LP/MIP Modeling
Algorithm Engineering — T03
Network Flow
\[ \min\quad \sum_{e \in E} c_e\, x_e \] \[ \sum_{e \in \delta^-(v)} x_e - \sum_{e \in \delta^+(v)} x_e = b_v\quad \forall v \in V \\ 0 \le x_e \le u_e \quad \forall e \in E \]
Real-world siblings:
- Shipping & logistics: origins to destinations
- Telecom routing: link capacities, endpoint demand
- Power dispatch: generation, load, transmission
- Supply chains: multi-stage production
- Pipeline scheduling: capacitated arcs
Special cases: shortest path, max-flow, transportation, assignment.
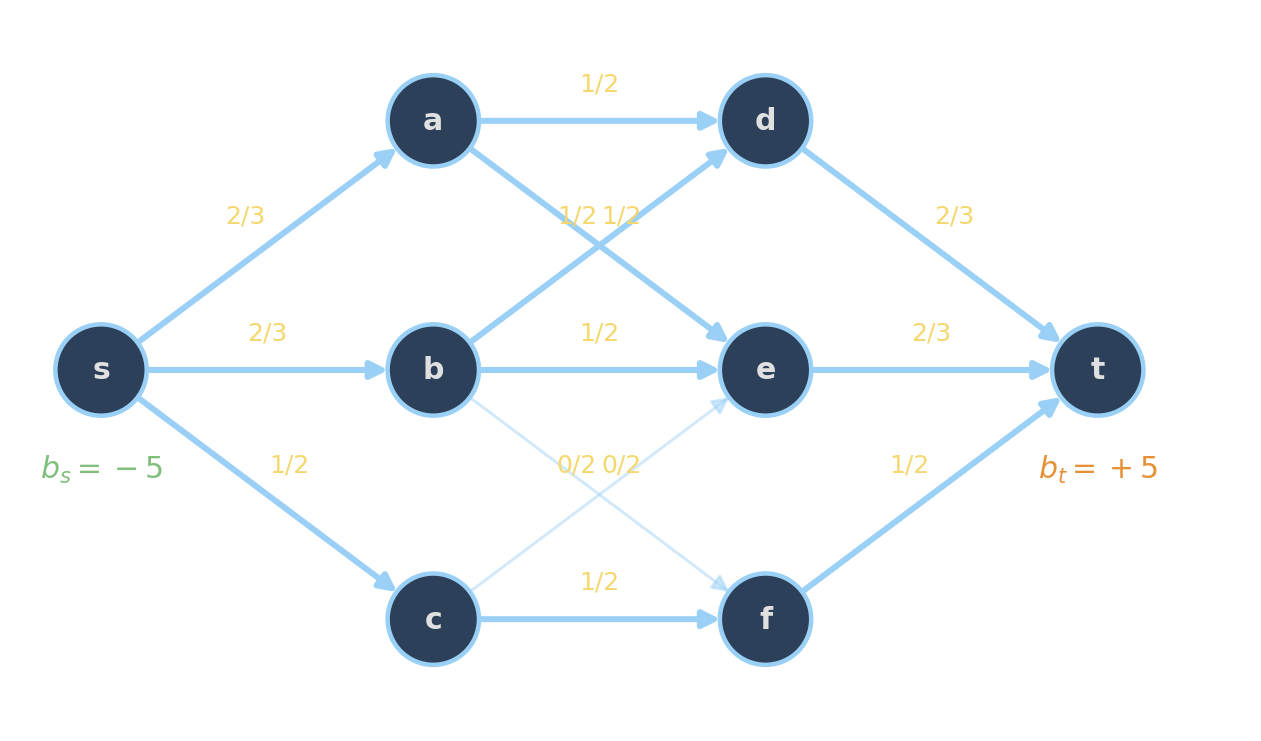
Edge labels: flow \(x_e\) / capacity \(u_e\). \(b_v < 0\) supplies, \(b_v > 0\) demands.
L1 linear regression is a linear program
Given data \((\xi_i, \eta_i)\), fit \(\eta \approx \alpha\,\xi + \beta\) by minimizing \(\sum_i \lvert \eta_i - (\alpha\,\xi_i + \beta) \rvert\).
