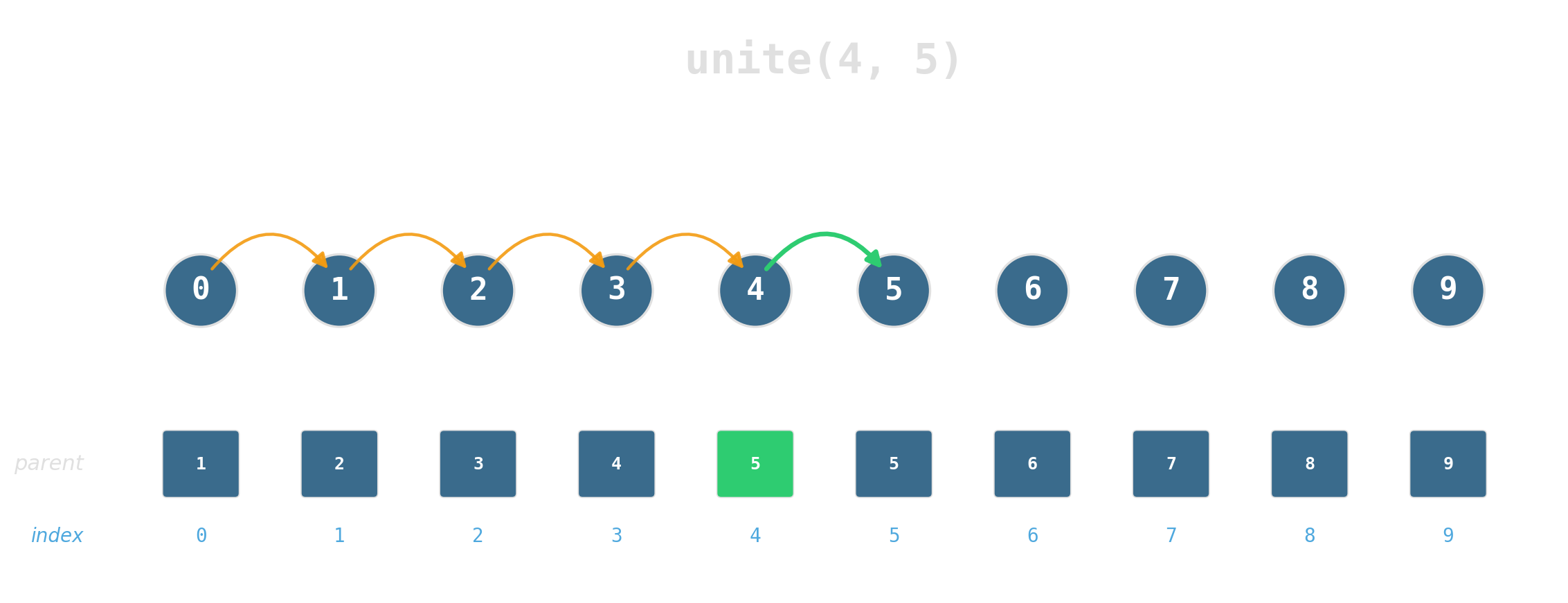
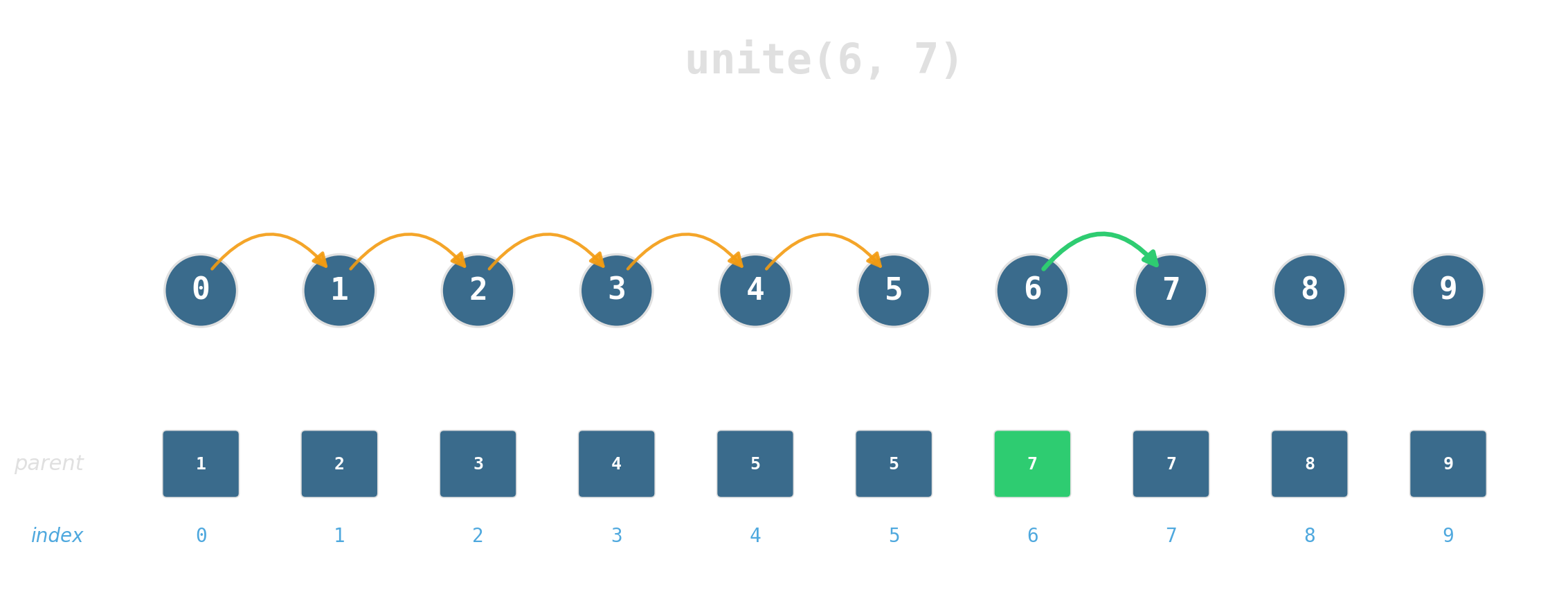
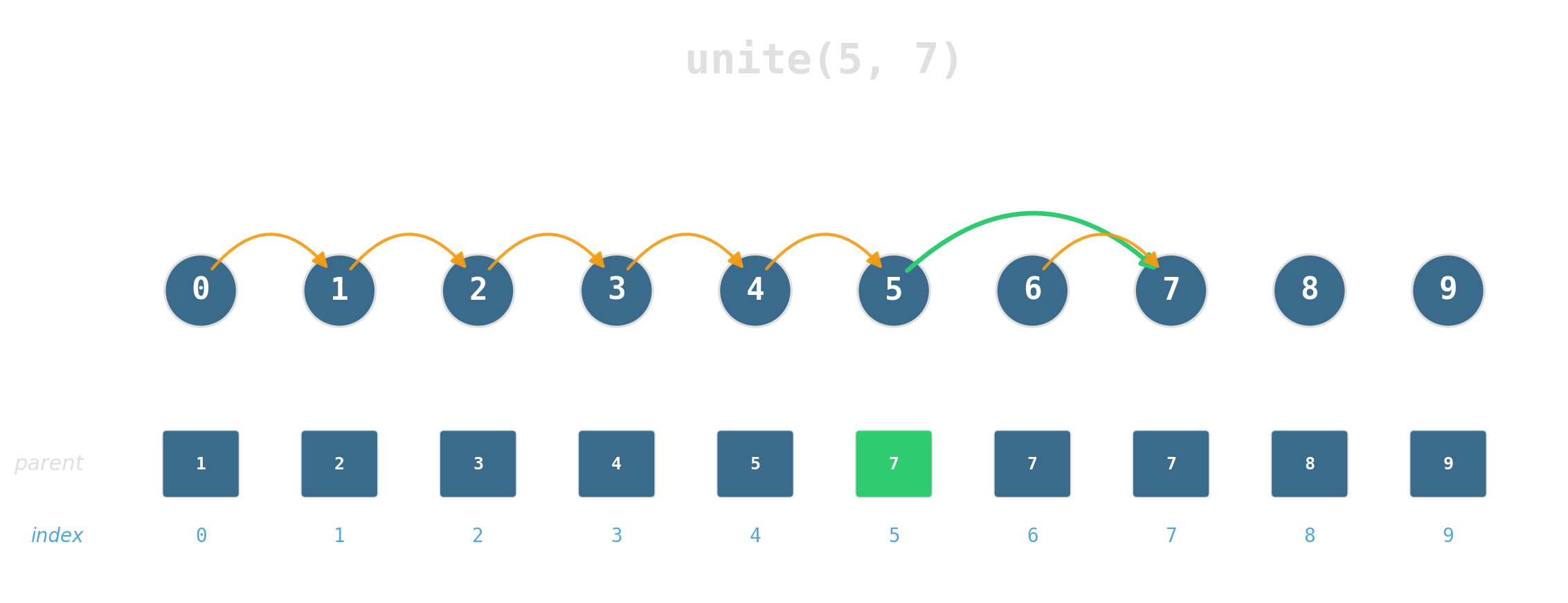
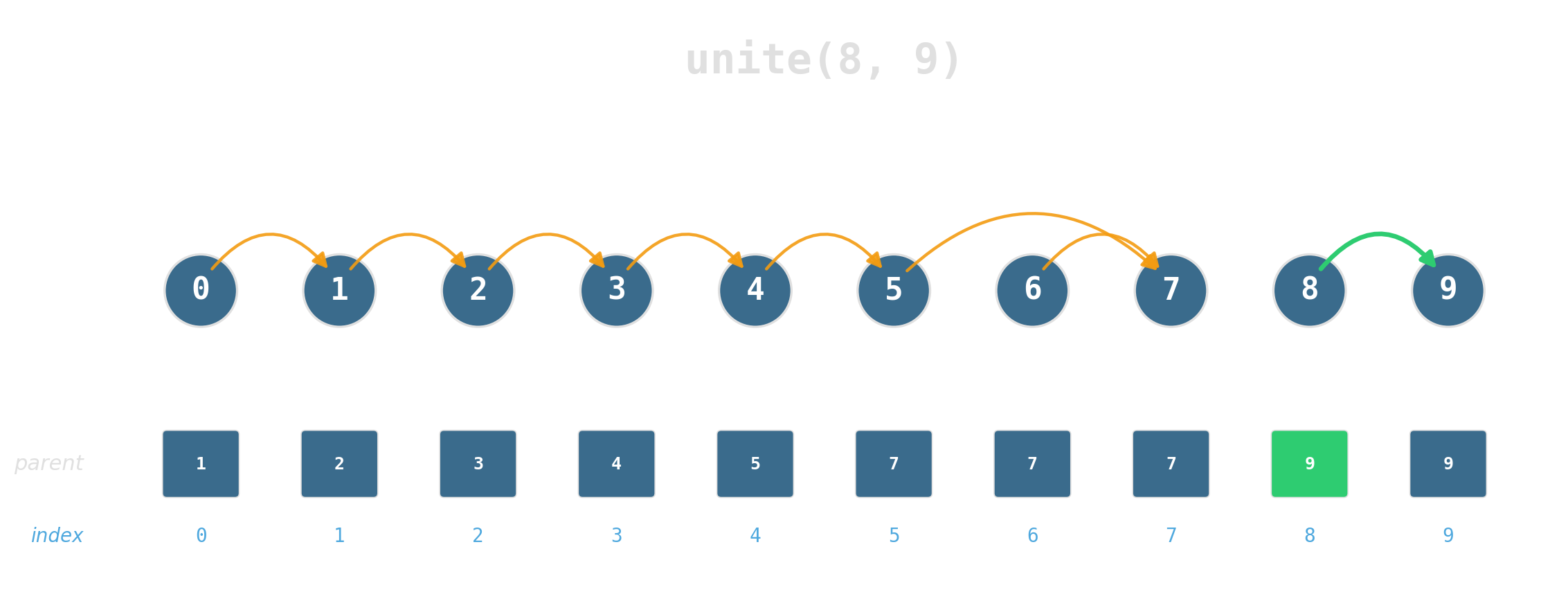
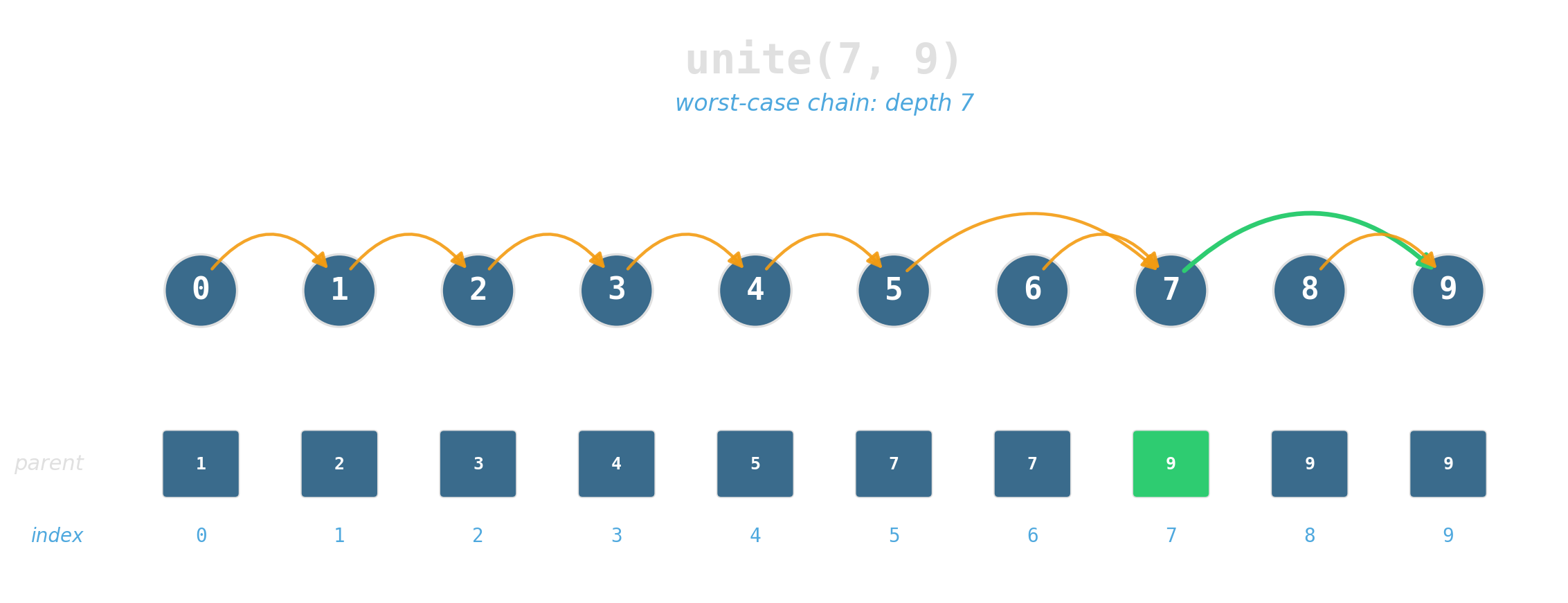
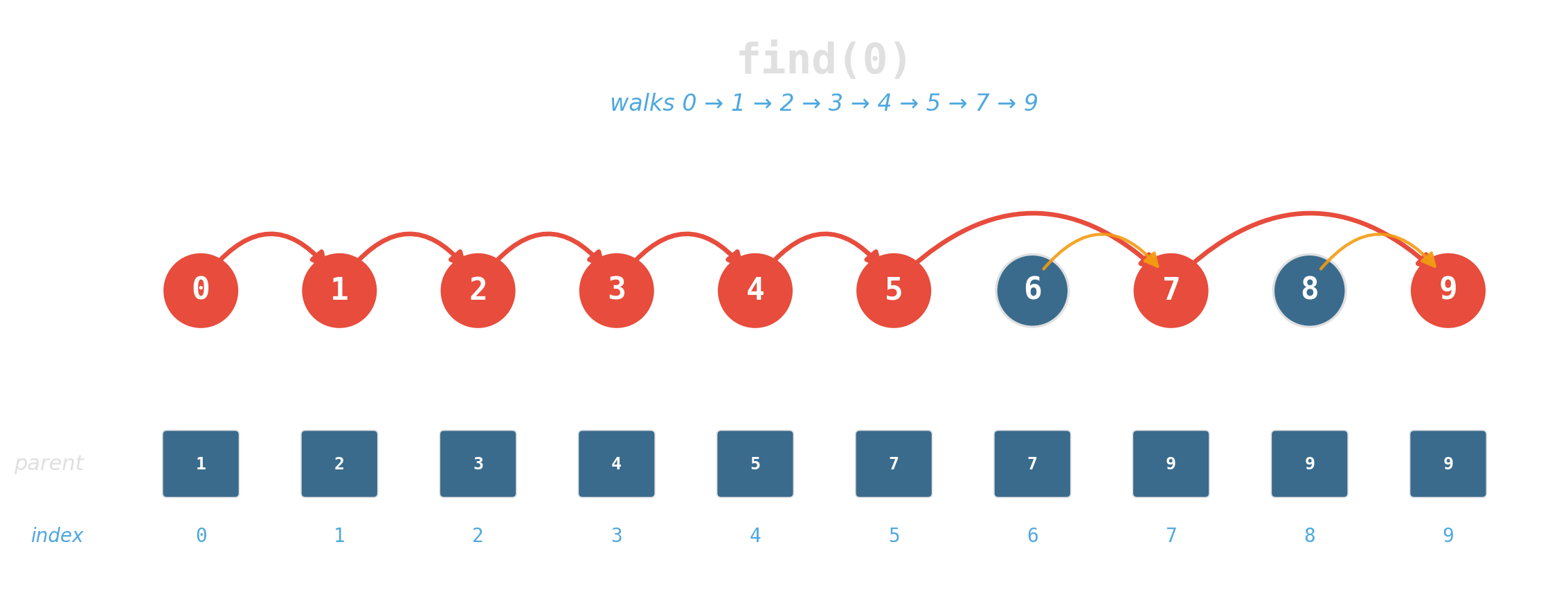
Union by rank: attach the shorter tree under the taller. Tree height stays logarithmic.
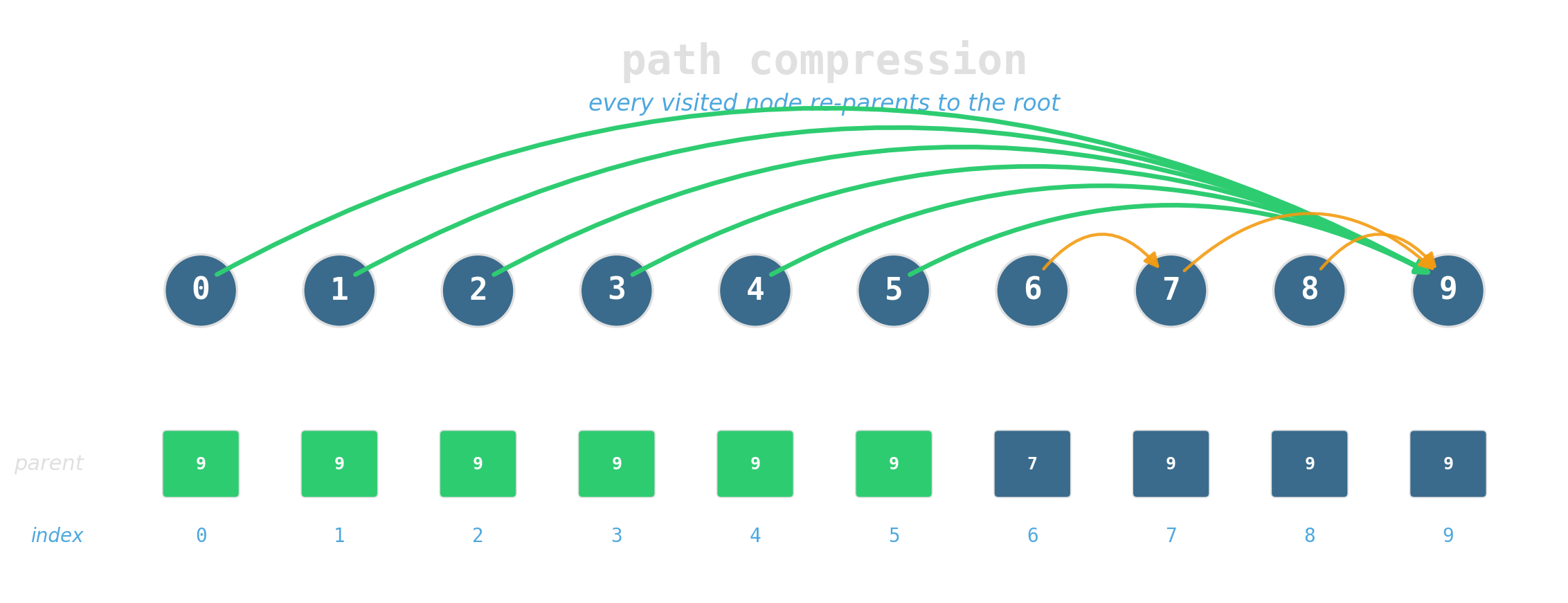
Path compression: during find, re-parent every node on the path directly to the root.
Why graphs matter
Graphs are arguably the dominant abstraction of combinatorial optimization.
They model concrete entities — people in a social network, intersections in a street network, machines on a factory floor.
…but just as naturally abstract ones — states of a system and the transitions between them, configurations of a puzzle, positions in a game.
Once a problem wears this shape, a huge library of algorithms becomes available. The rest of this chapter is about making those algorithms run fast on real hardware.
Compressed Sparse Row — two flat arrays
std::vector<std::vector<int>> places each vertex’s neighbors in a separate heap allocation: one cache miss per vertex before reading a single edge.

CSR is to graphs what std::vector is to linear structures — the default unless you have a specific reason otherwise.
Adjacency matrix — when the graph is dense
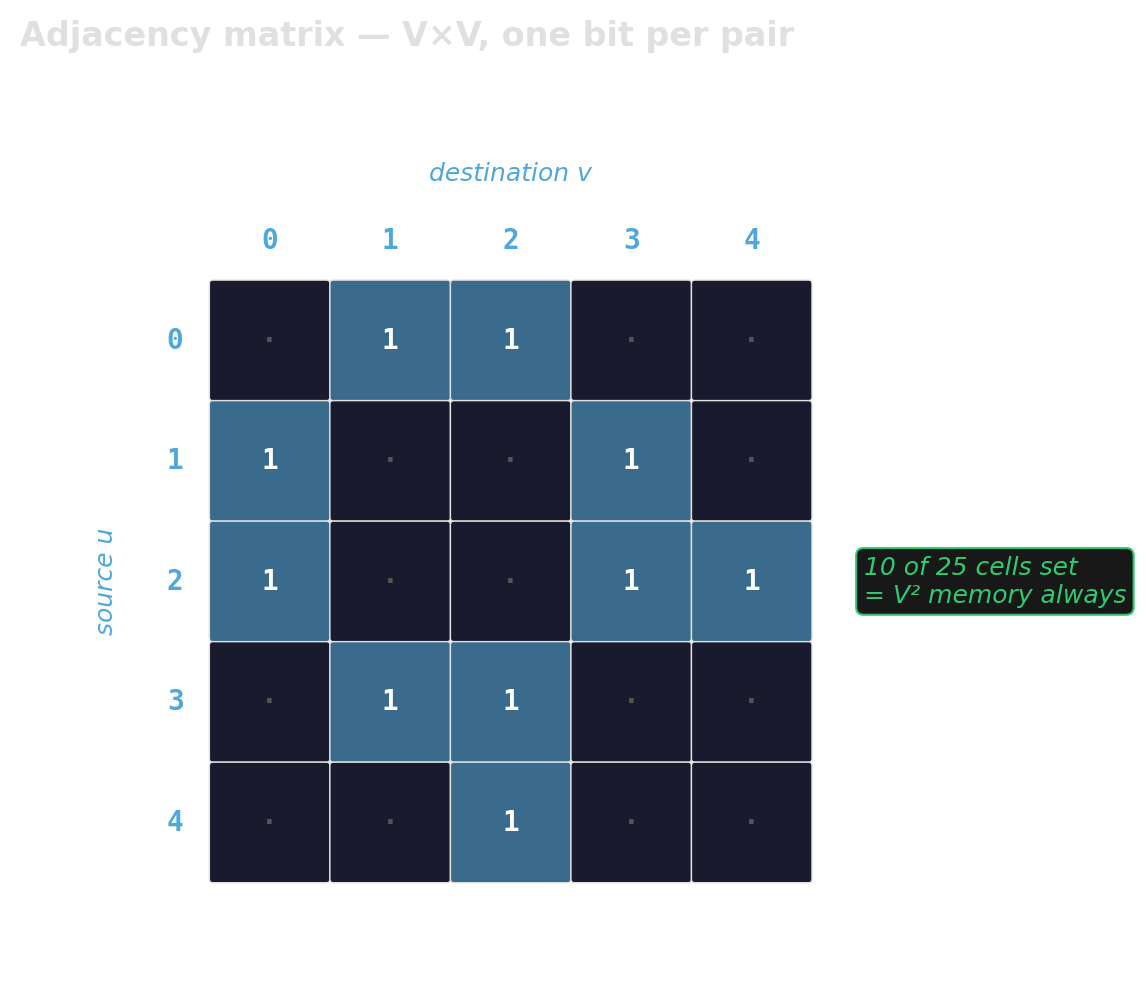
Right for small V with a dense graph, when edge-existence queries dominate, or when the algorithm is expressed as linear algebra (SpMV, matrix powers, GraphBLAS).