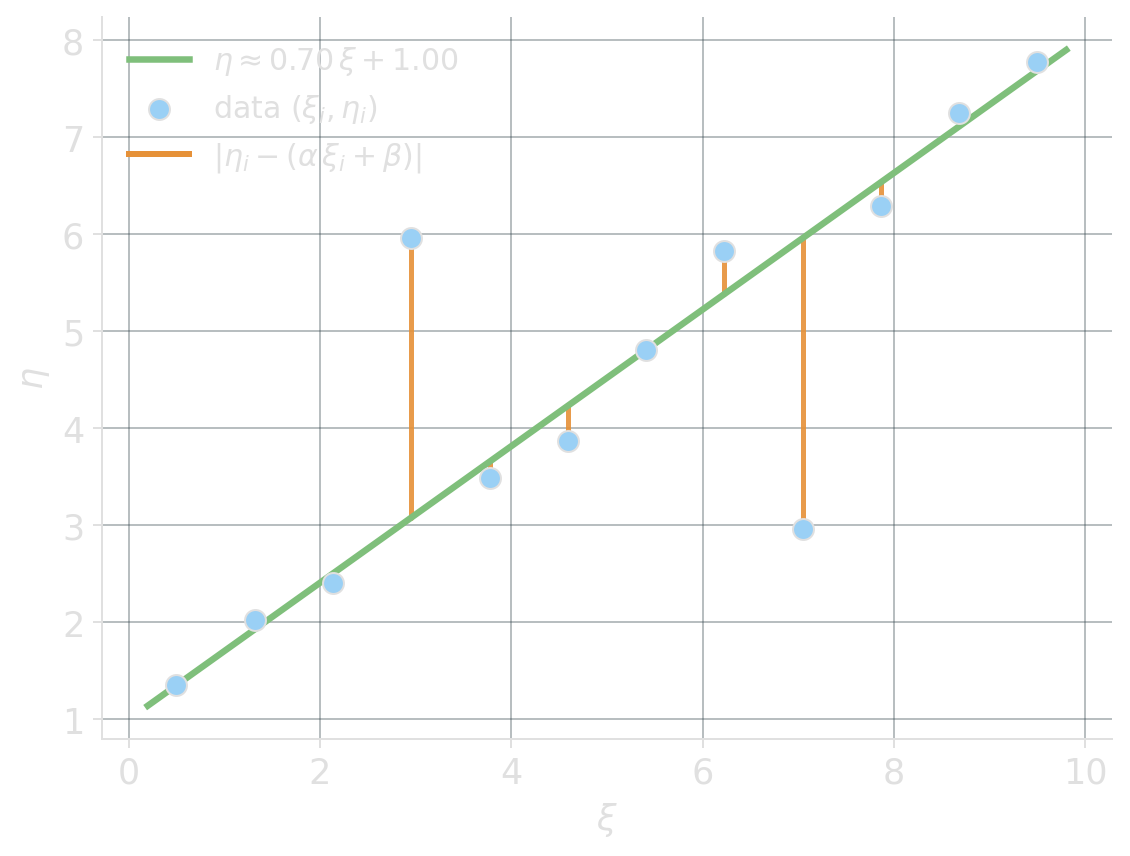
An LP in \(2 + n\) variables: \[ \begin{aligned} \min\quad & \sum_i d_i \\ \text{s.t.}\quad & d_i \ge\ \eta_i - (\alpha\,\xi_i + \beta) && \forall i \\ & d_i \ge\ (\alpha\,\xi_i + \beta) - \eta_i && \forall i \\ & \alpha,\ \beta \in \mathbb{R},\ \ d_i \ge 0. \end{aligned} \]
There are better ways to solve L1 regression than using a general-purpose LP solver.