Bonus: the matrix is an algorithm
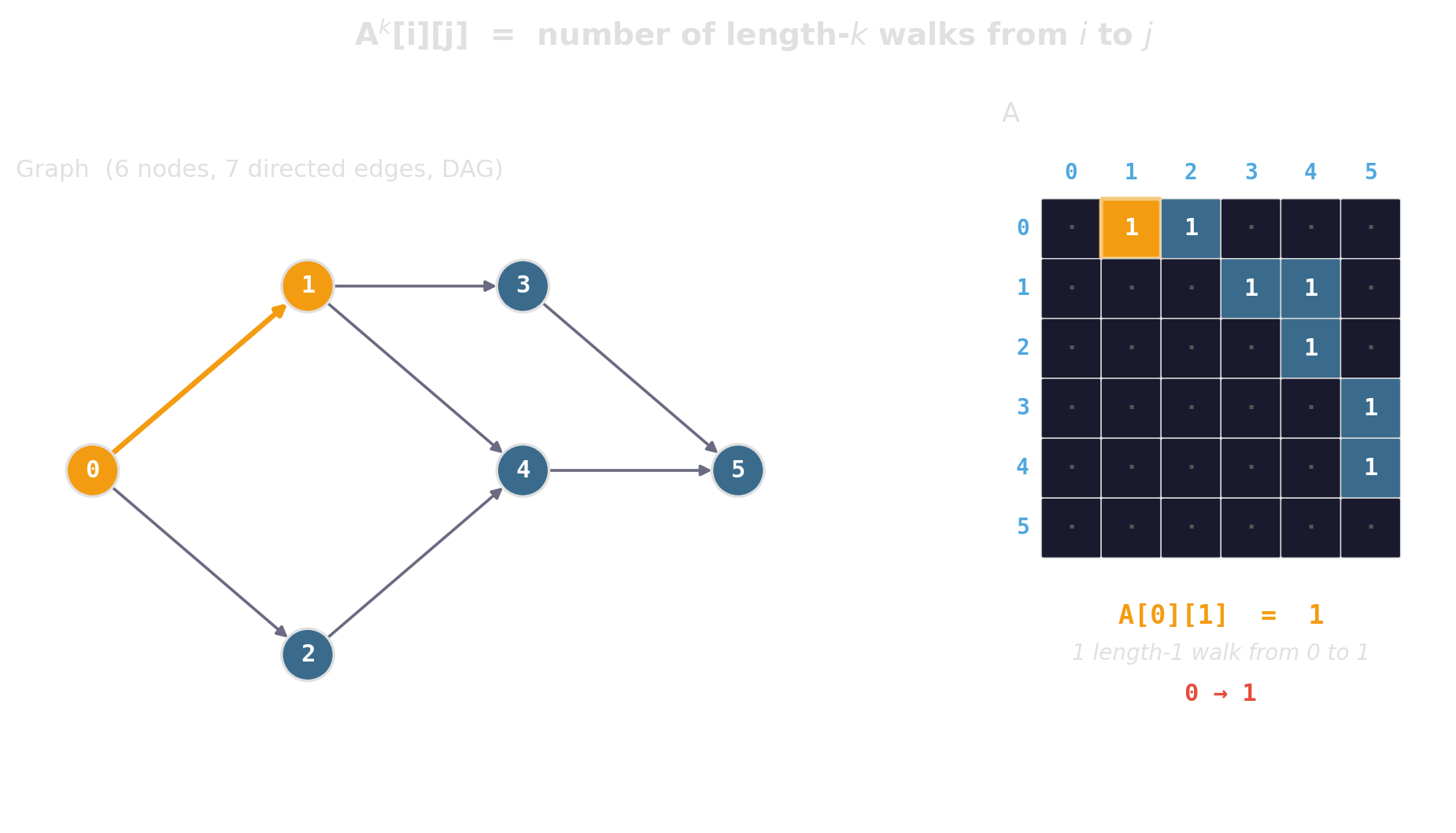
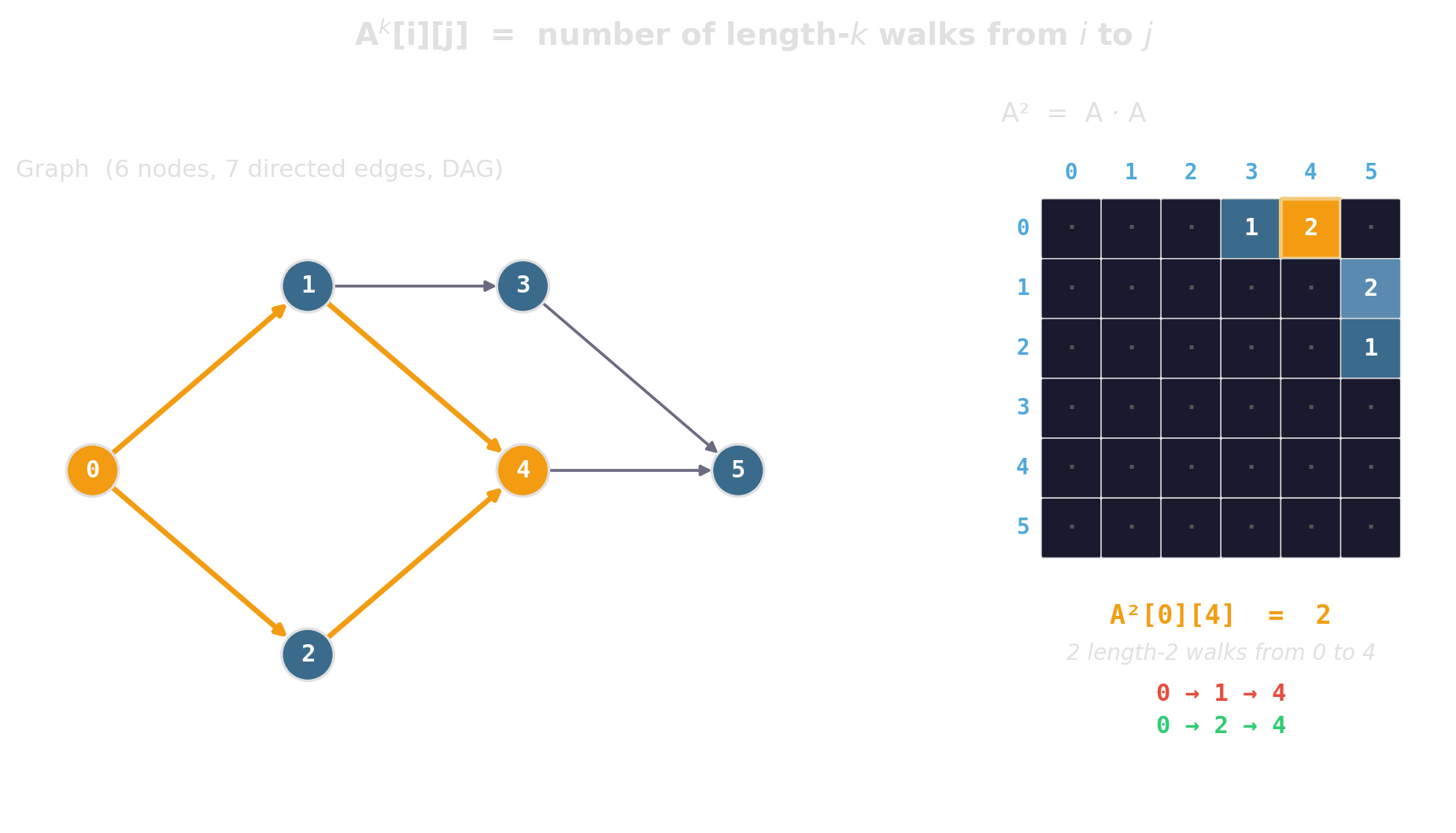
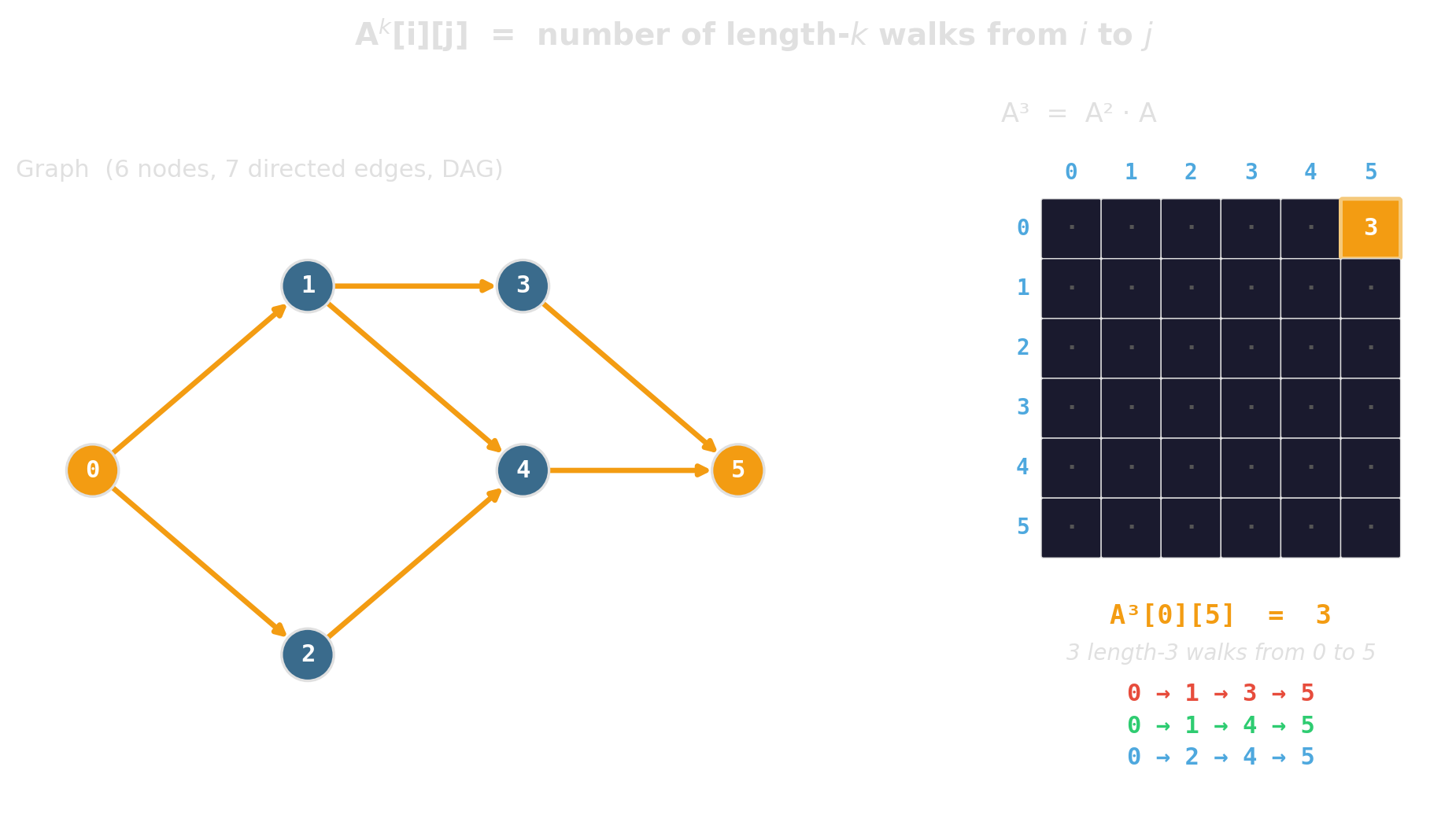
Uniform grid — the boring, often-winning baseline


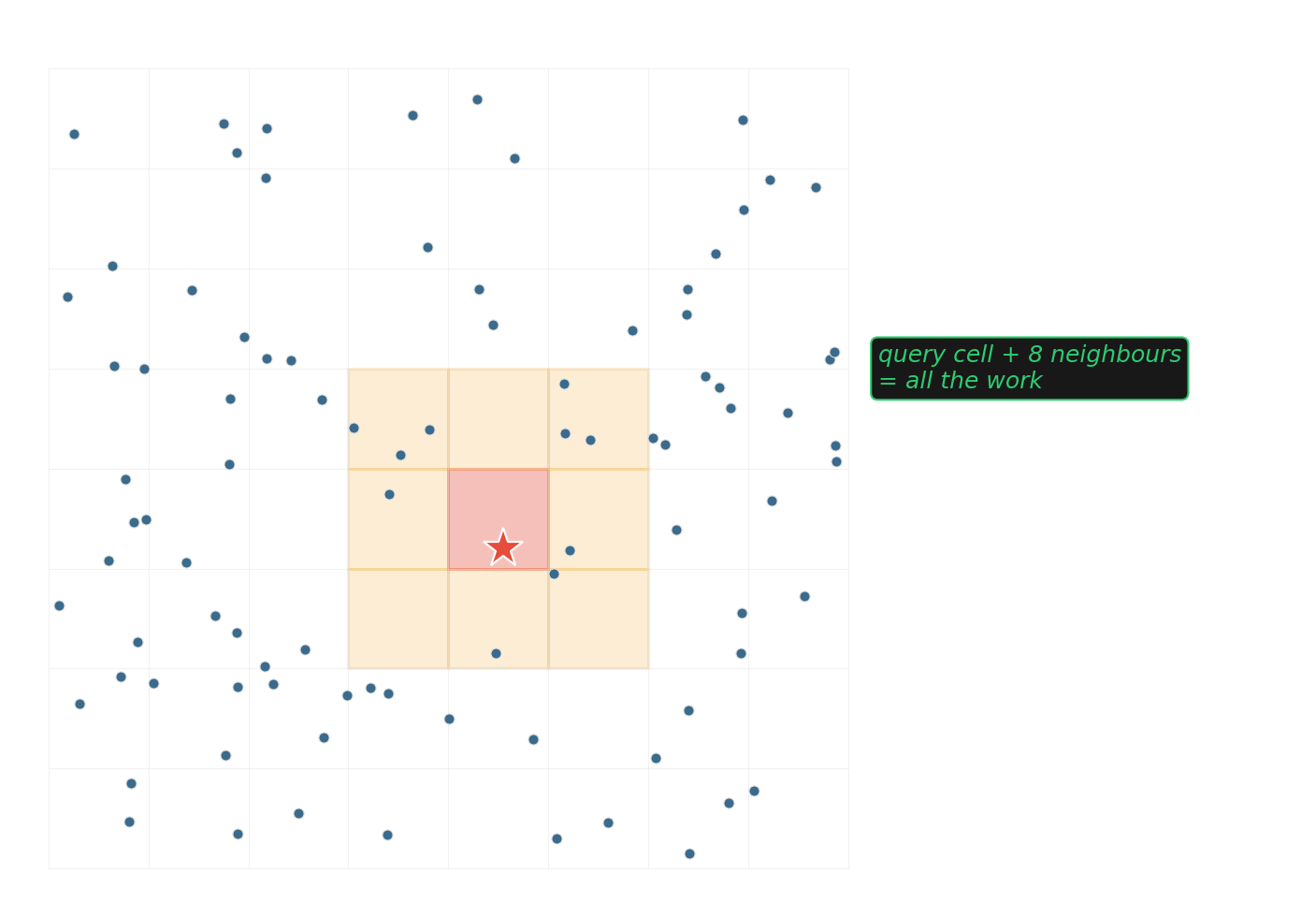
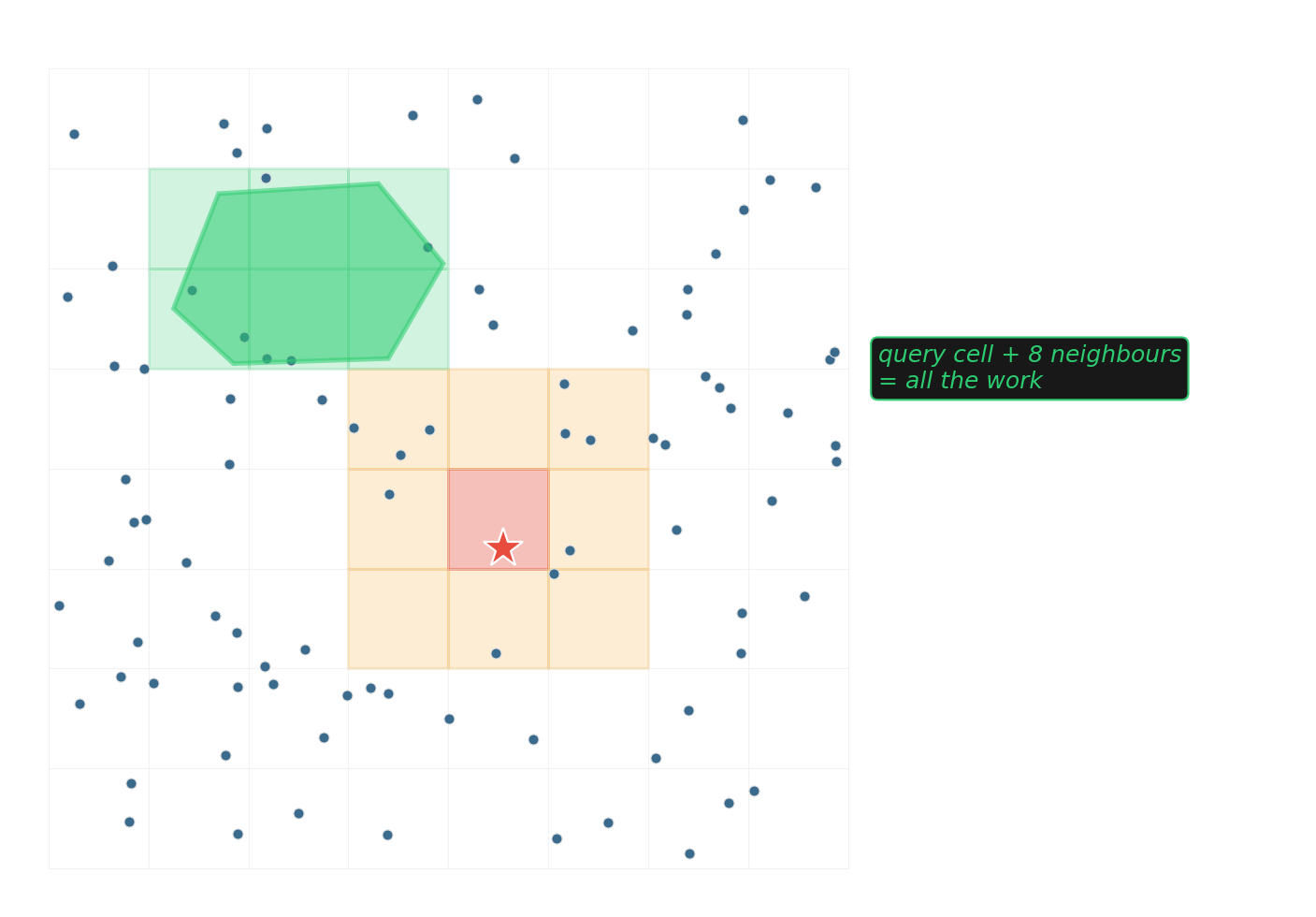
\(O(1)\) expected for near-neighbor queries when points are roughly uniform. One array of bucket vectors, one divide-and-floor to find a cell.