Learning from Mistakes: Packing Squares with an LP
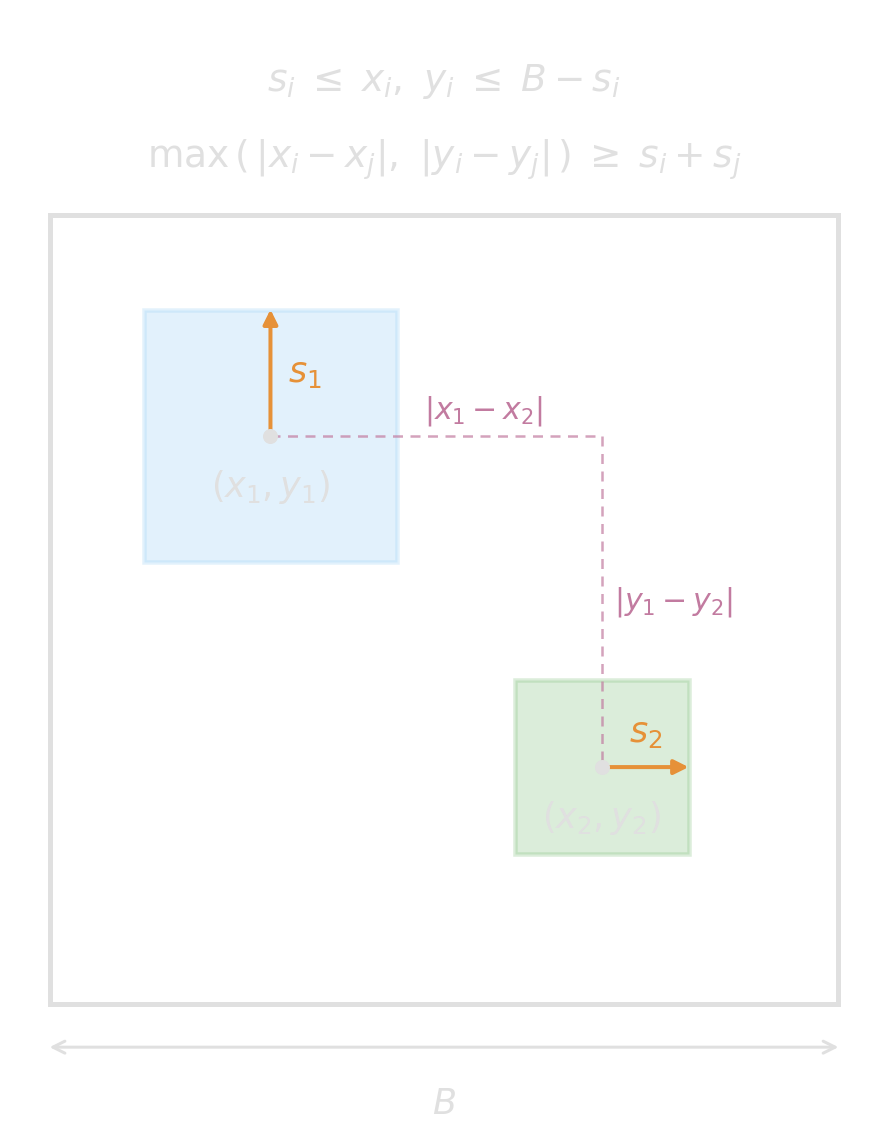
Let us try the trick again: \[ \left. \begin{aligned} d^x_{ij} &\ge x_i - x_j \\ d^x_{ij} &\ge x_j - x_i \end{aligned}\ \right\} \Rightarrow d^x_{ij} \ge \lvert x_i - x_j \rvert \]
Same for the y-axis with \(d^y_{ij}\), and then
\[ \left. \begin{aligned} D_{ij} &\ge d^x_{ij} \\ D_{ij} &\ge d^y_{ij} \end{aligned}\ \right\} \Rightarrow D_{ij} \ge \max(d^x_{ij},\, d^y_{ij}) \]
Will \(D_{ij} \ge s_i + s_j\) guarantee no overlap?
Confucypus says, if your LP solves an NP-hard problem, you probably messed up. Here, we would have needed \(\leq\).
Packing squares as a MIP
\[ \max(|x_i - x_j|, |y_i - y_j|) \ge s_i + s_j \]
can be enforced by \[ \begin{aligned} & x_j - x_i &\ge s_i + s_j - M(1 - b^{R}_{ij}), \\ & x_i - x_j &\ge s_i + s_j - M(1 - b^{L}_{ij}), \\ & y_j - y_i &\ge s_i + s_j - M(1 - b^{A}_{ij}), \\ & y_i - y_j &\ge s_i + s_j - M(1 - b^{B}_{ij}), \end{aligned} \] \[ b^{L}_{ij} + b^{R}_{ij} + b^{A}_{ij} + b^{B}_{ij} = 1. \]
“Need to be separated either from the left, the right, above, or below.”
The Base LP Relaxation doesn’t give us any Information
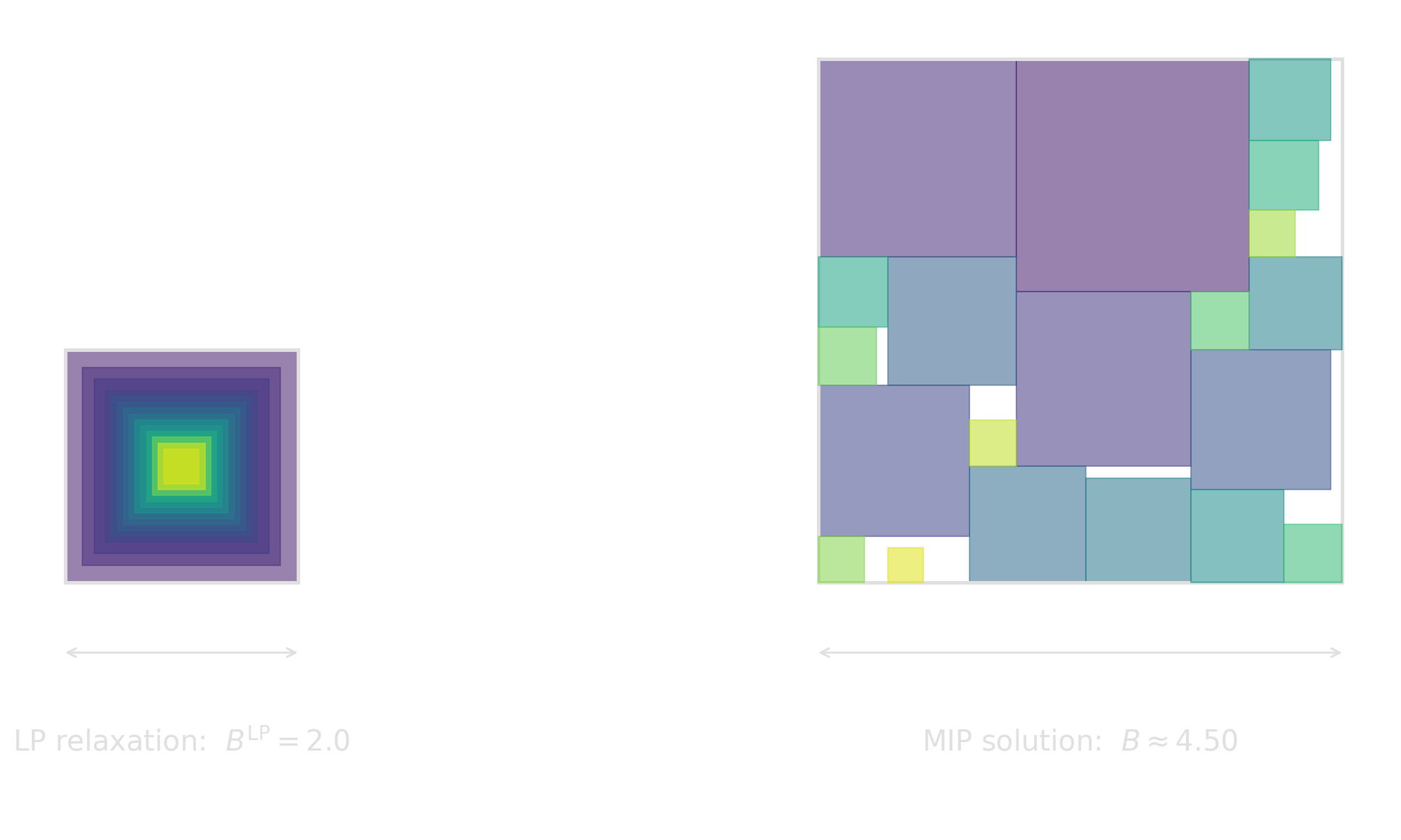
\[ b^{L}_{ij} = b^{R}_{ij} = b^{A}_{ij} = b^{B}_{ij} = 0.25 \]
\[ \begin{aligned} & x_j - x_i \ge s_i + s_j - M(1 - 0.25), \\ & x_i - x_j \ge s_i + s_j - M(1 - 0.25), \\ & y_j - y_i \ge s_i + s_j - M(1 - 0.25), \\ & y_i - y_j \ge s_i + s_j - M(1 - 0.25), \end{aligned} \]
The larger \(M\), the weaker the constraint in the relaxation. In this case, the relaxation is particular weak because even a tight \(M\approx 4\) (why is this tight?) gives too much slack and nearly all constraints are impacted.
But not all is lost!