kd-tree — recursive median splits


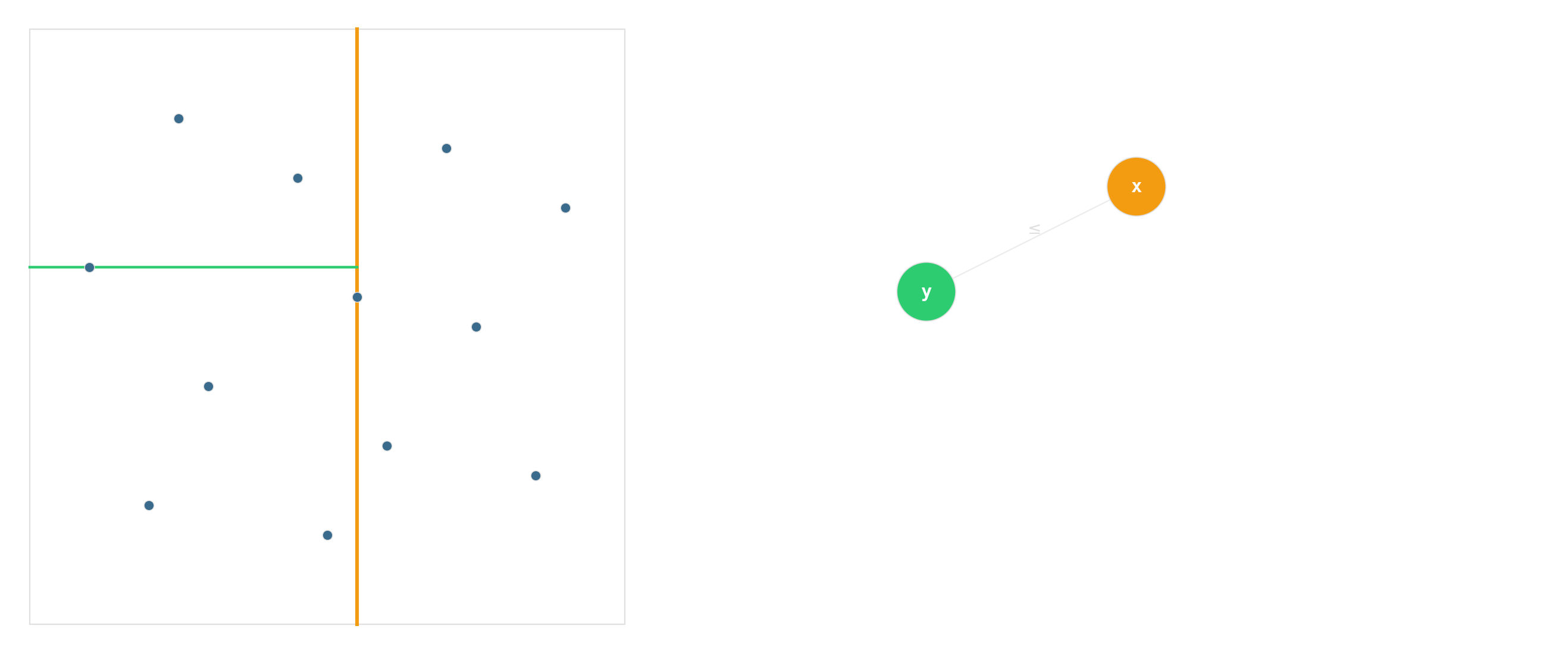
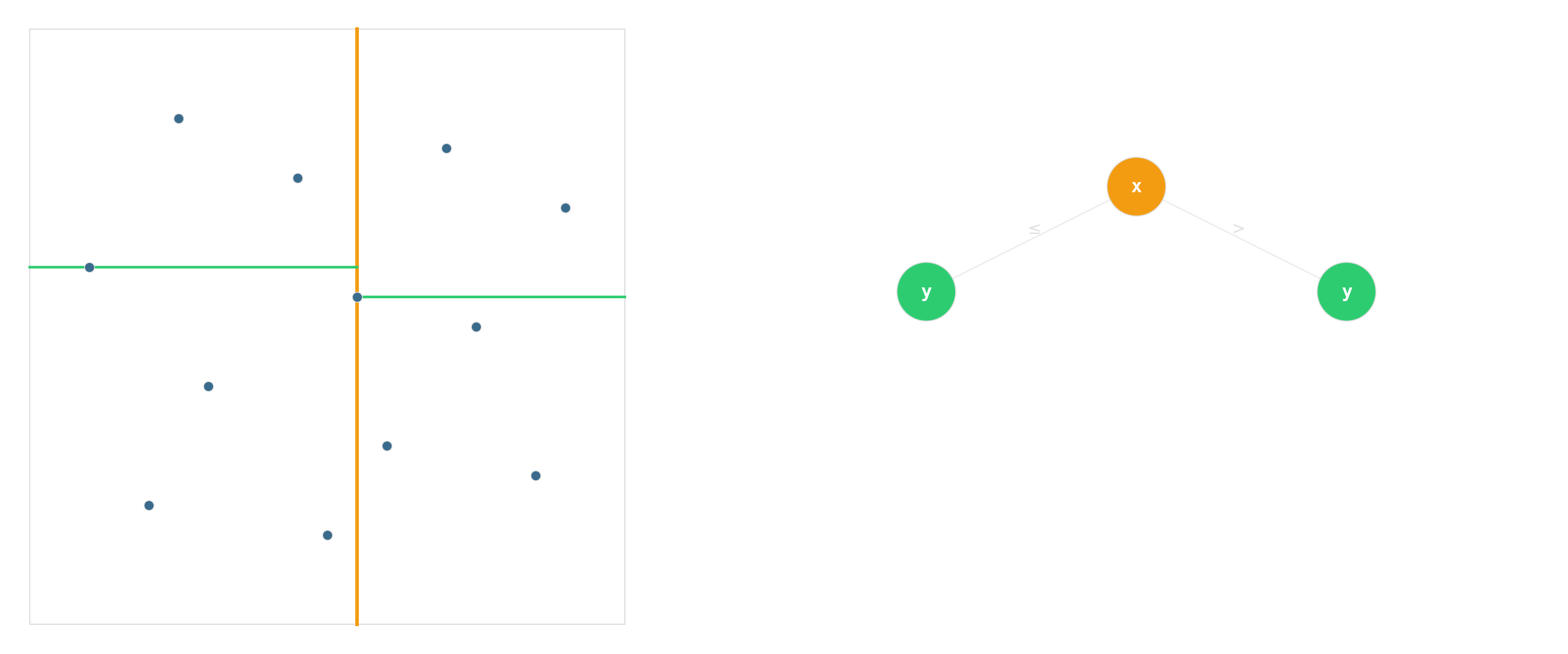
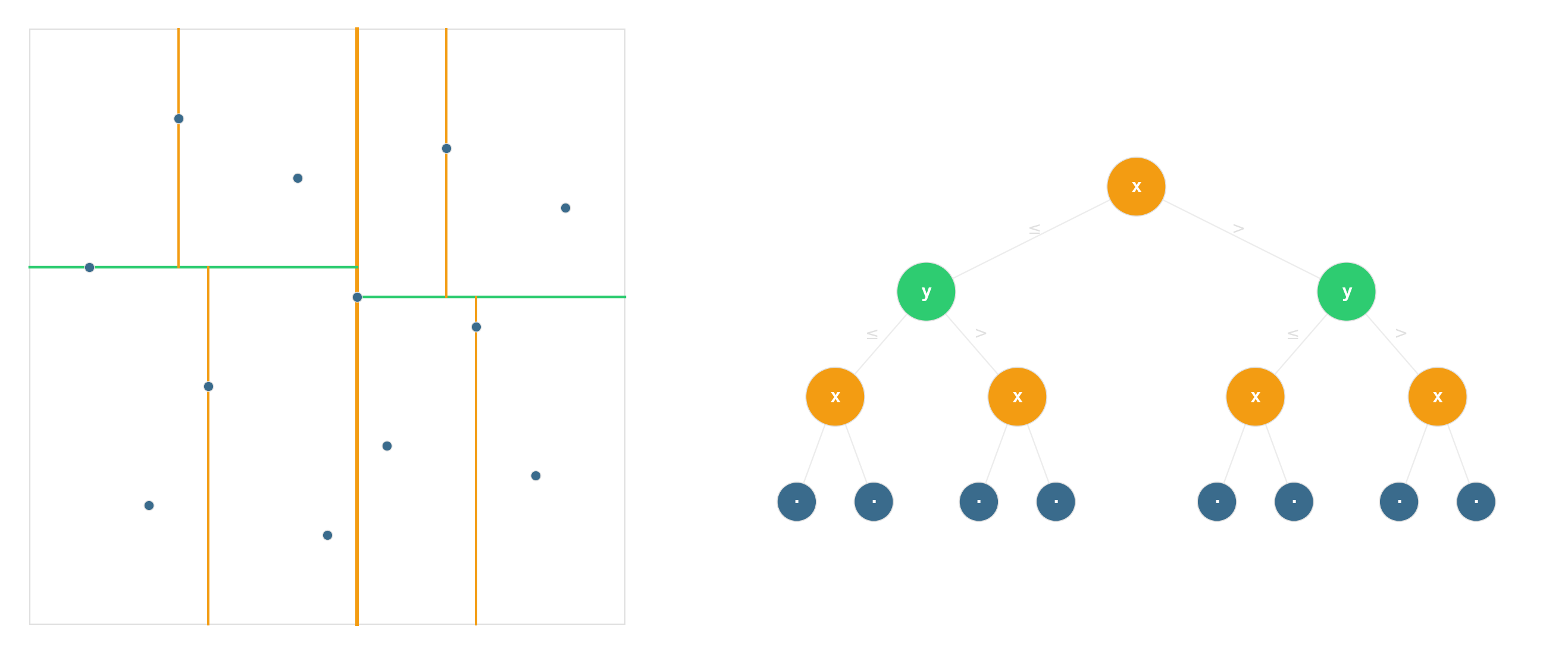
Degrades to linear scan as dimensionality rises. By about twenty dimensions, brute-force is competitive. This is the “curse of dimensionality” for data structures.
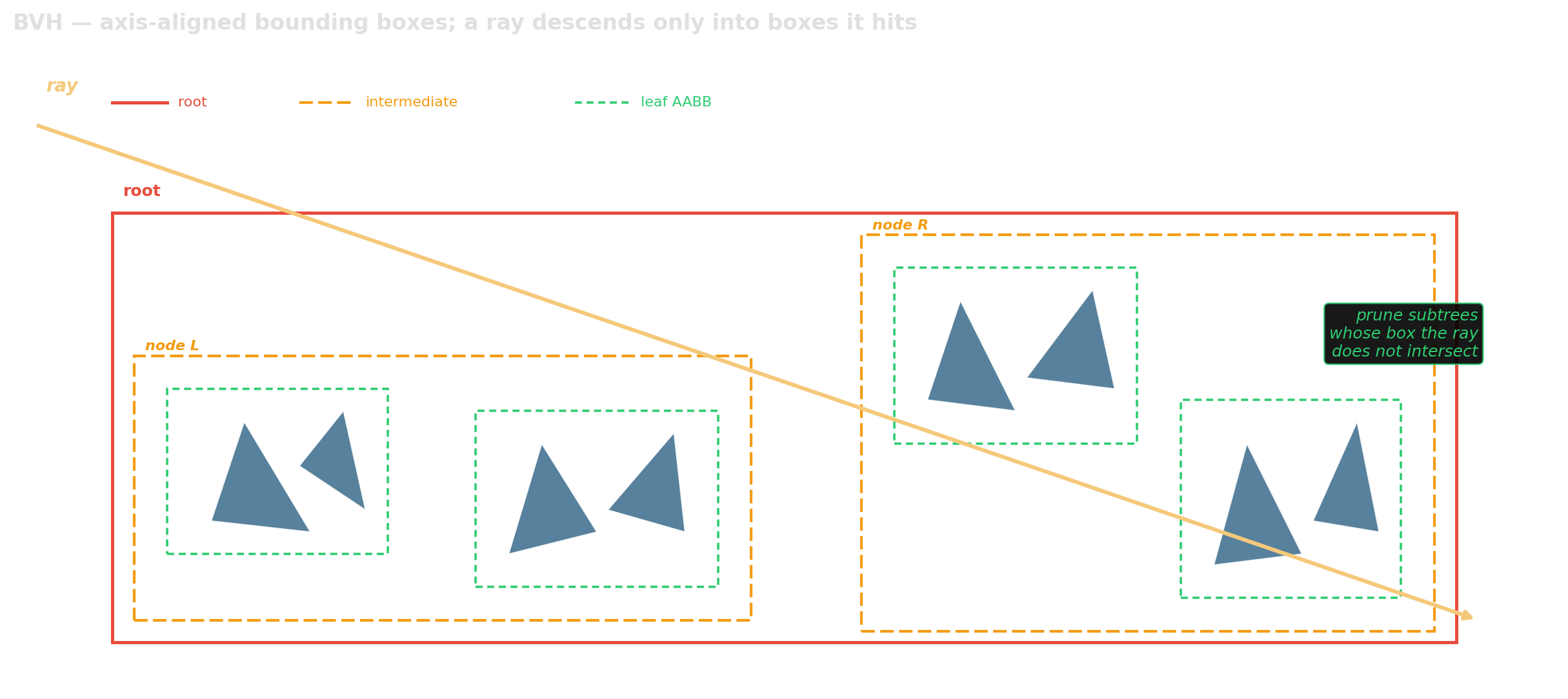
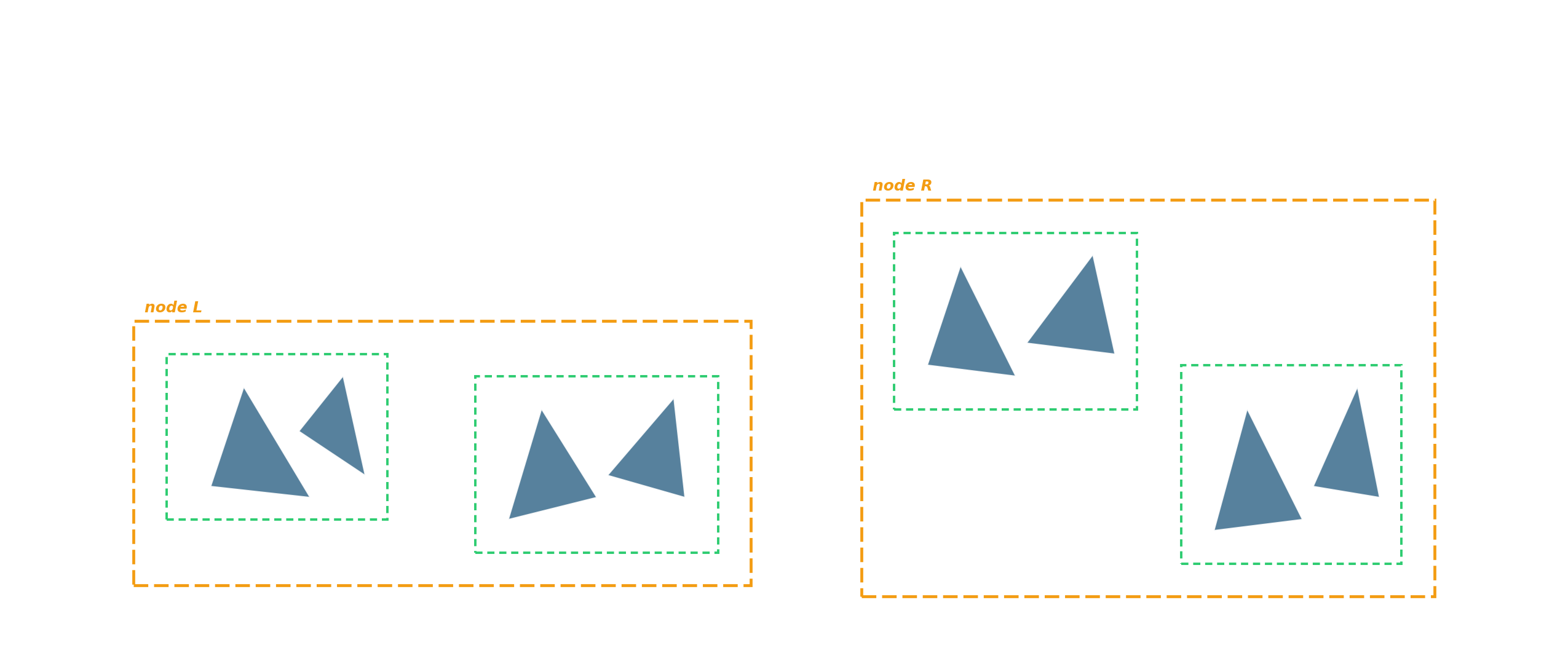
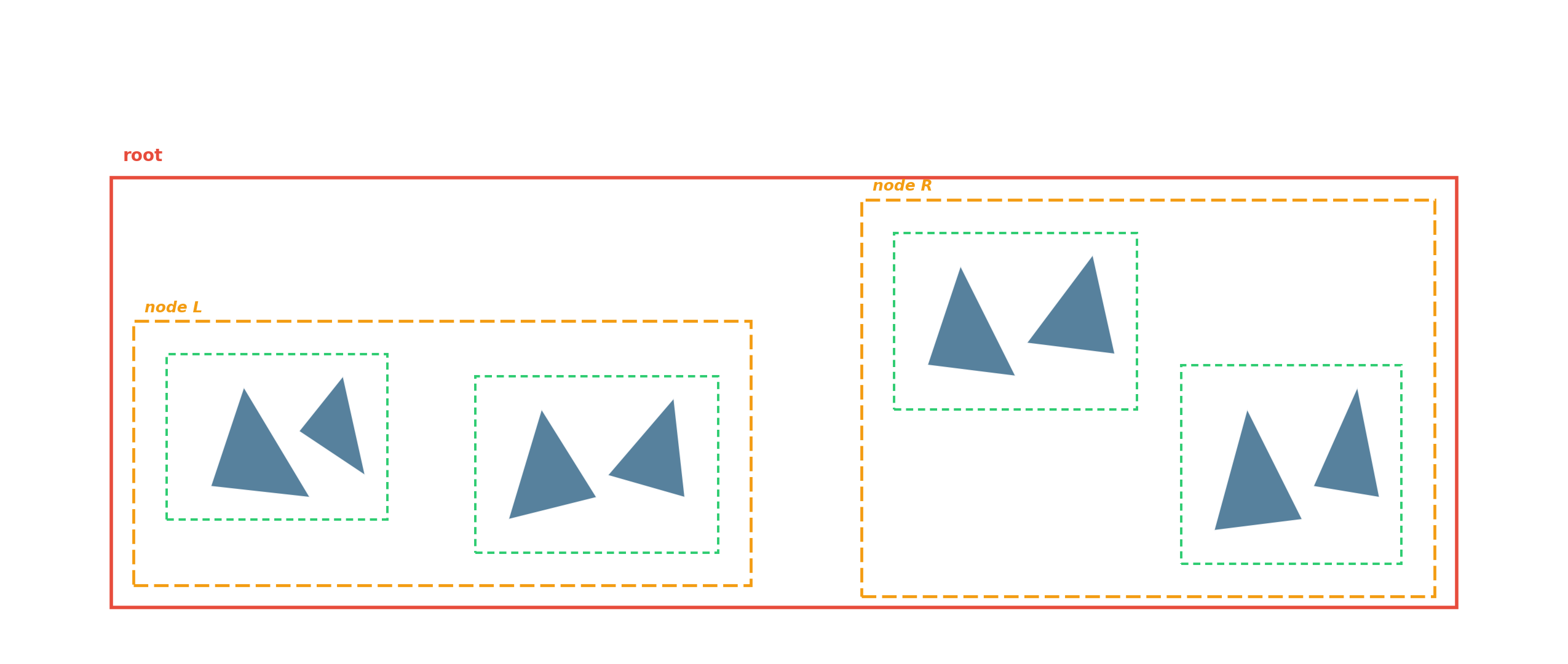