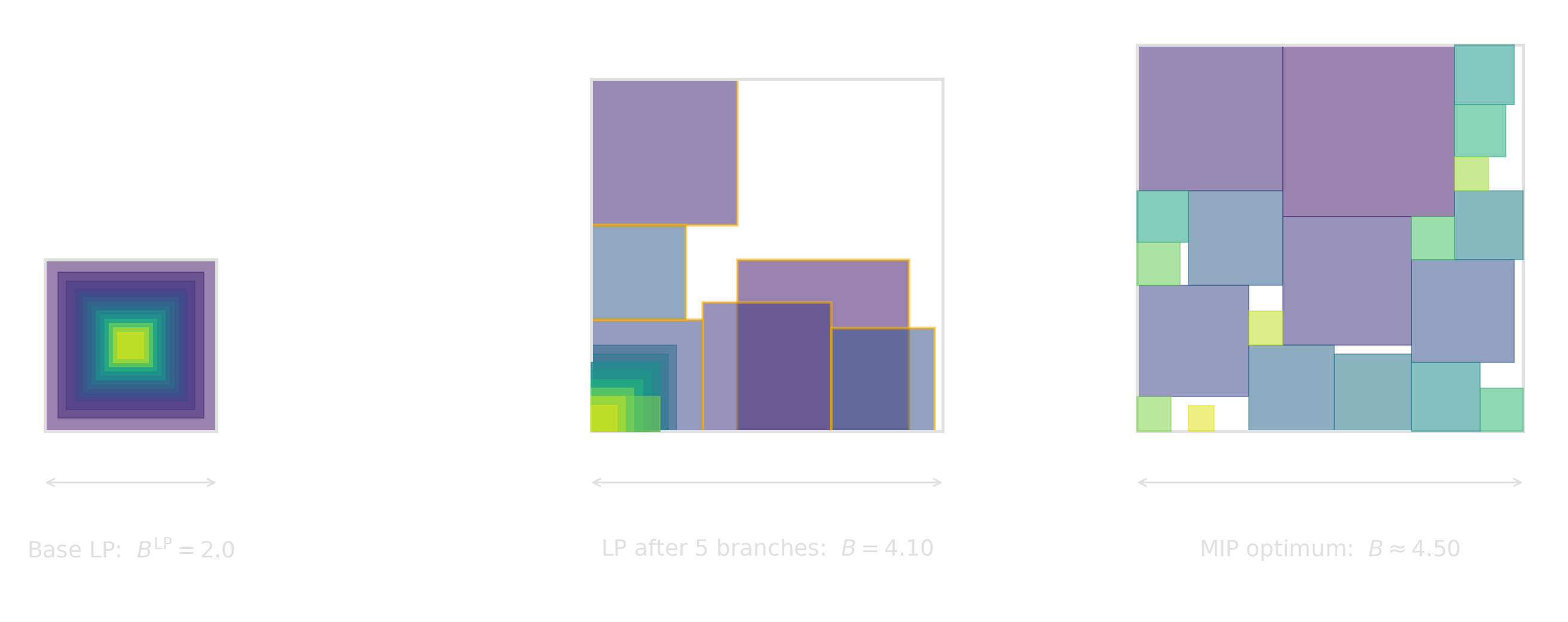
Fixing just five \(b^*_{ij}\) binaries among the largest squares lifts the LP bound from \(2.0\) to \(4.10\), closing most of the gap to the MIP optimum \(B^\star \approx 4.50\). Each branch turns one Big-M slack off and forces a real separation.
How do we model this?
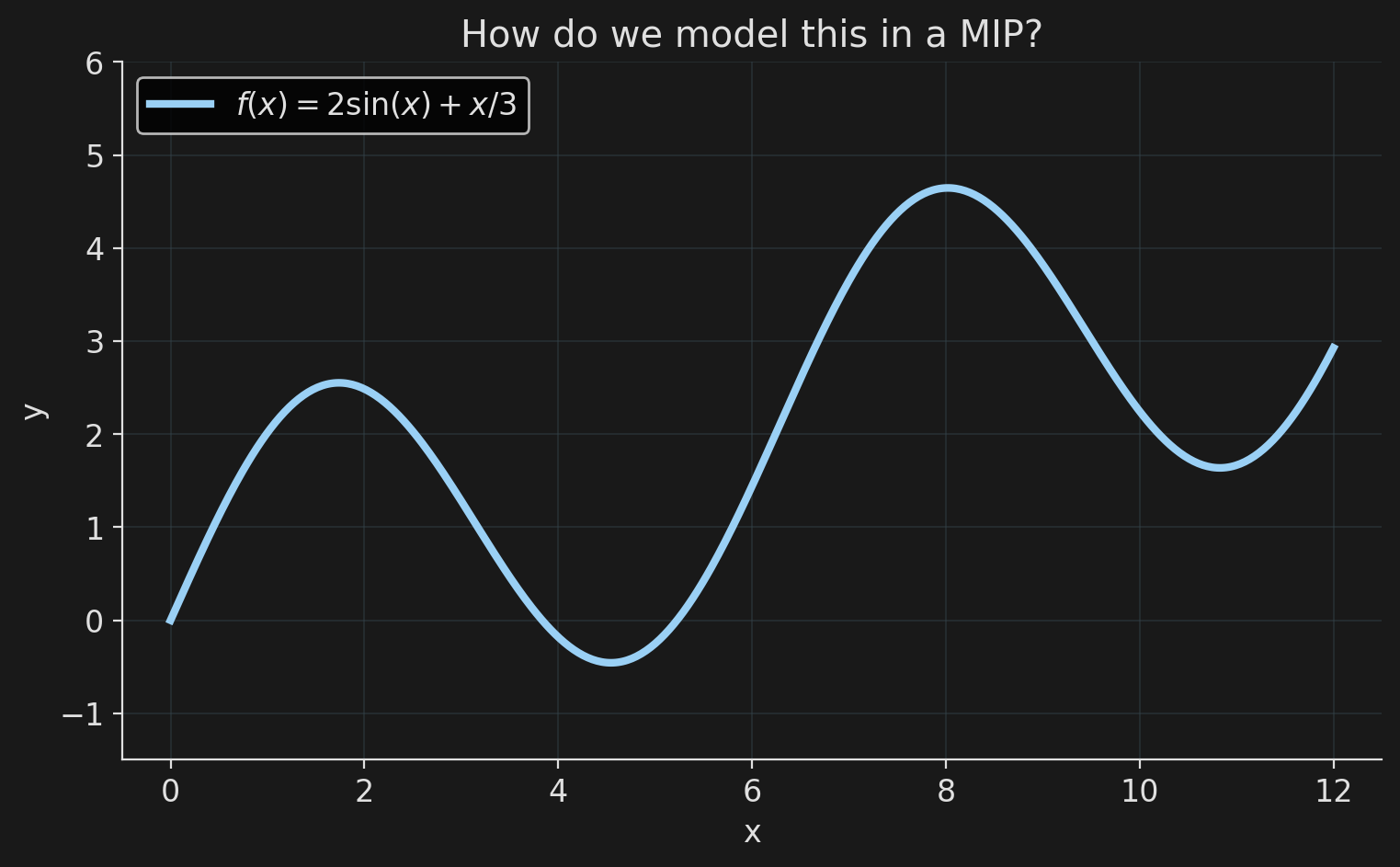