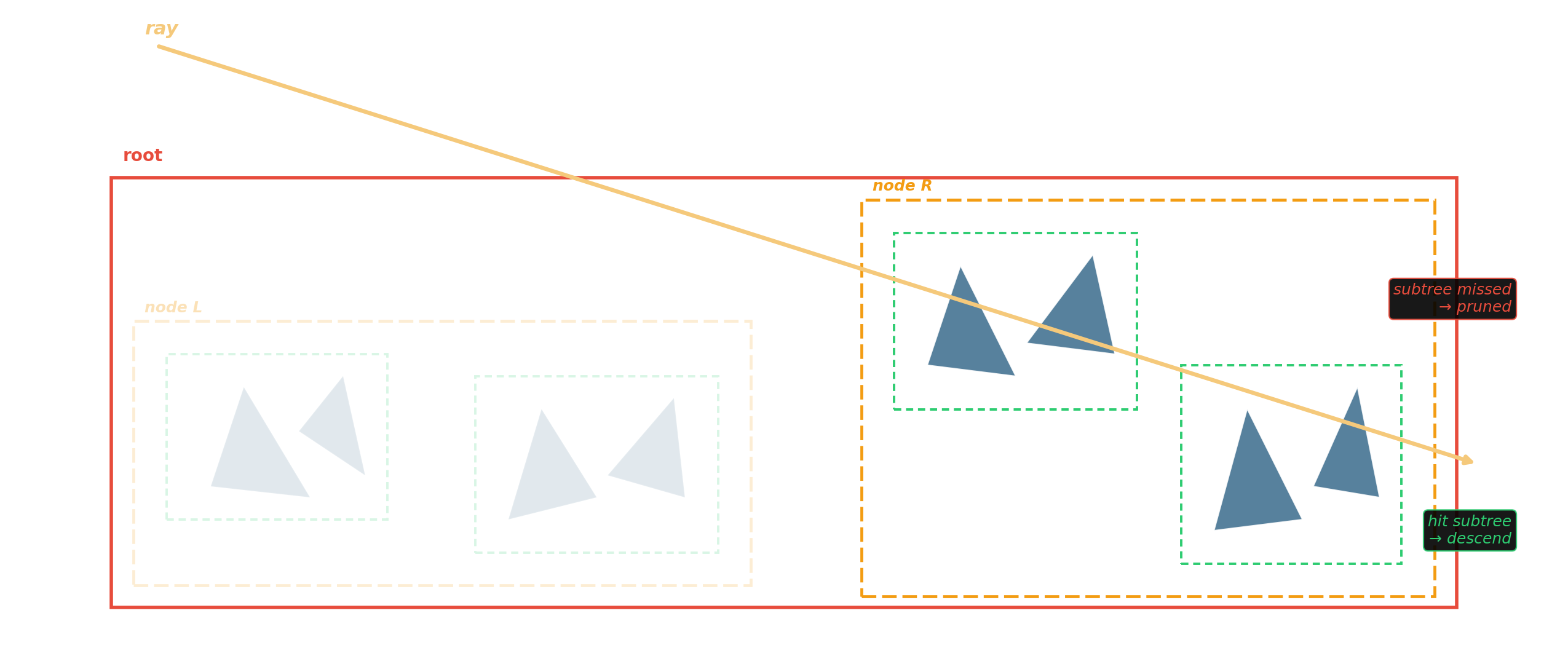
BVH — the ray-tracing workhorse

R-tree — rectangles in a database
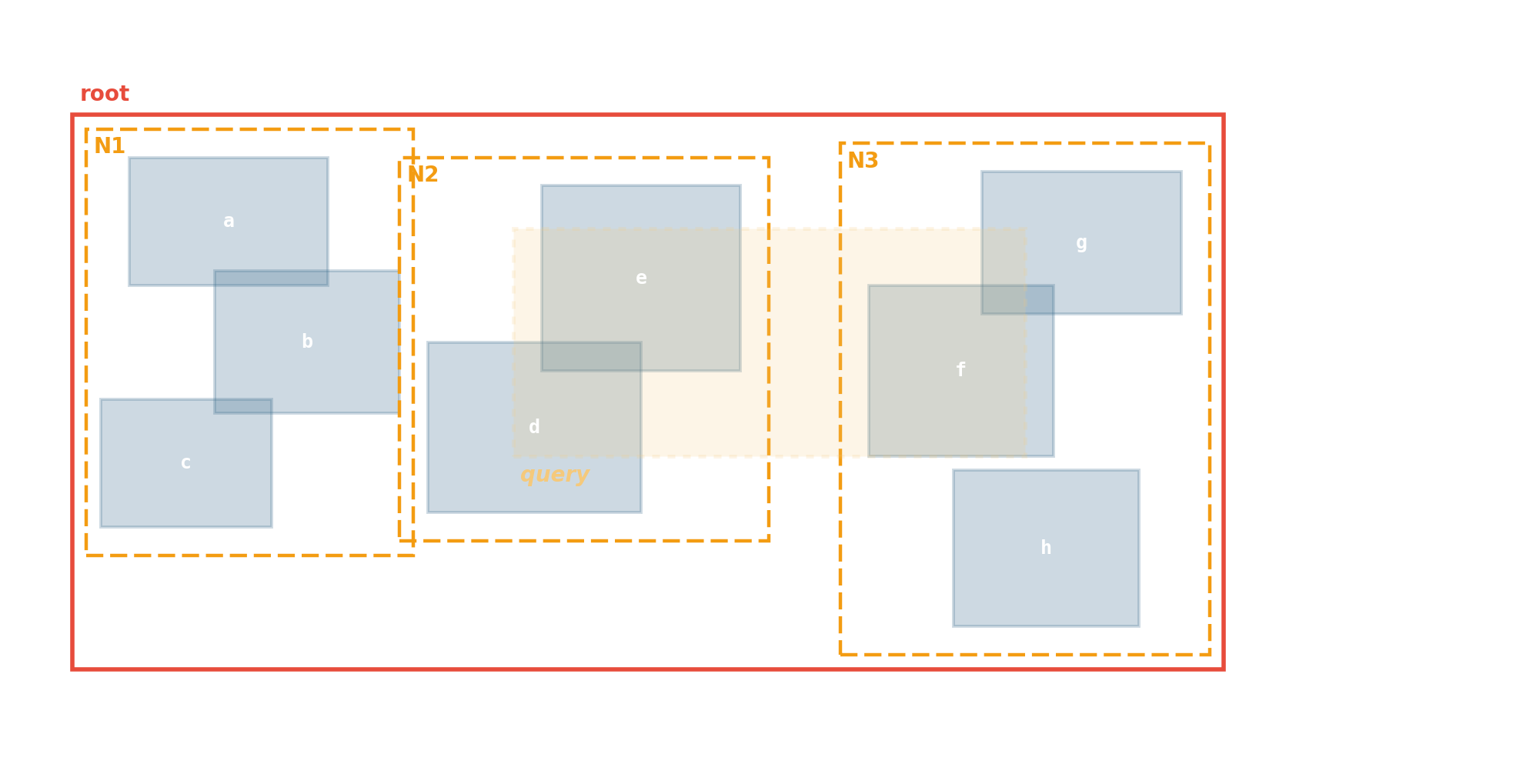
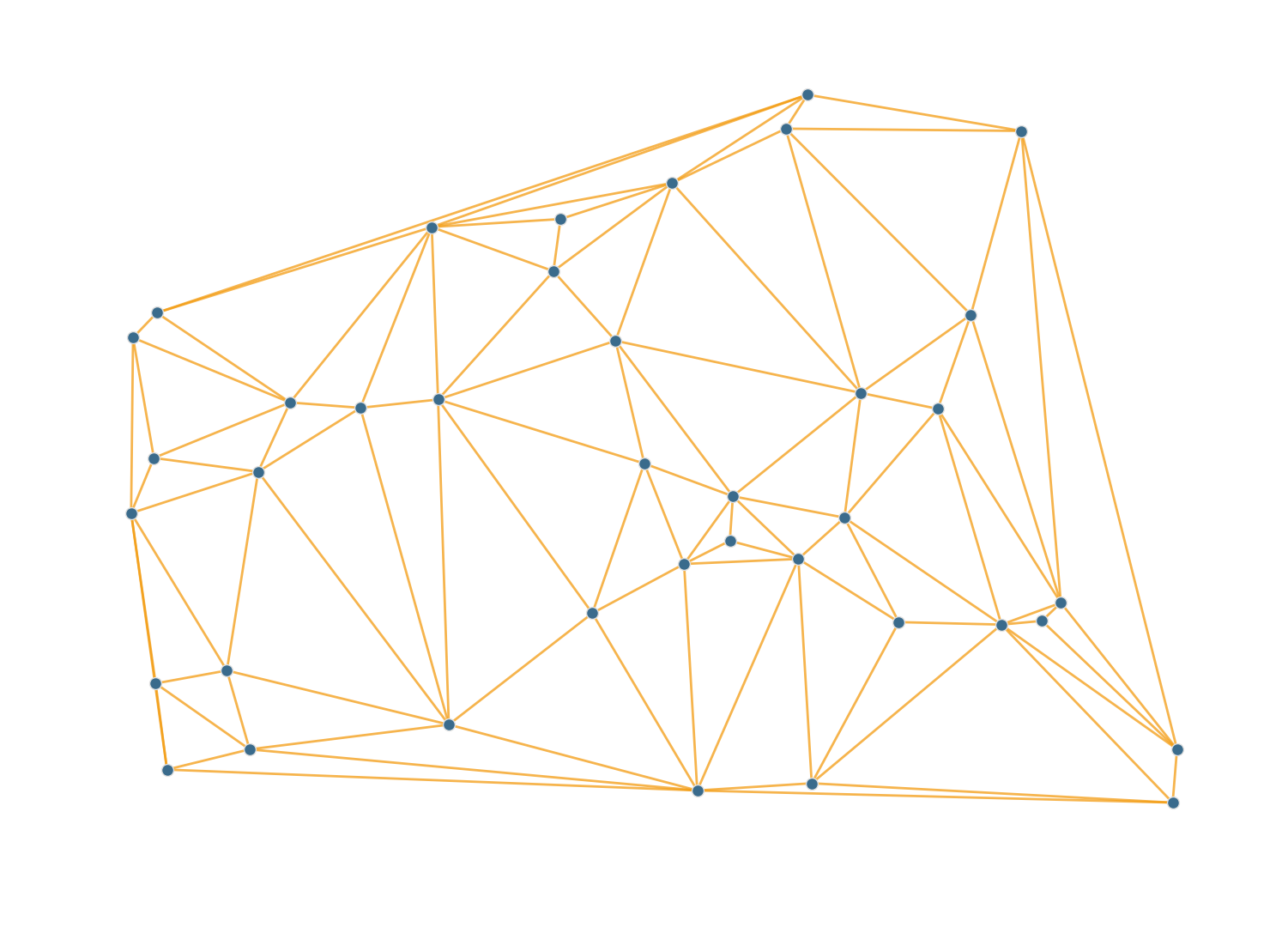
Delaunay triangulation — geometry → sparse graph

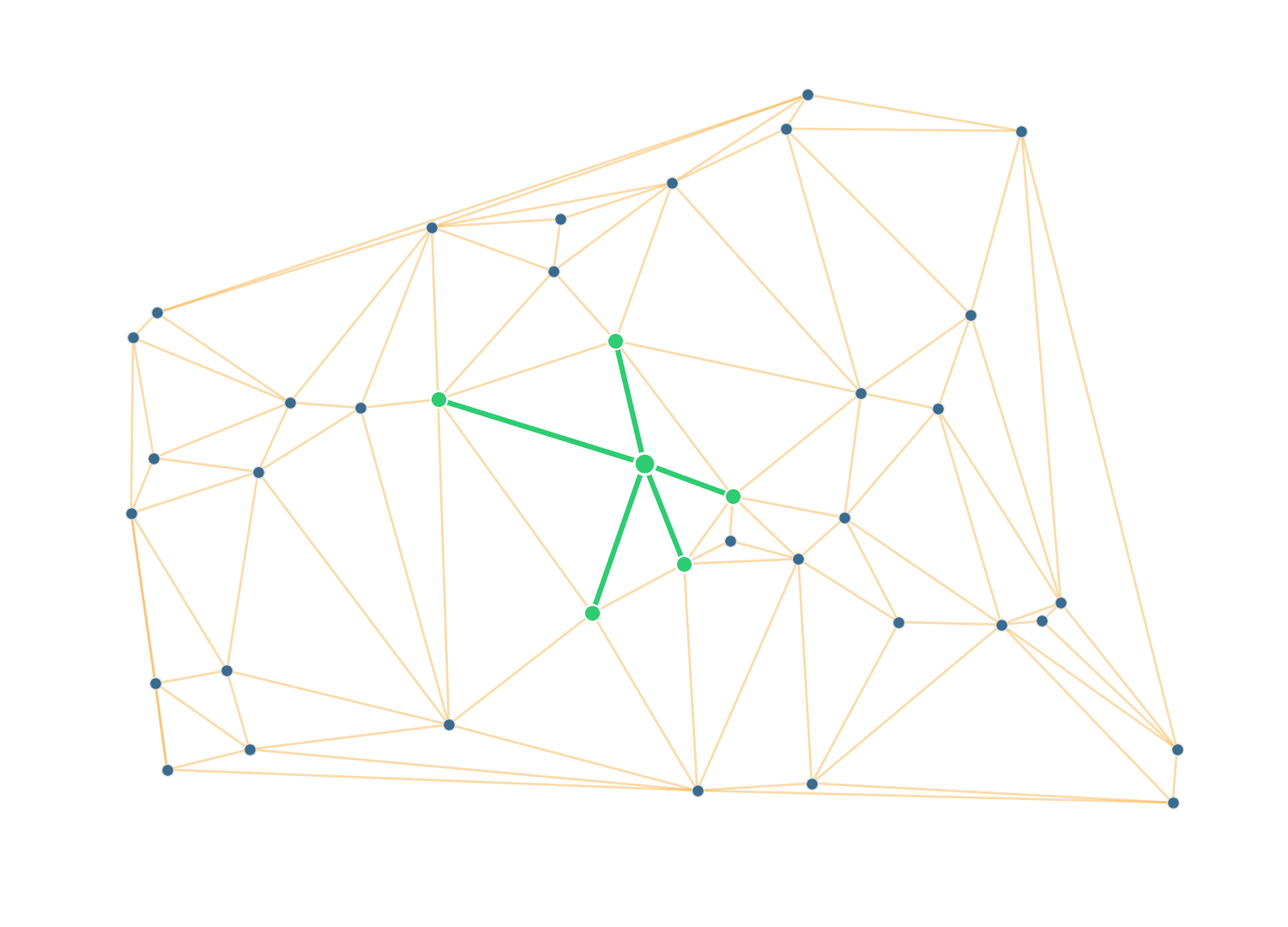
Not a query accelerator — a graph builder. Turns a point cloud into a sparse planar graph so downstream graph algorithms have something to walk.
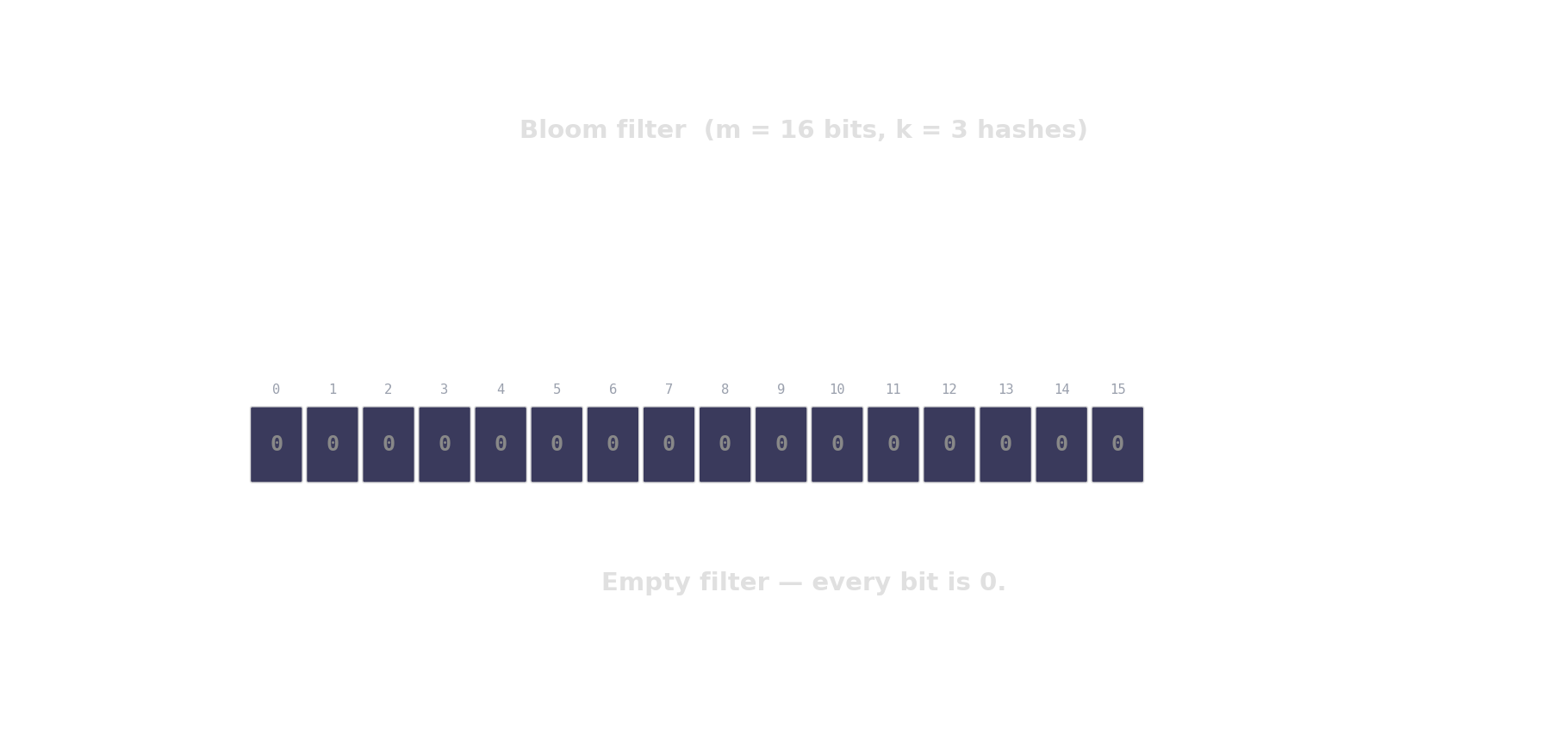
Bloom filter in action
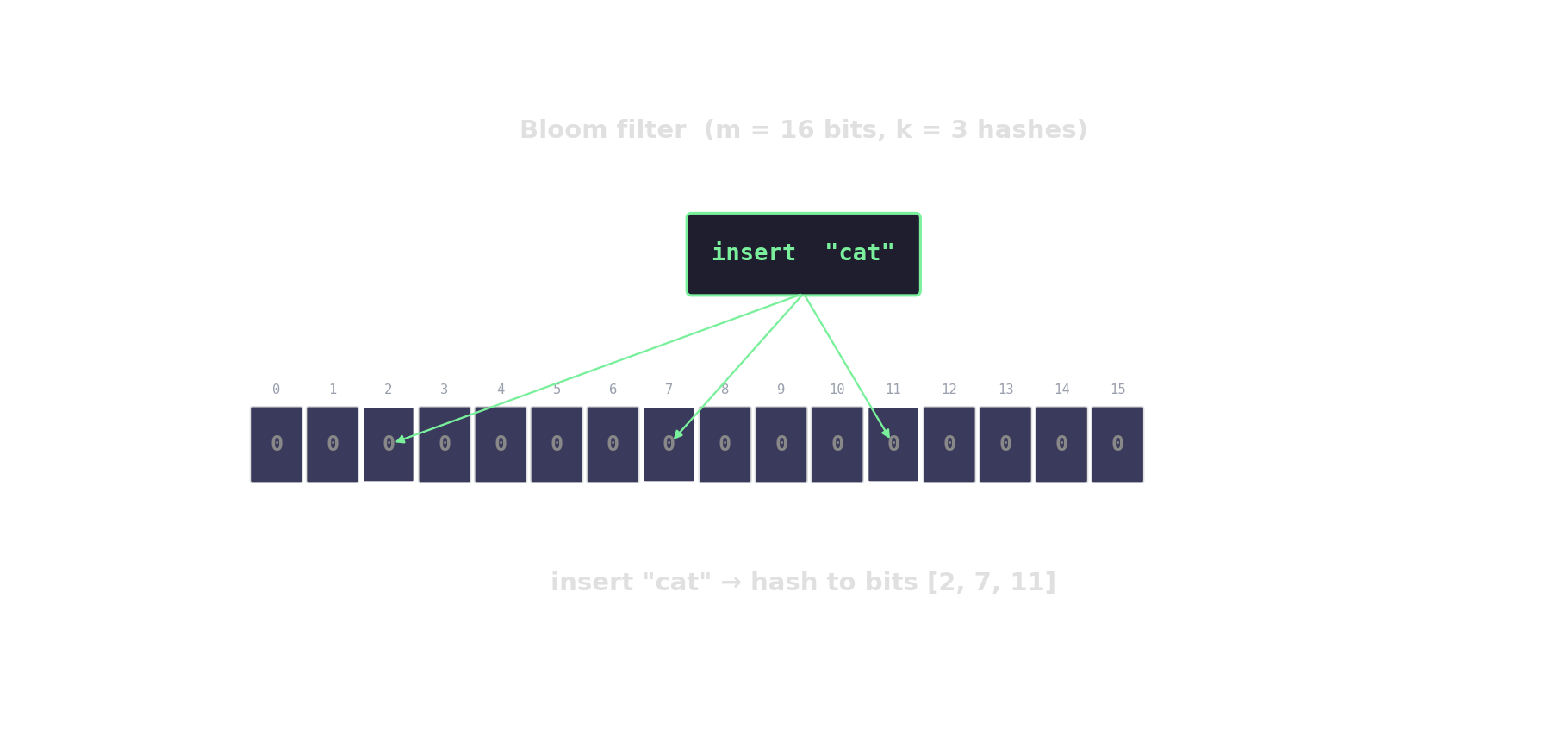
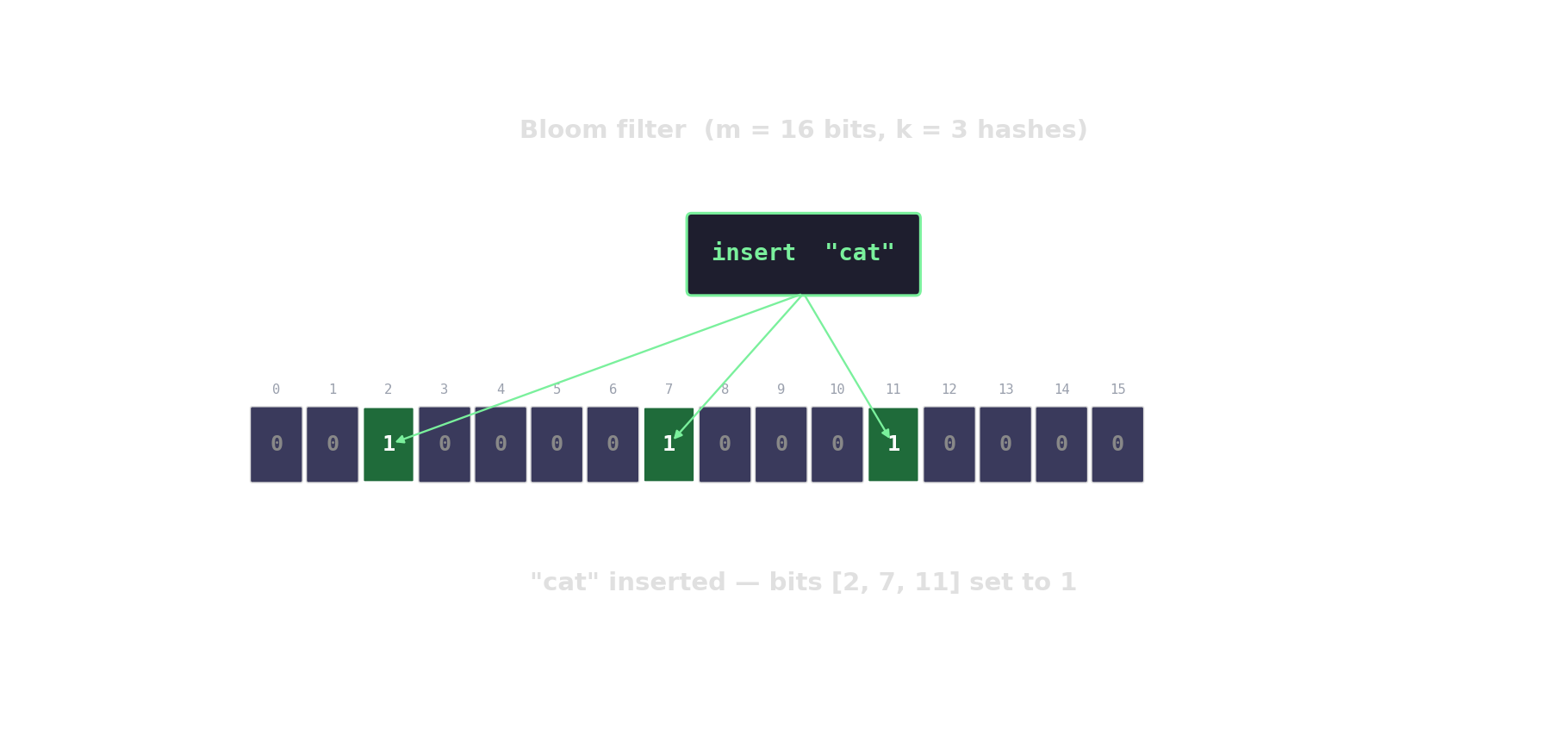
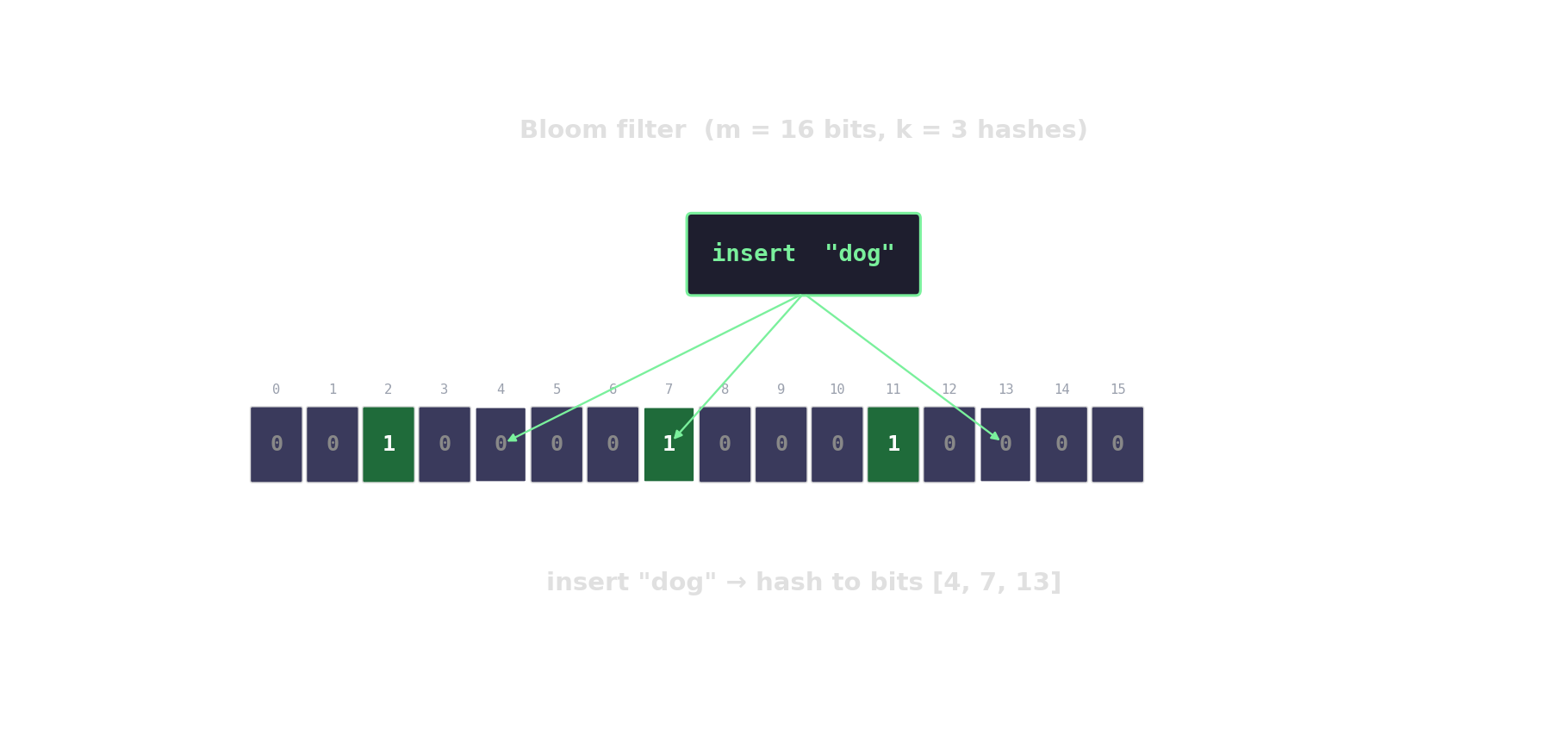
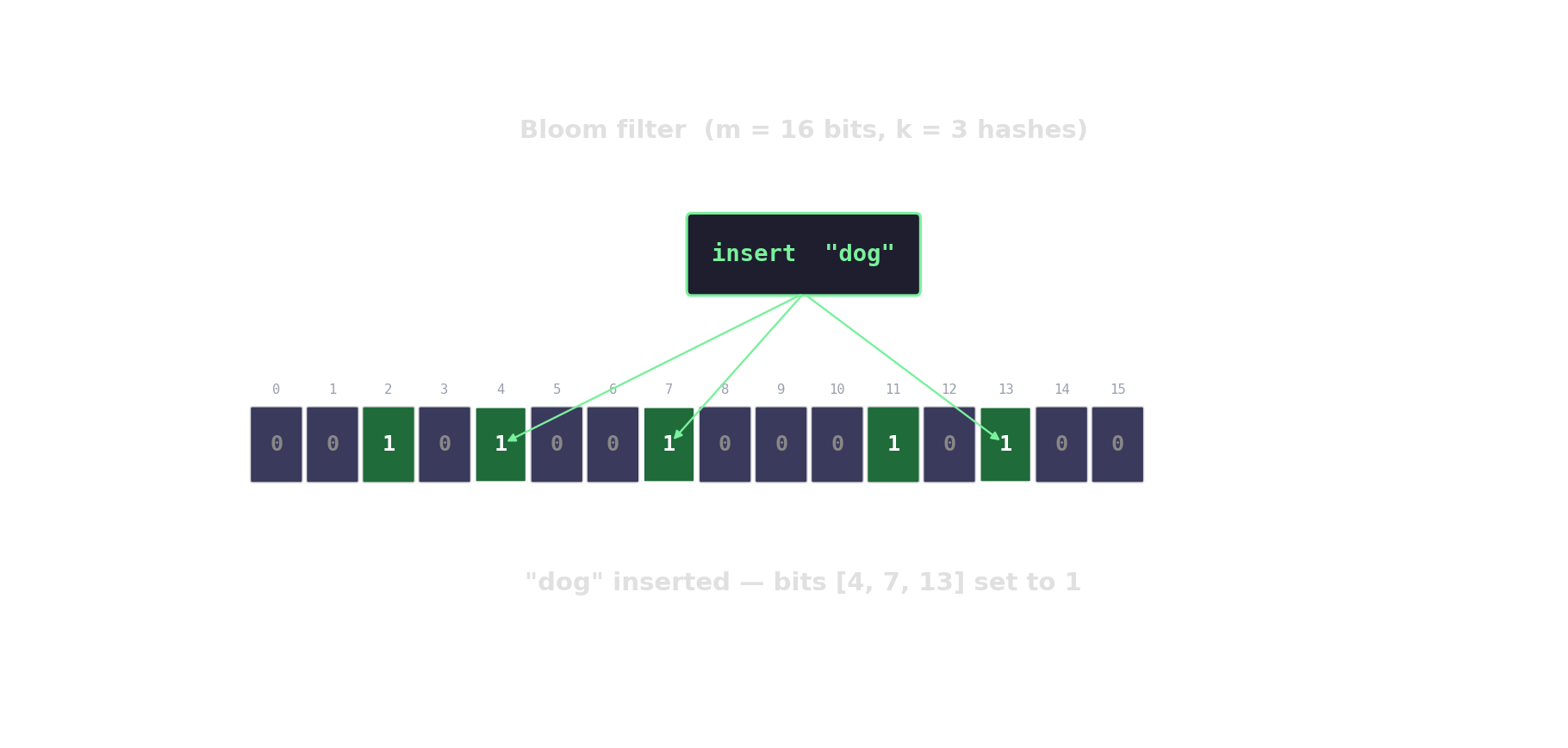
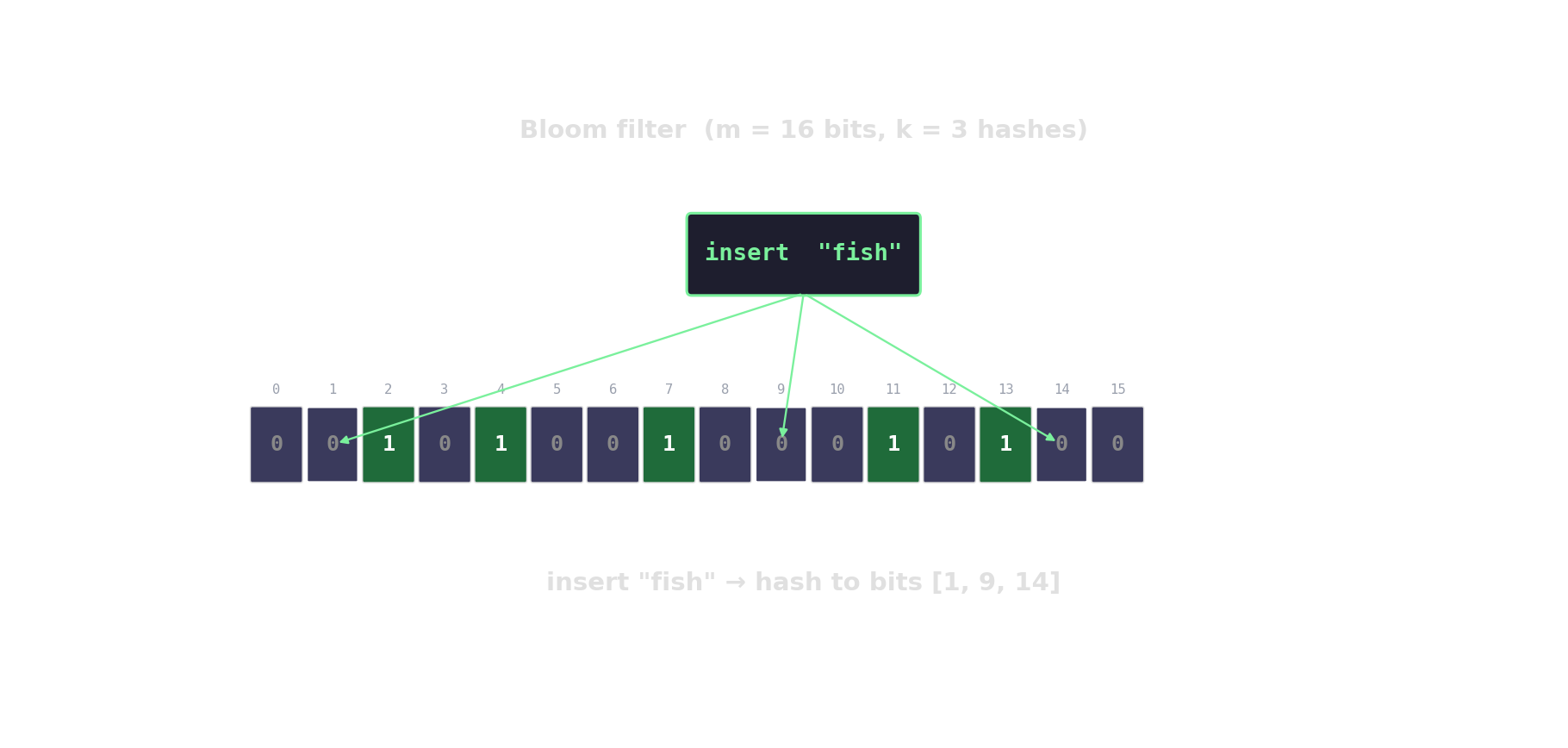
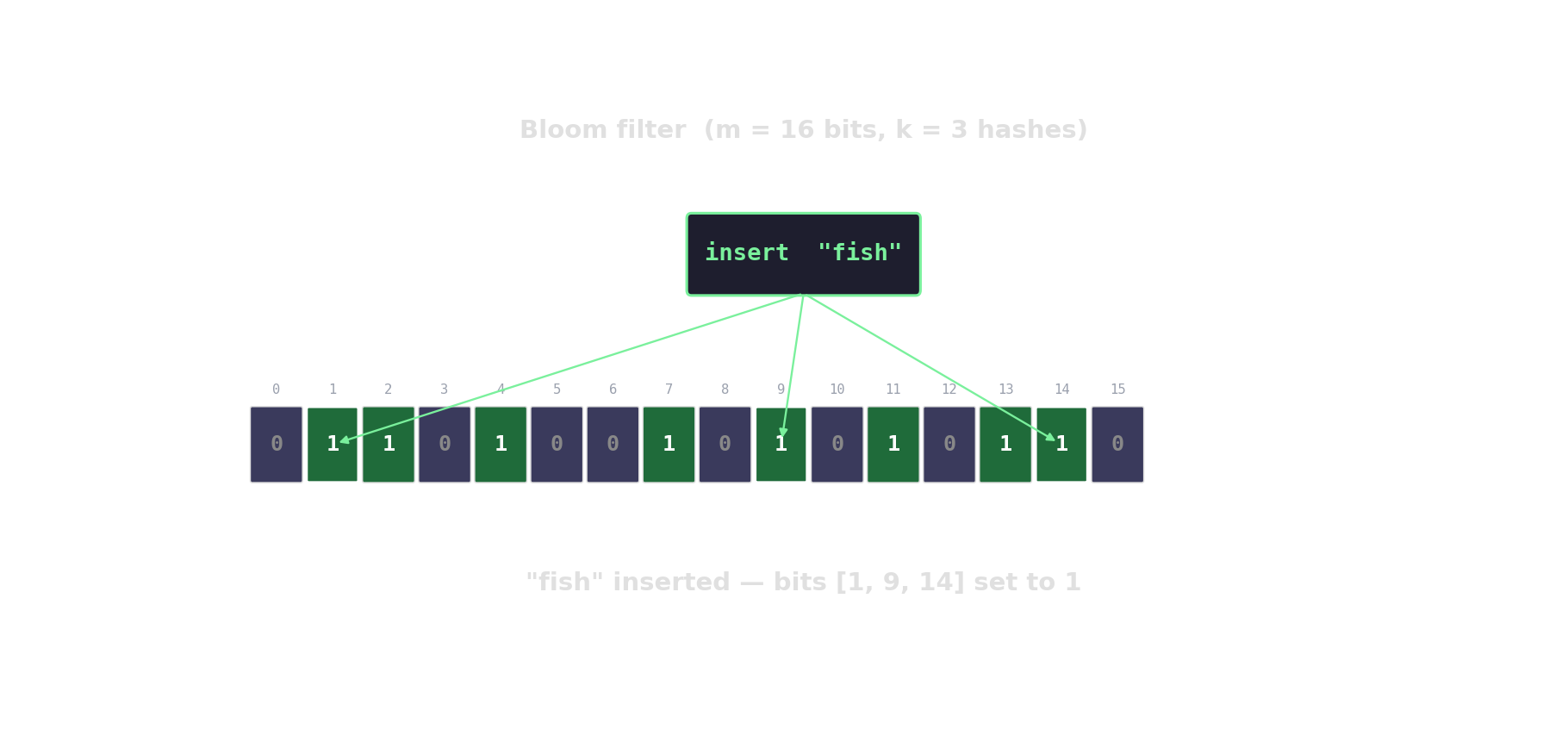
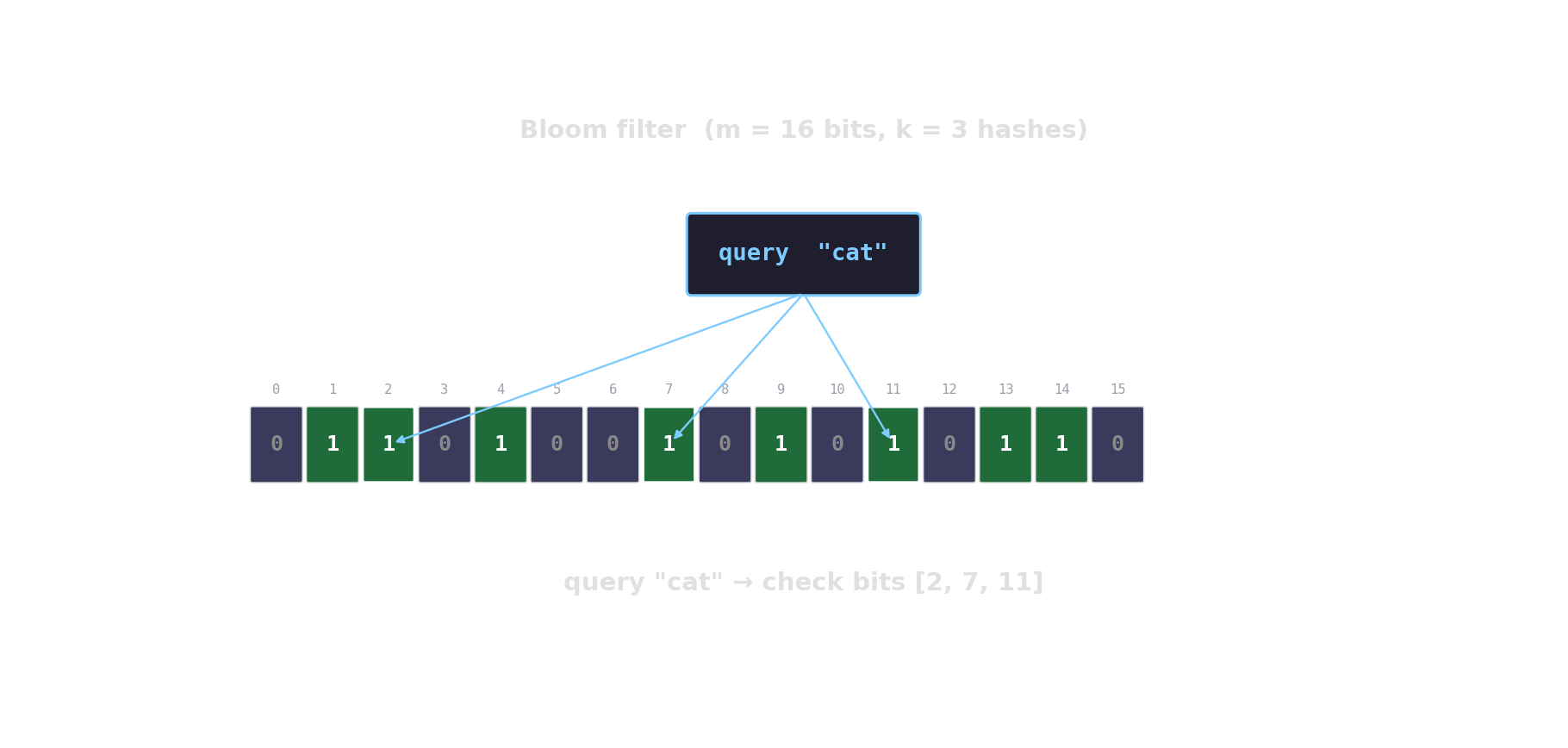
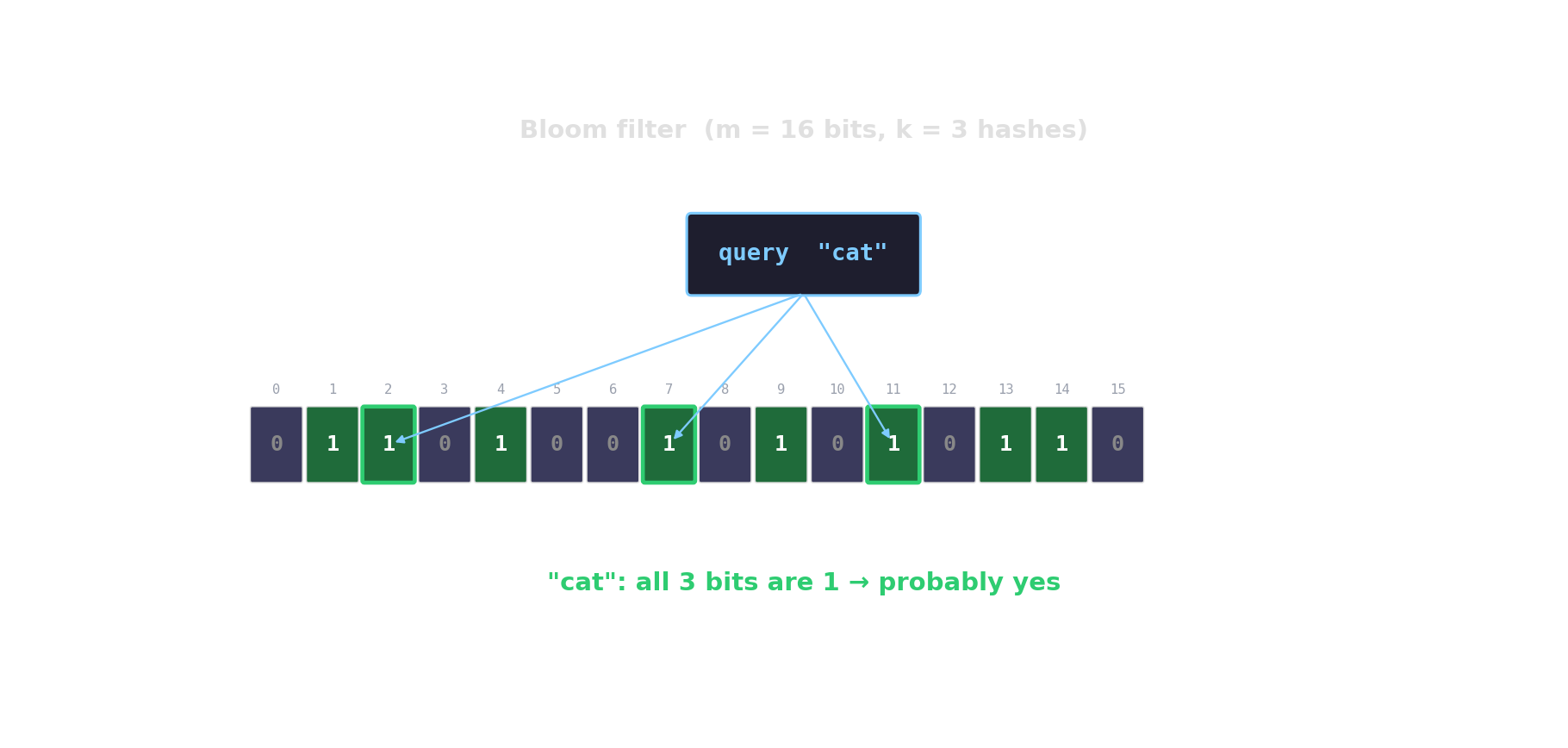
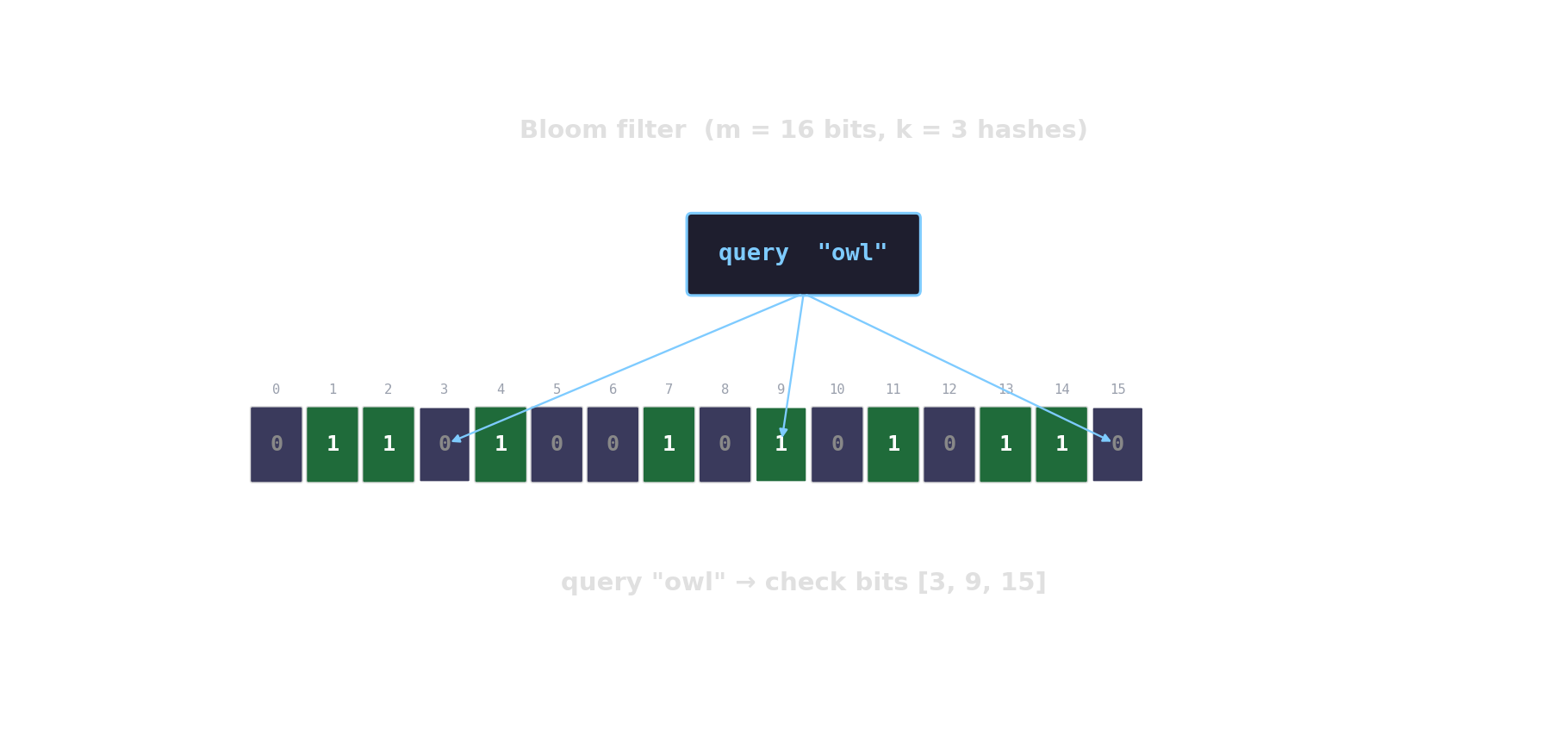
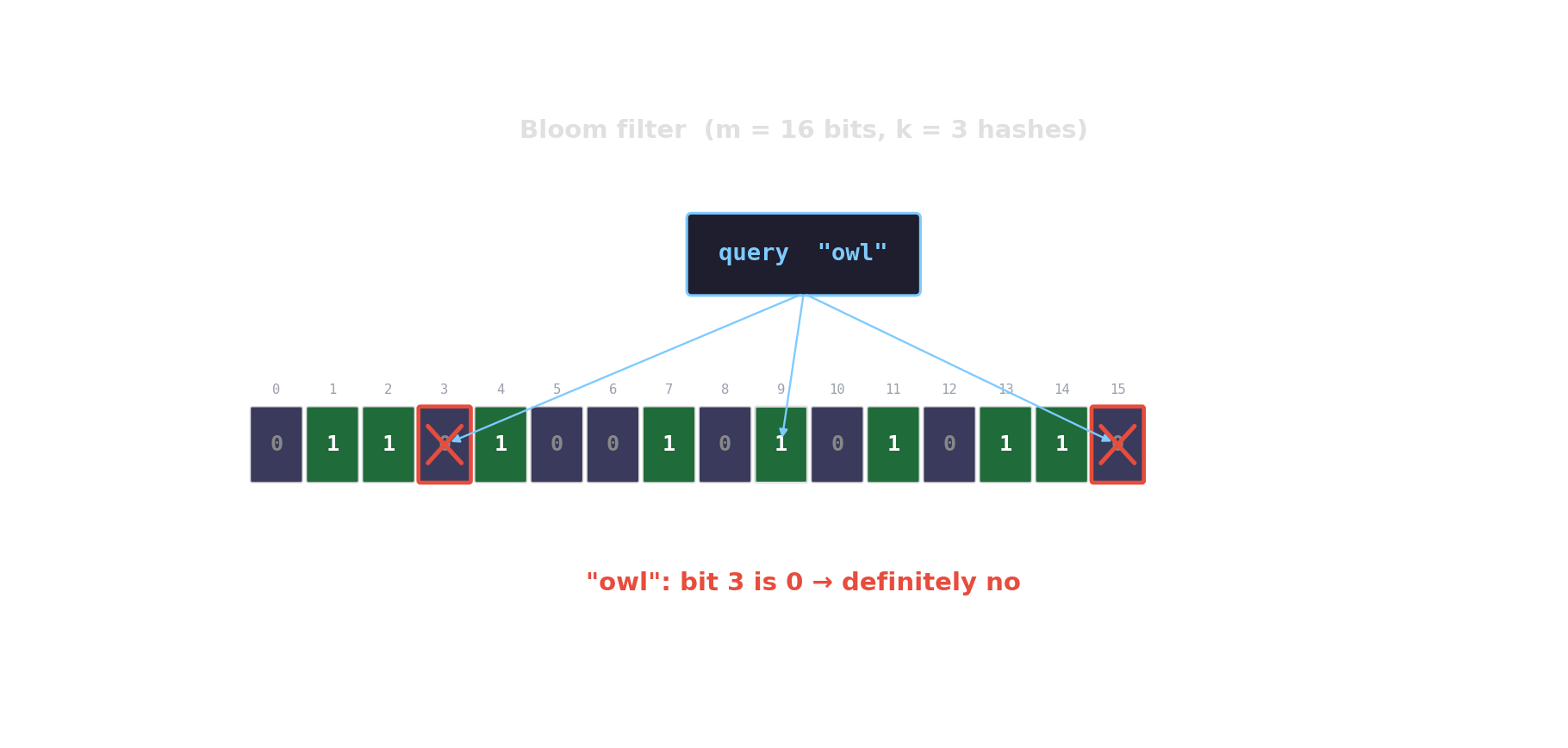
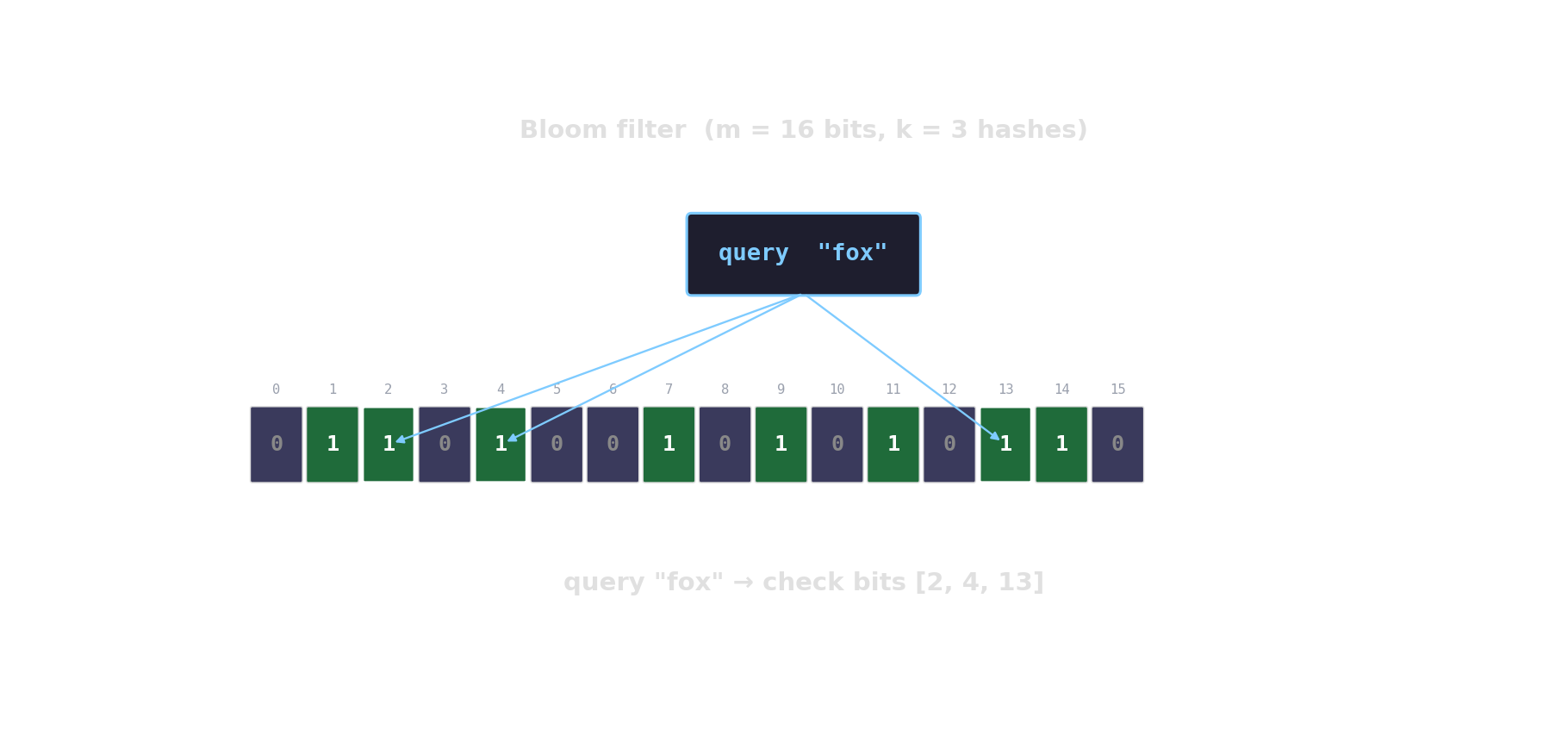
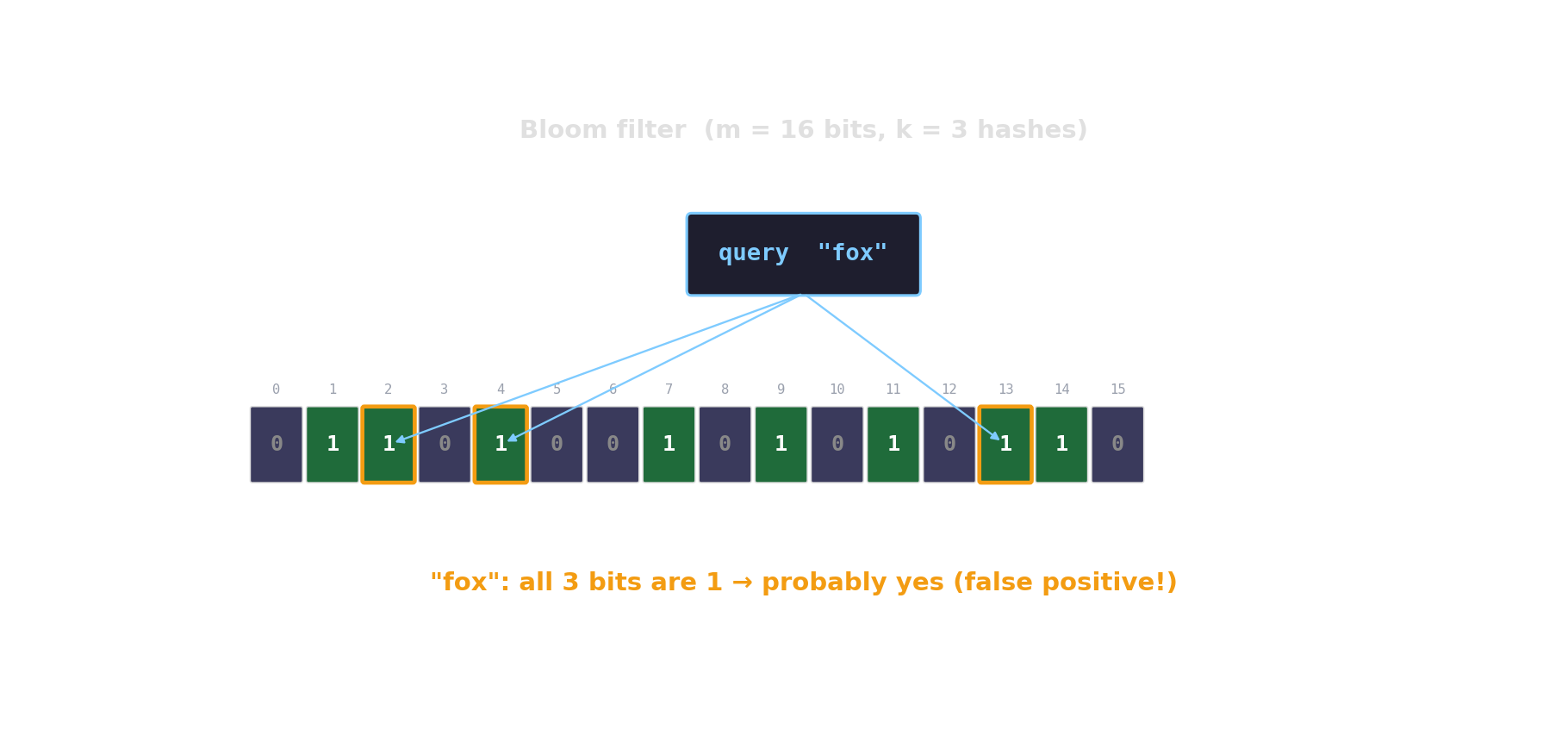
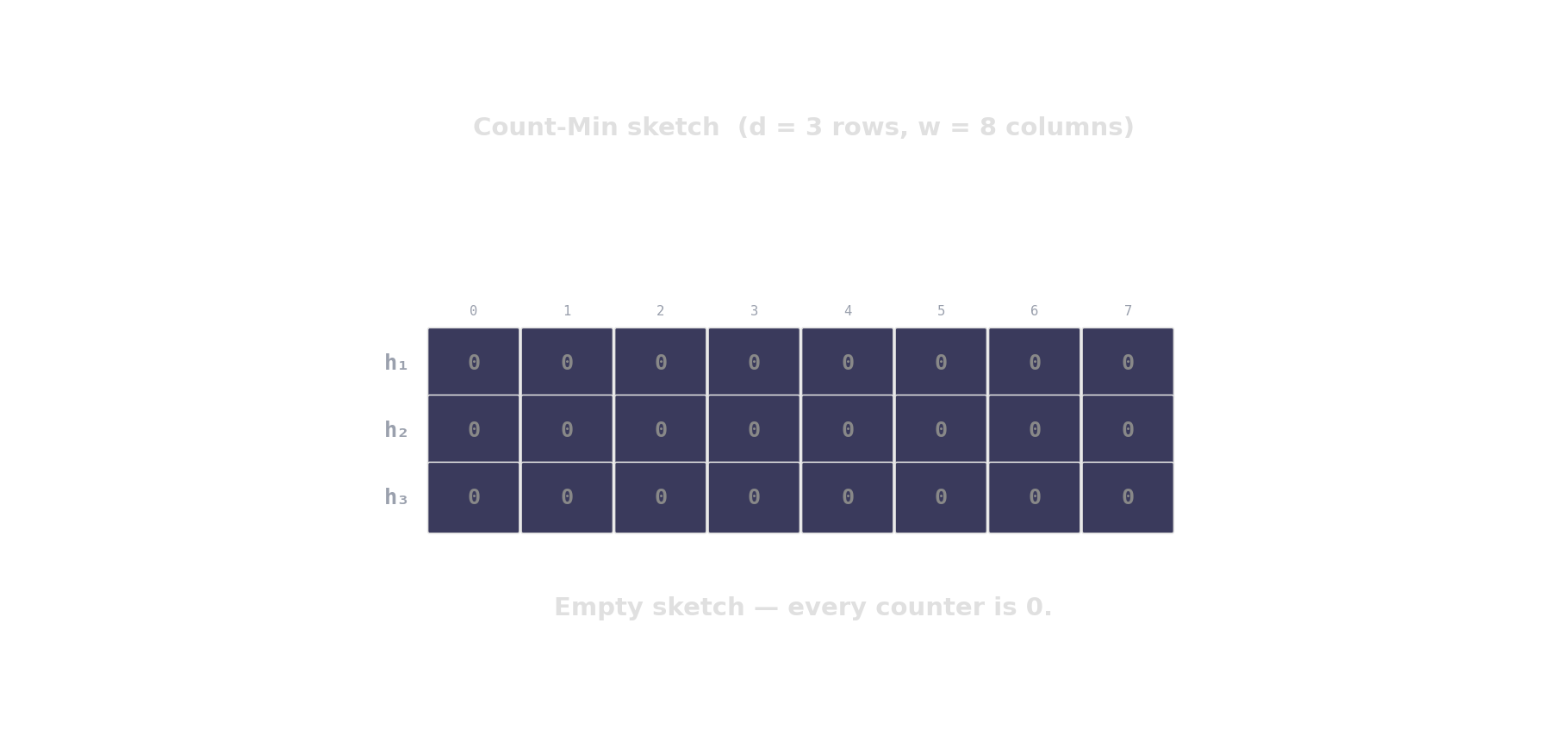
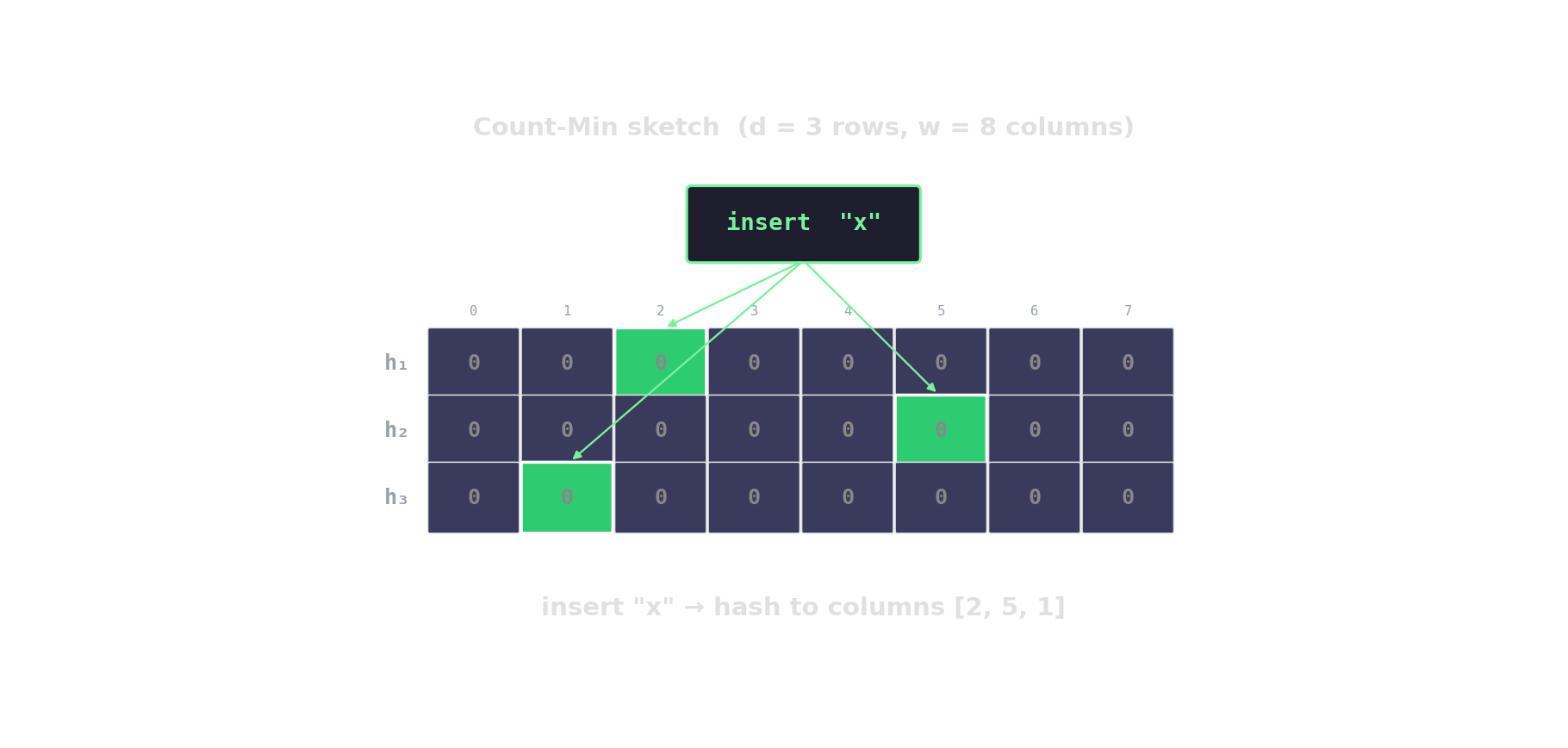
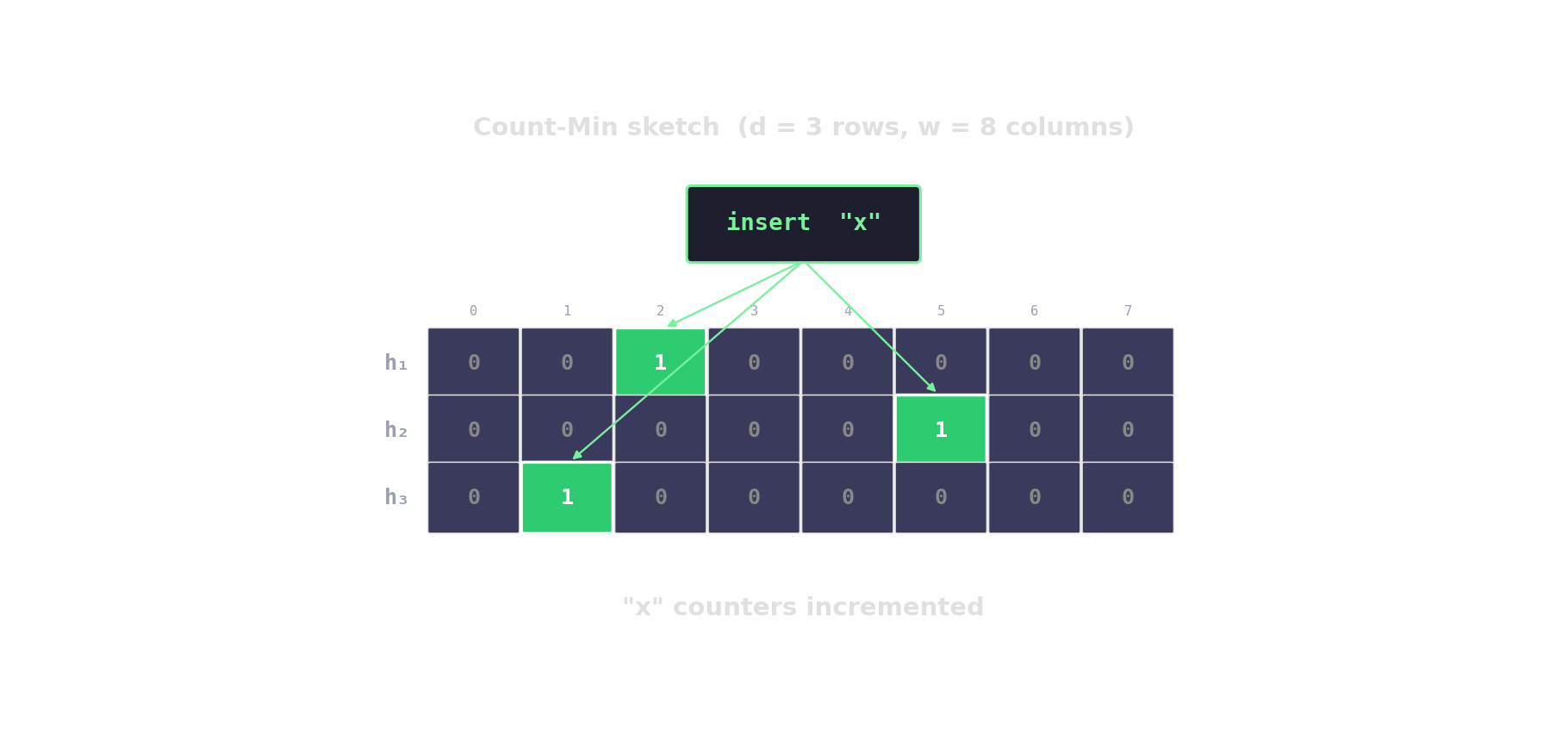
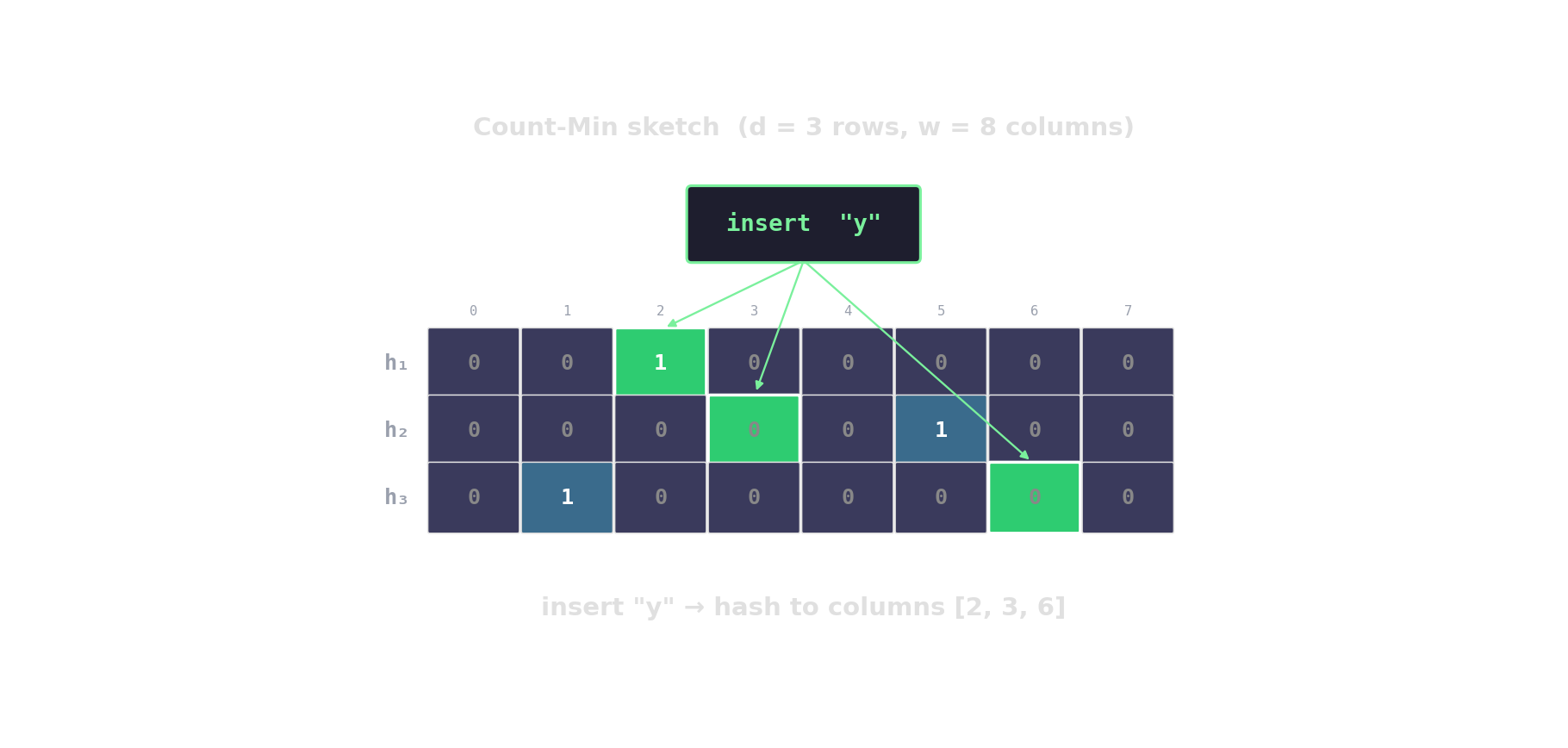
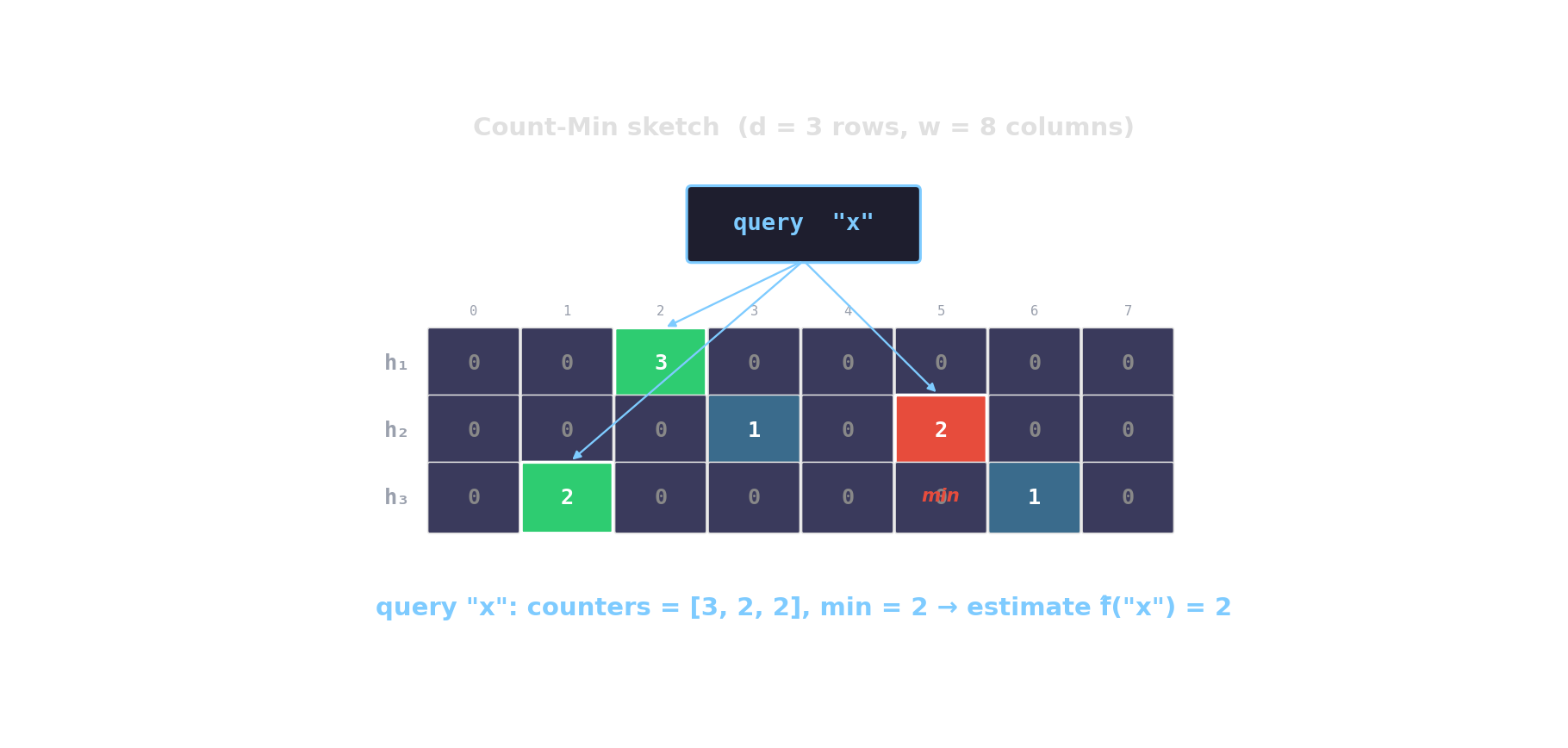
Count-Min sketch — approximate frequencies
d rows, w columns. Hash each item into one cell per row; increment. Query returns the min across rows.
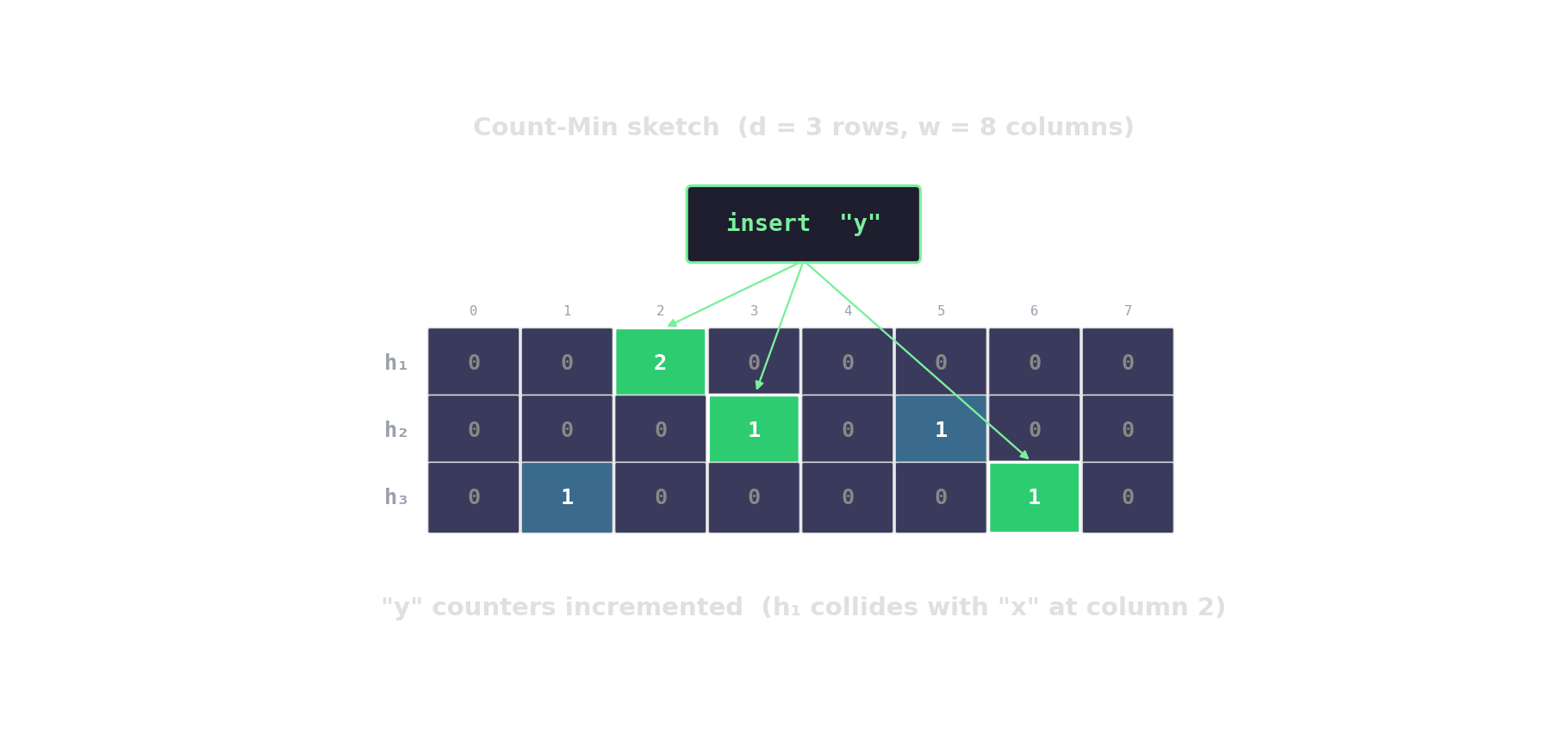
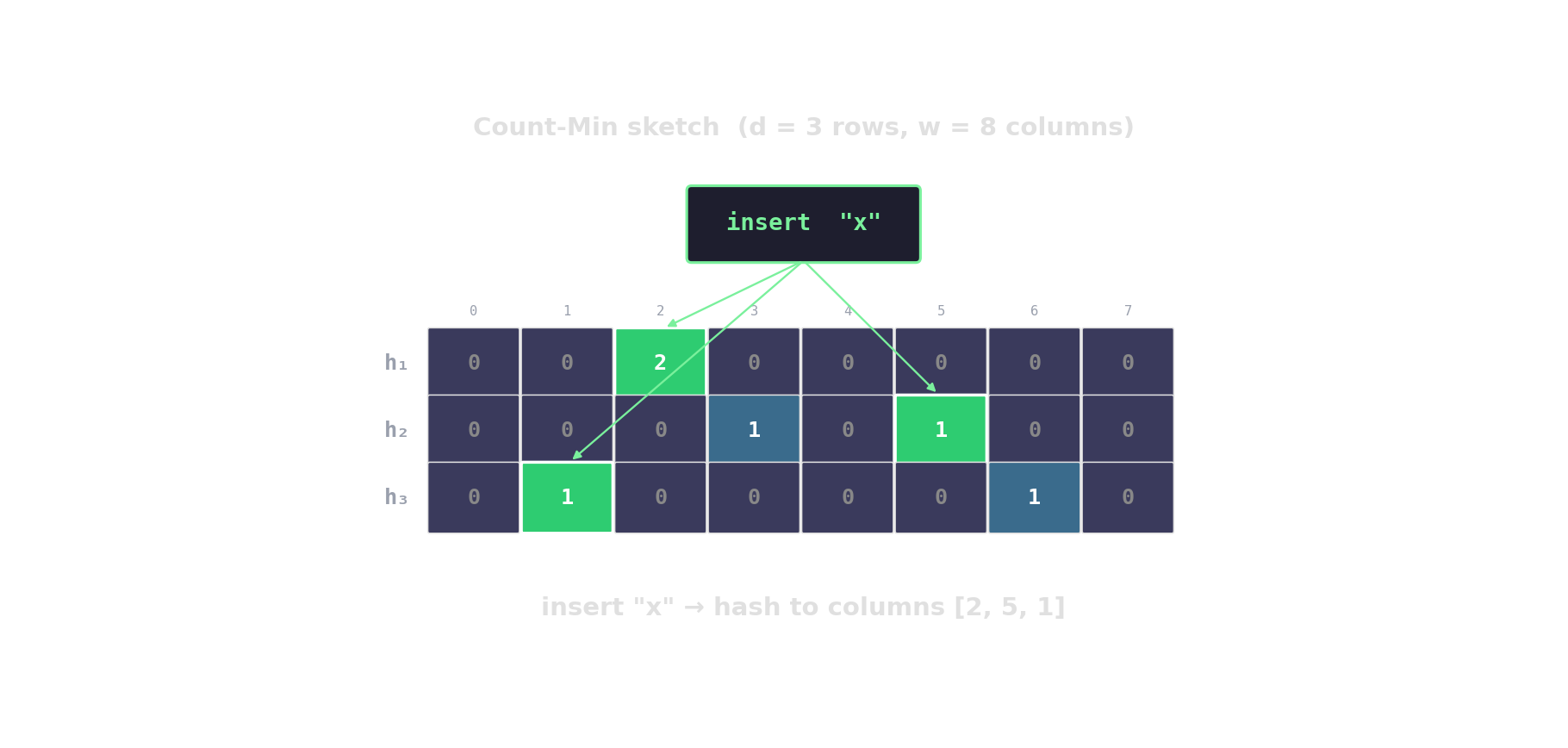
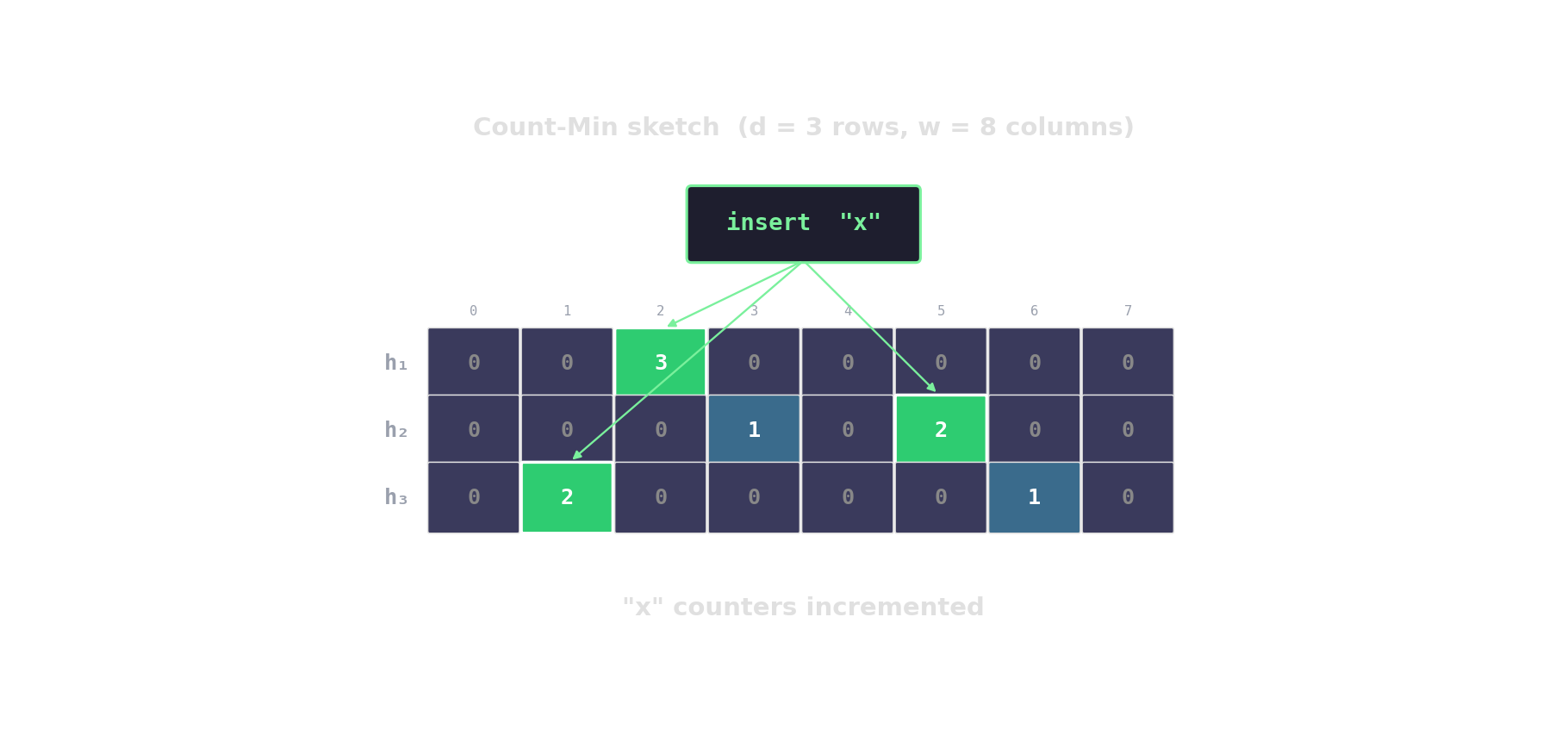
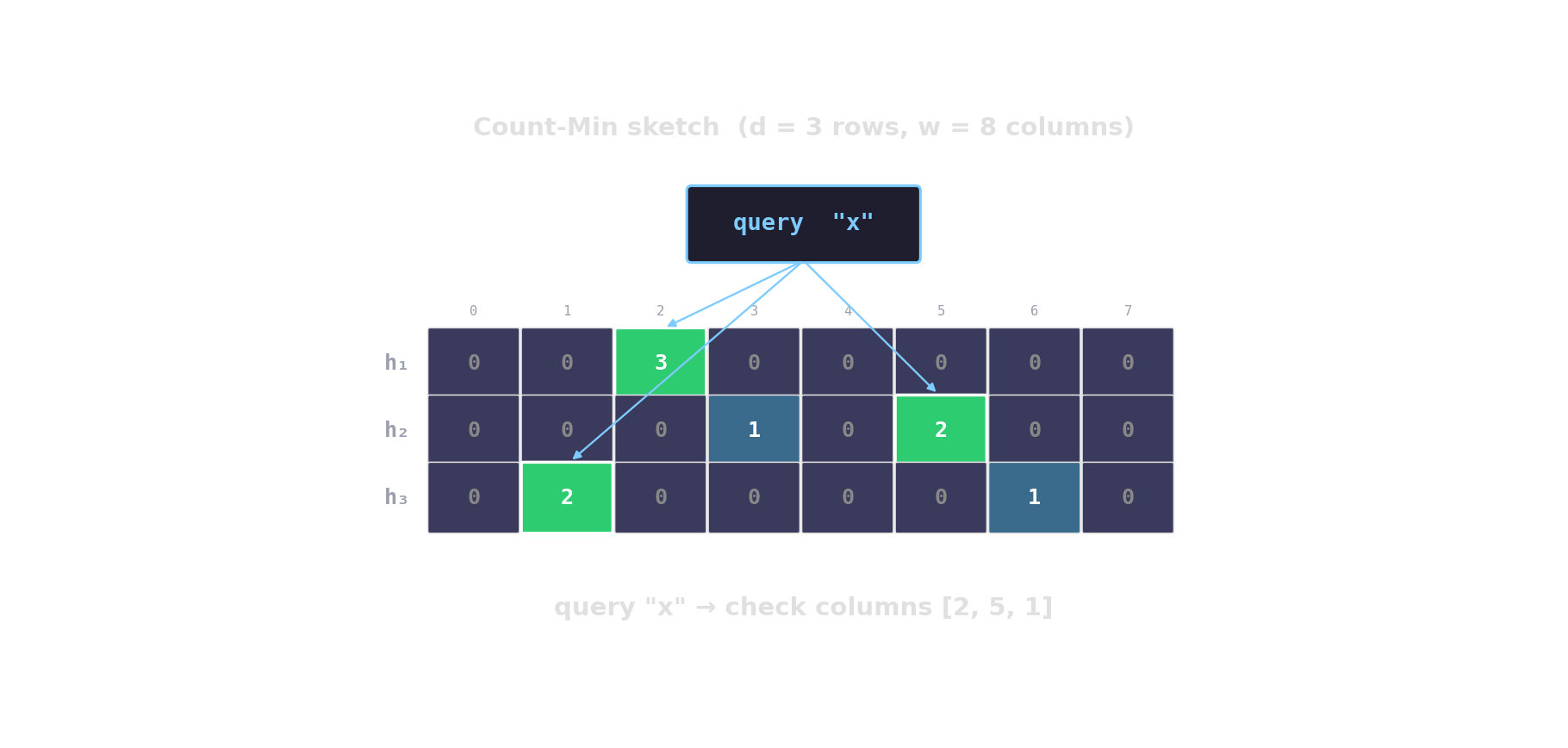
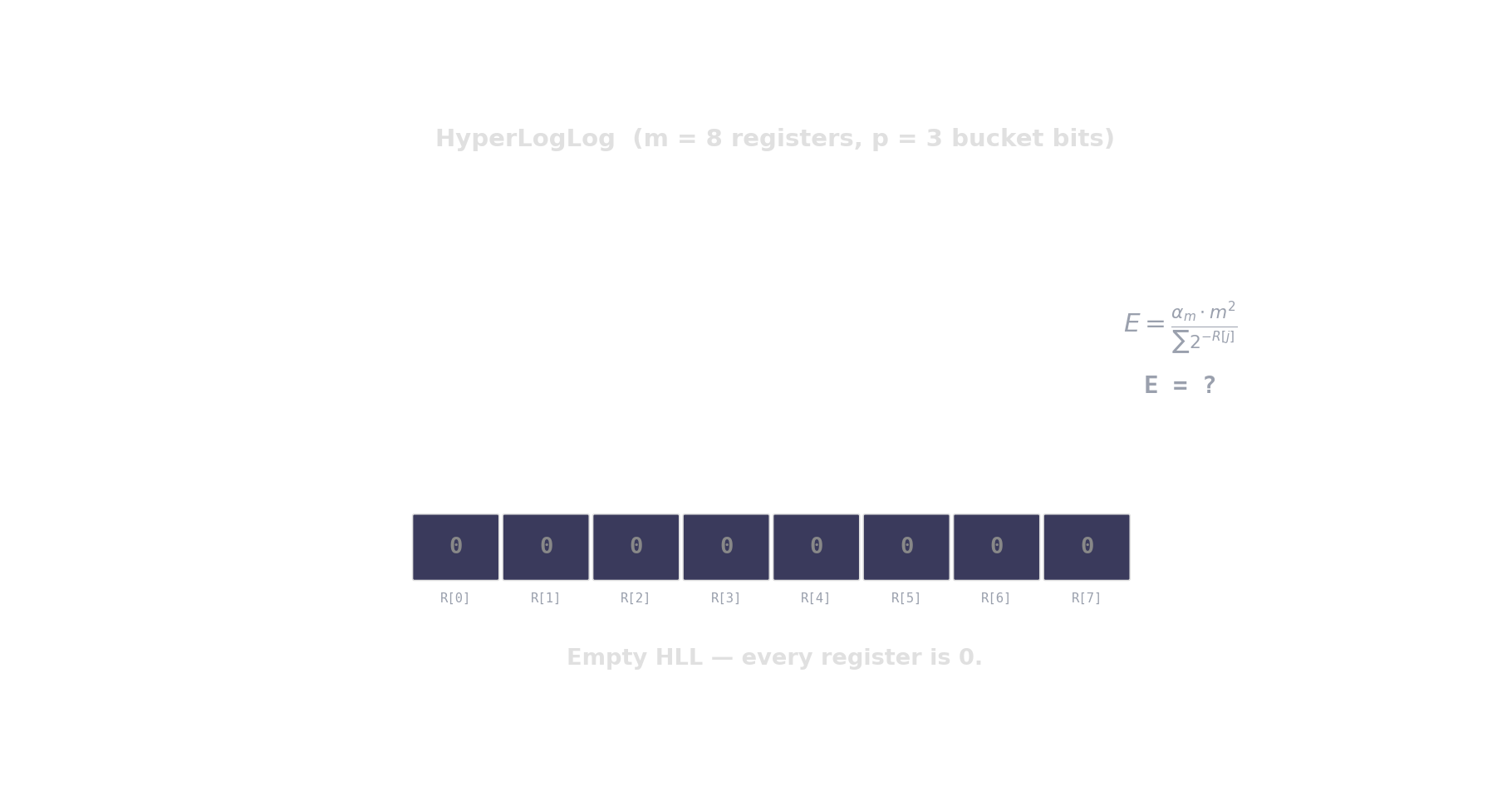
HyperLogLog — distinct-count in kilobytes
Hash each item → count leading zeros → the more distinct items, the higher the maximum.
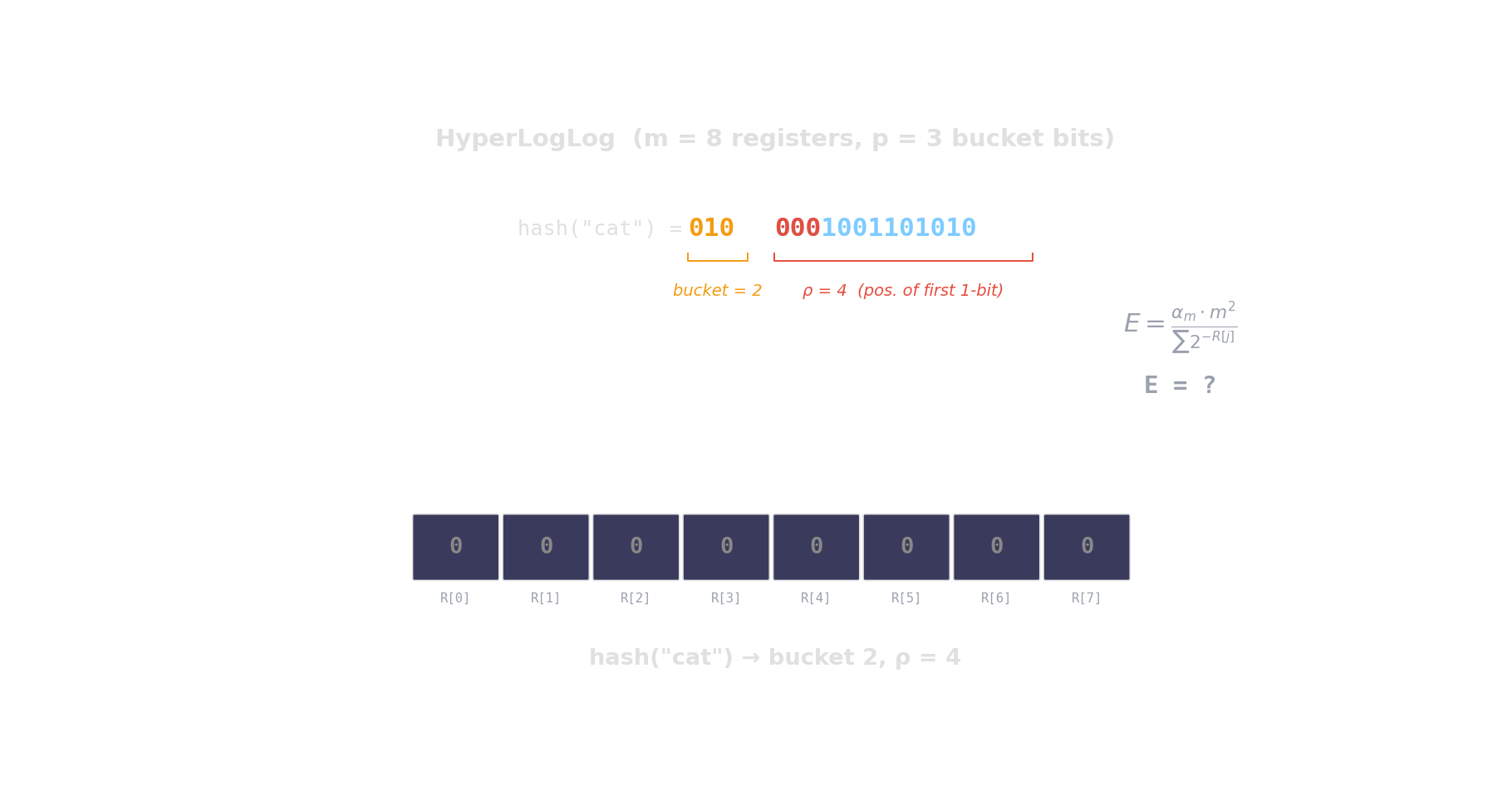
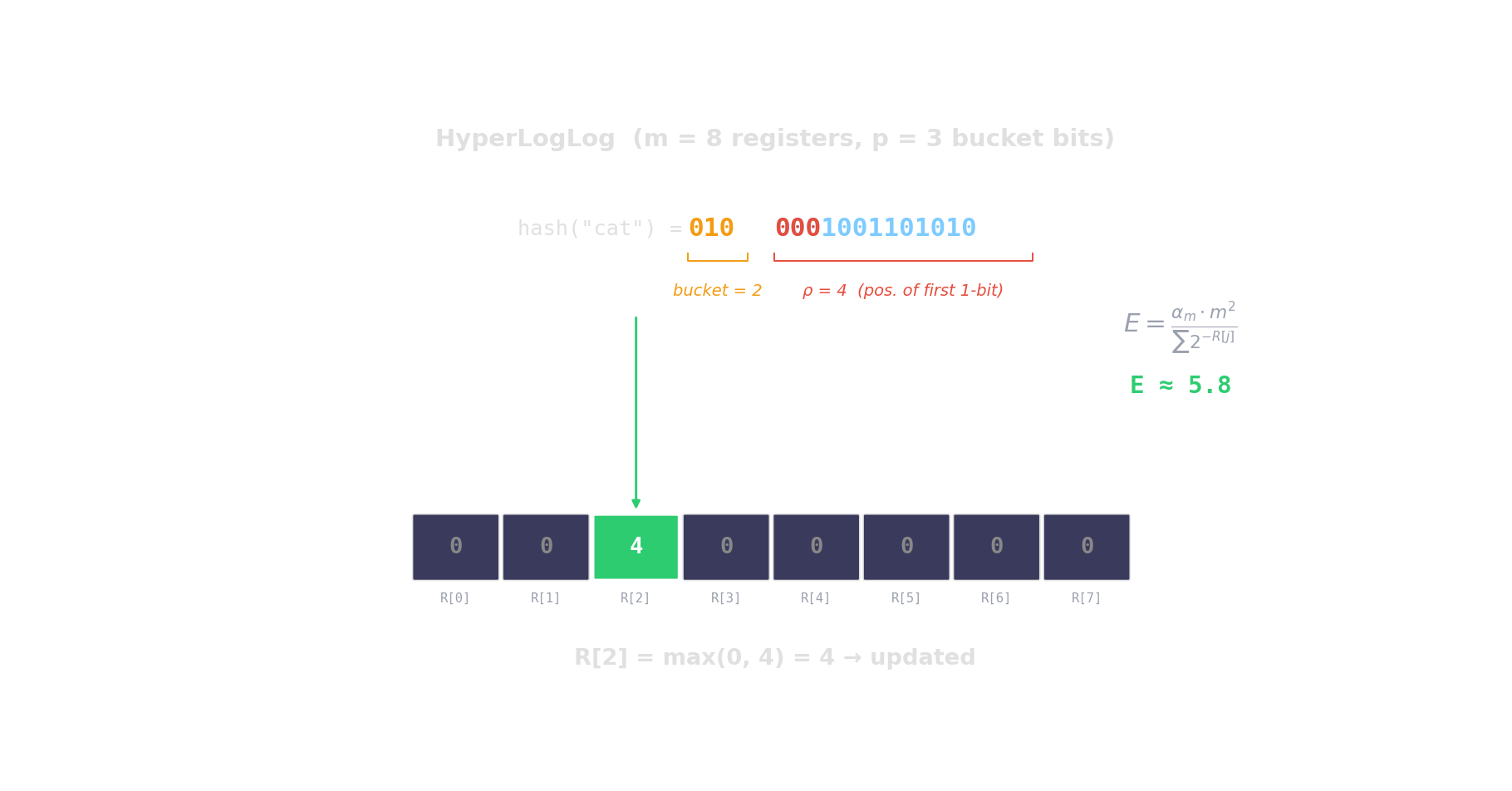
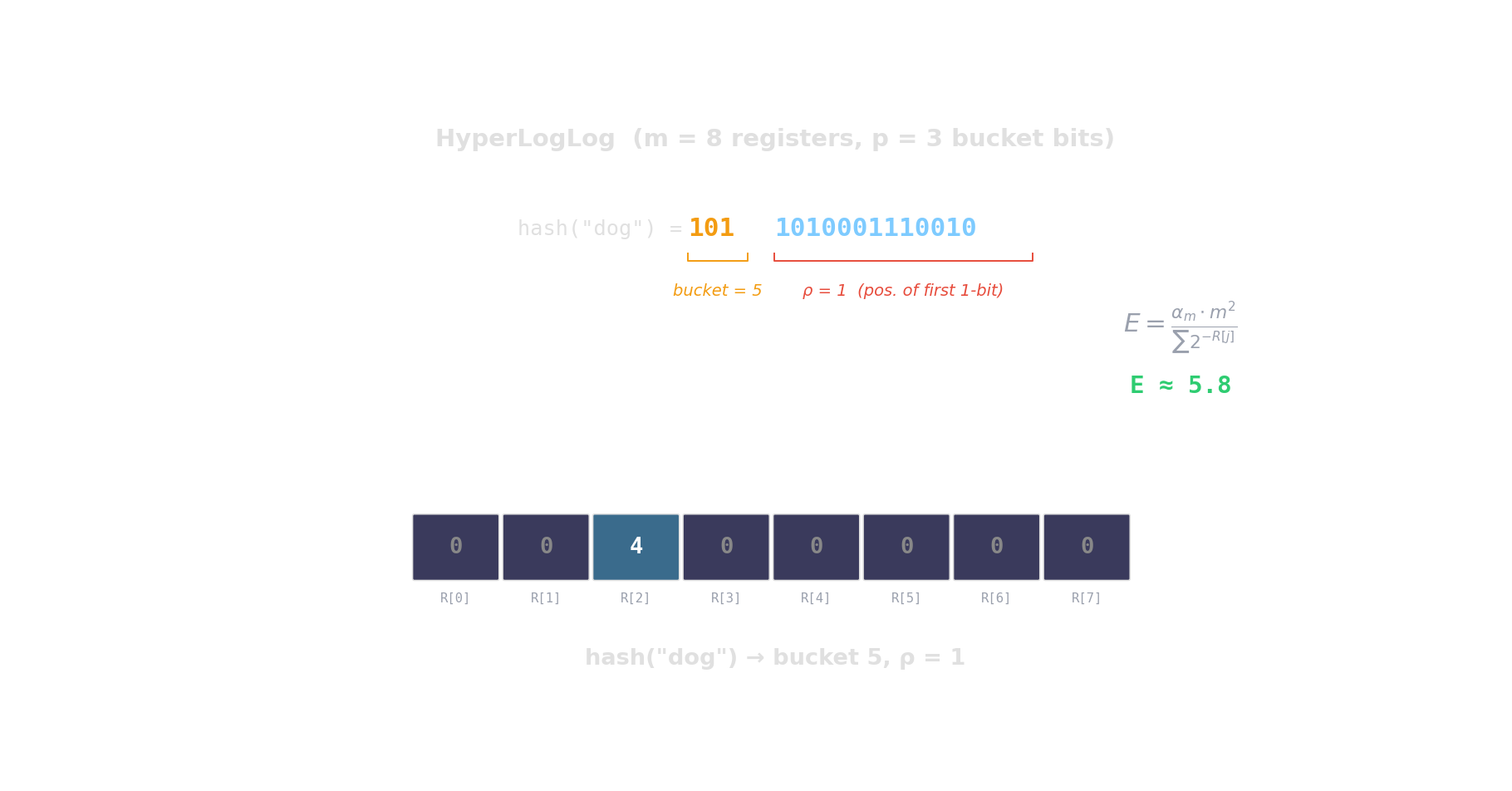
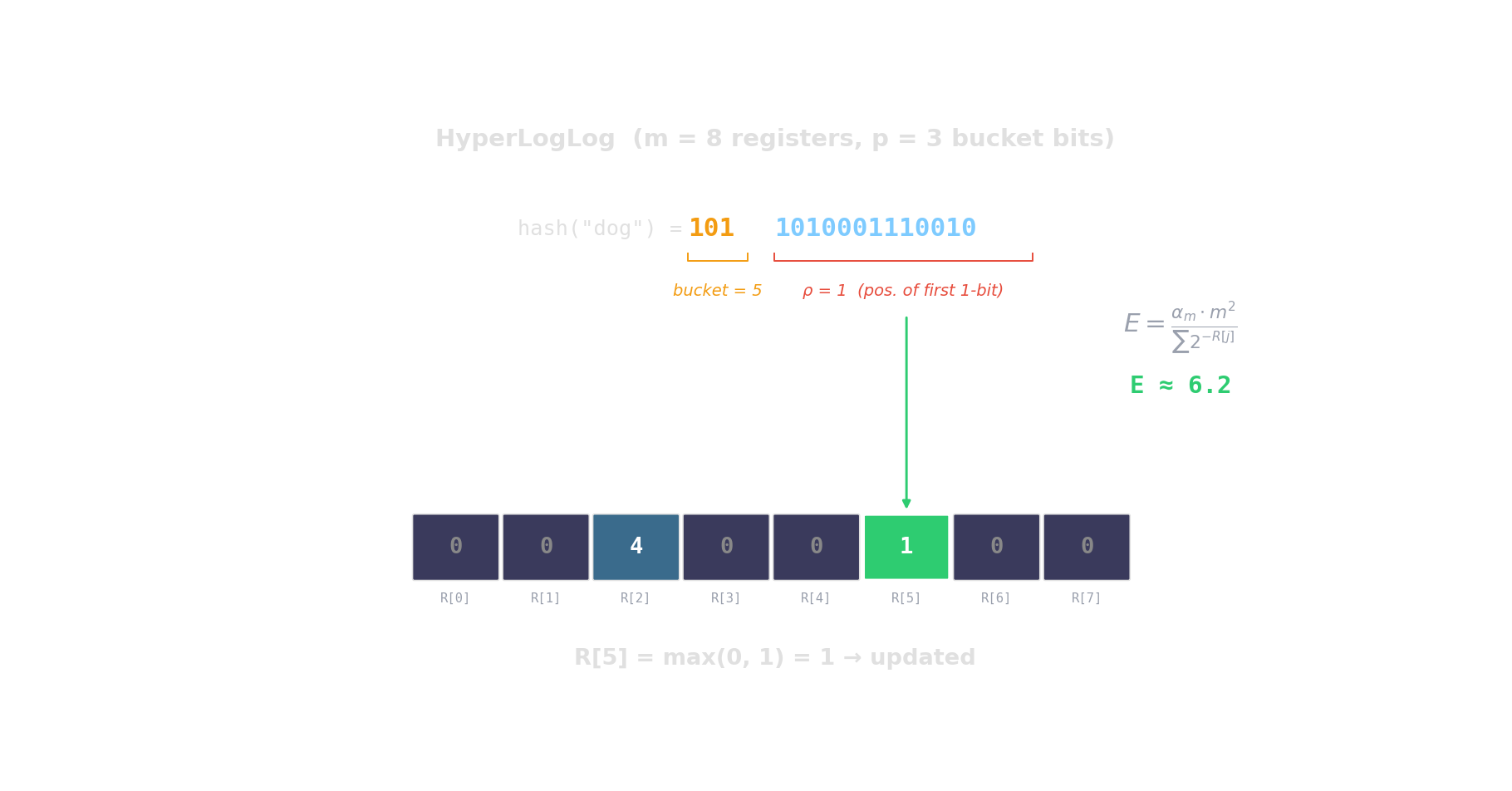
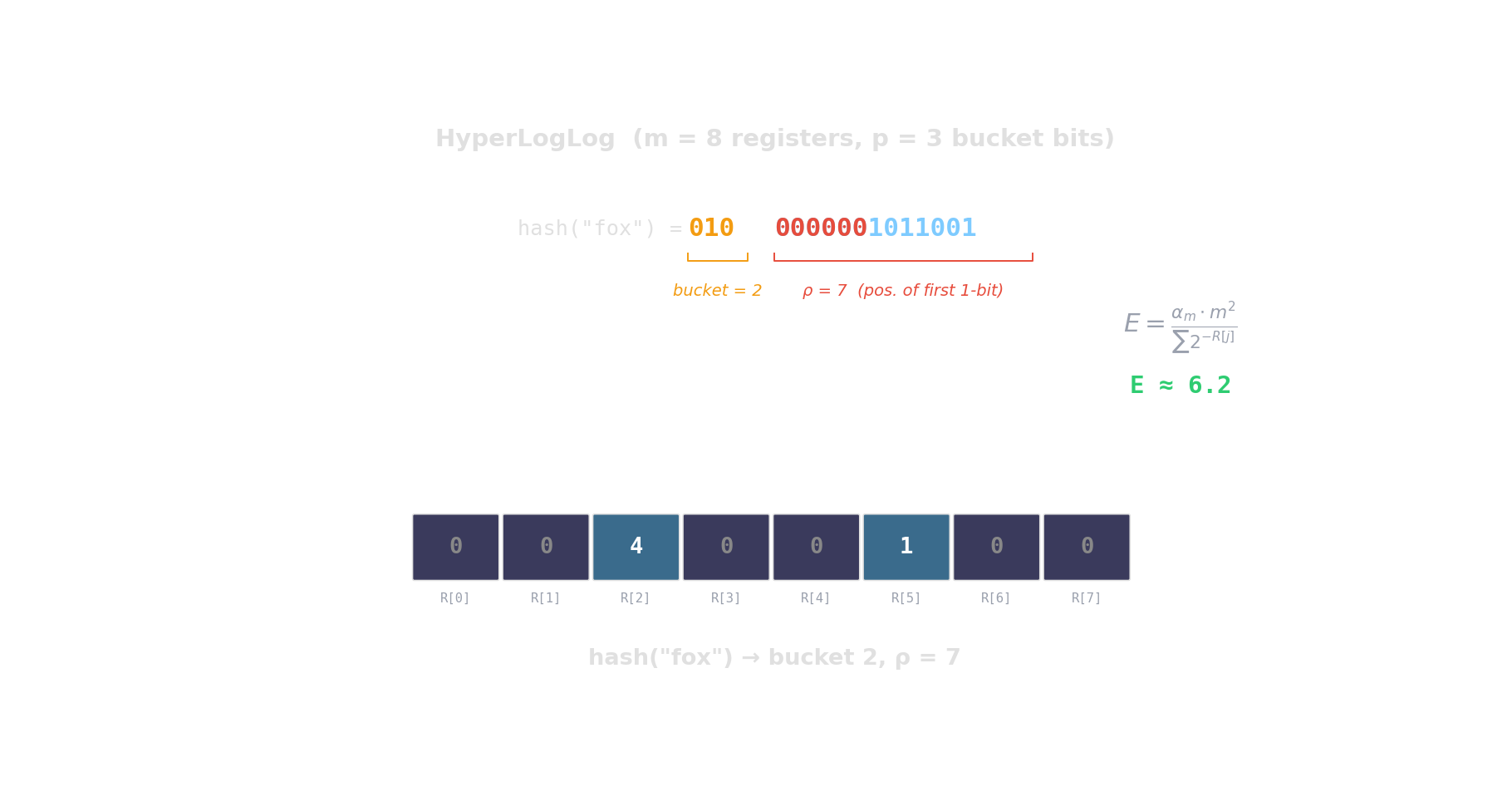
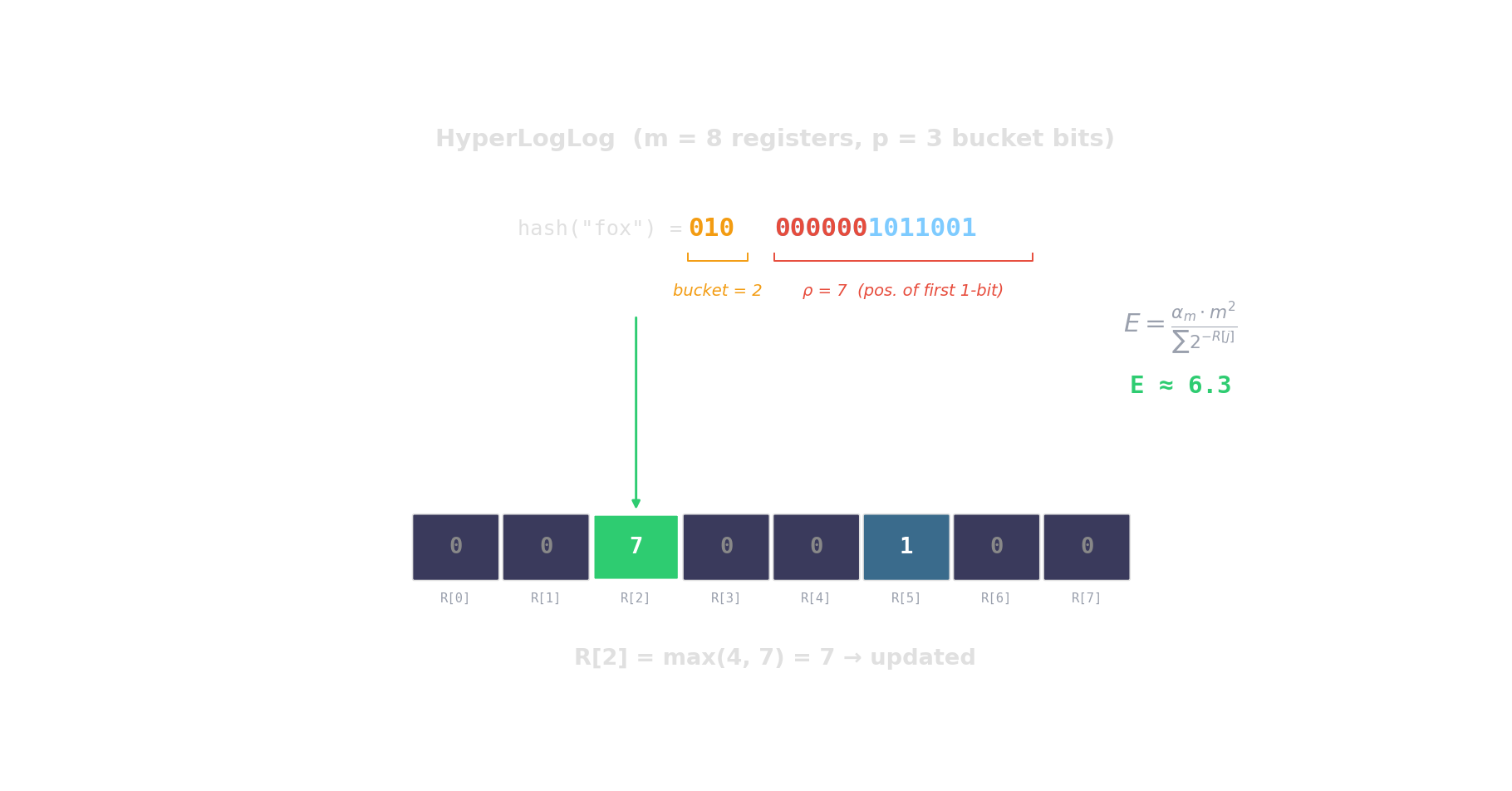
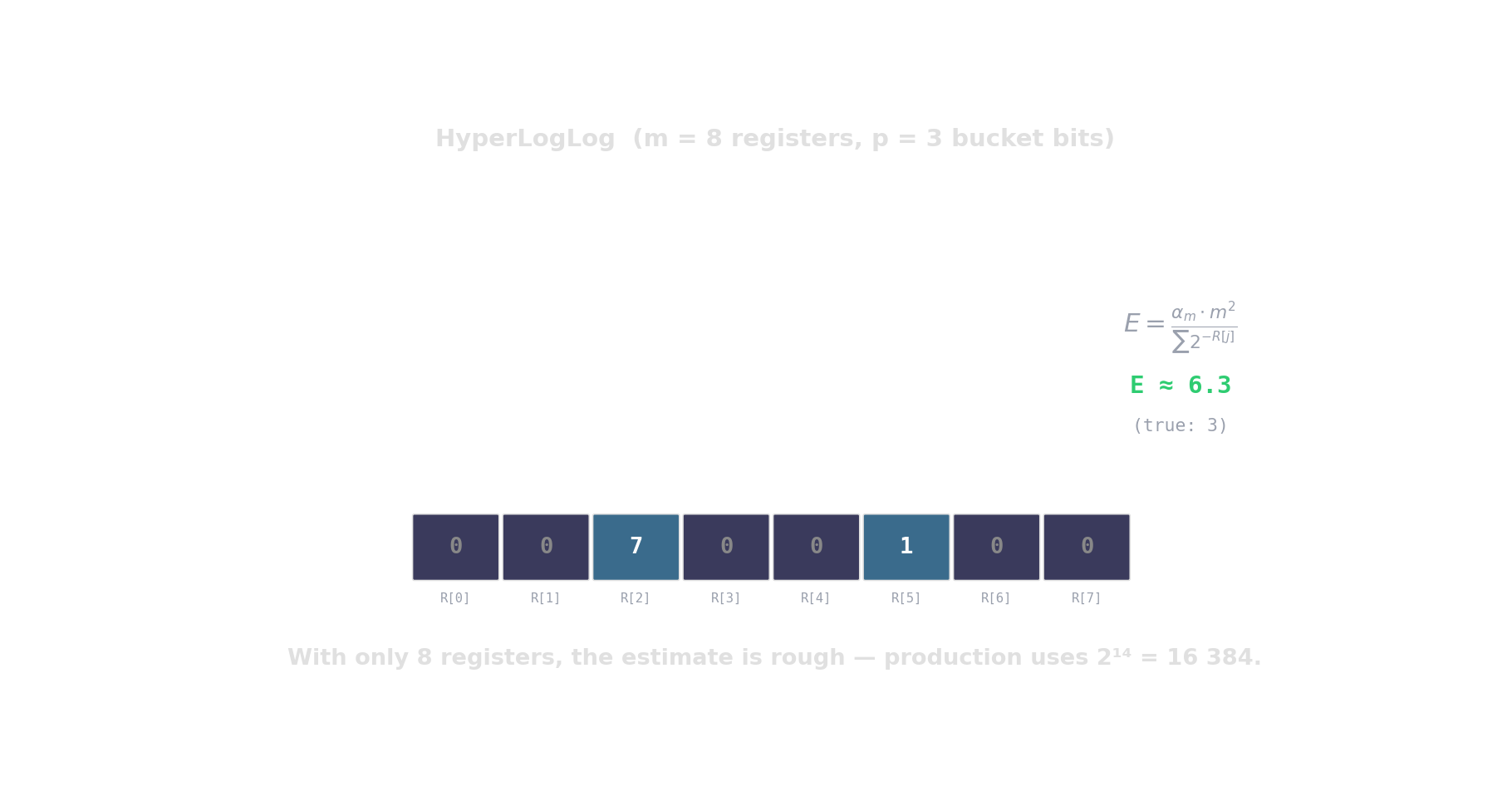
\(2^{14}\) registers = 12 KB \(\Rightarrow\) ~0.8 % error. Redis PFCOUNT, BigQuery APPROX_COUNT_DISTINCT.
What we covered