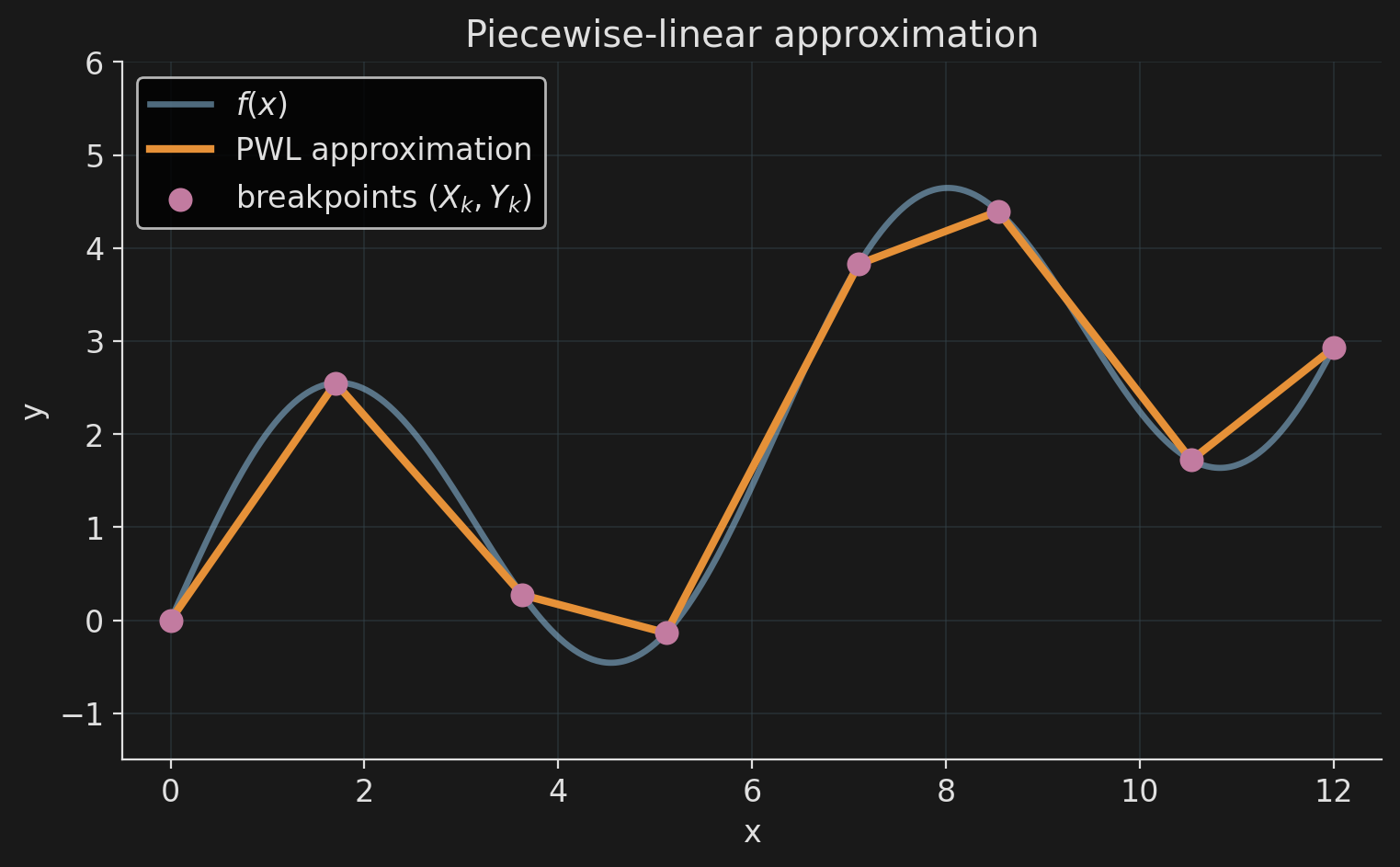
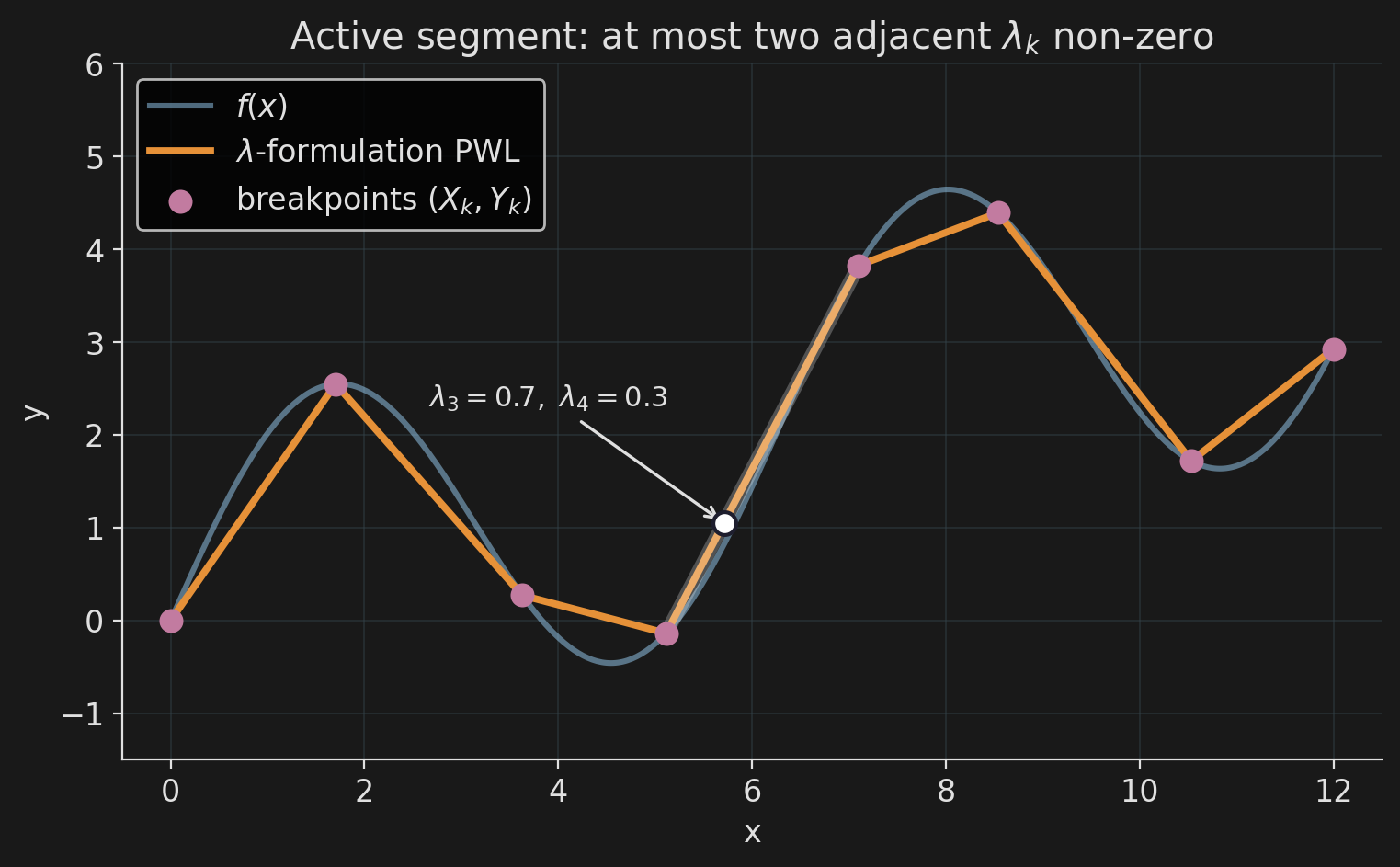
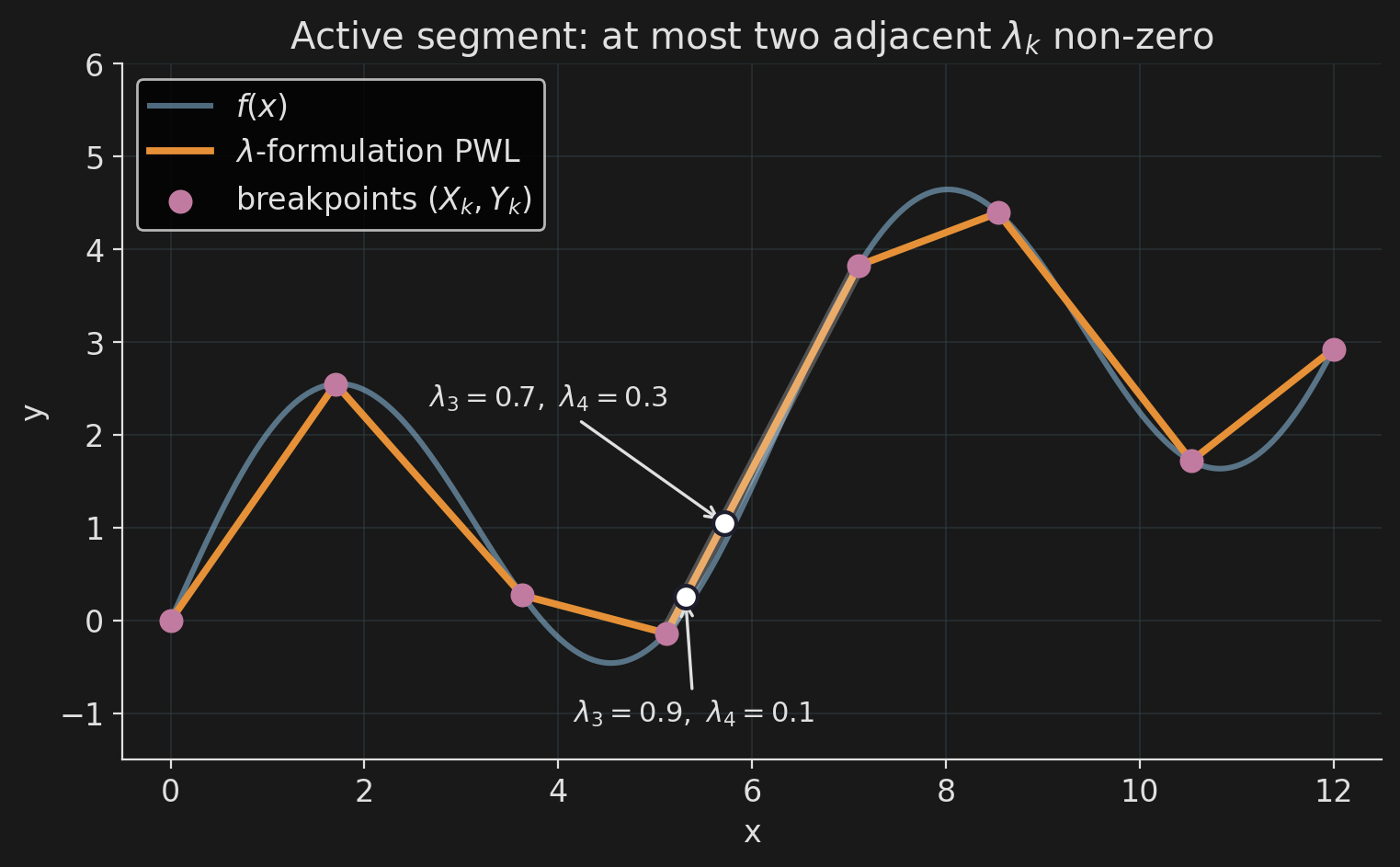
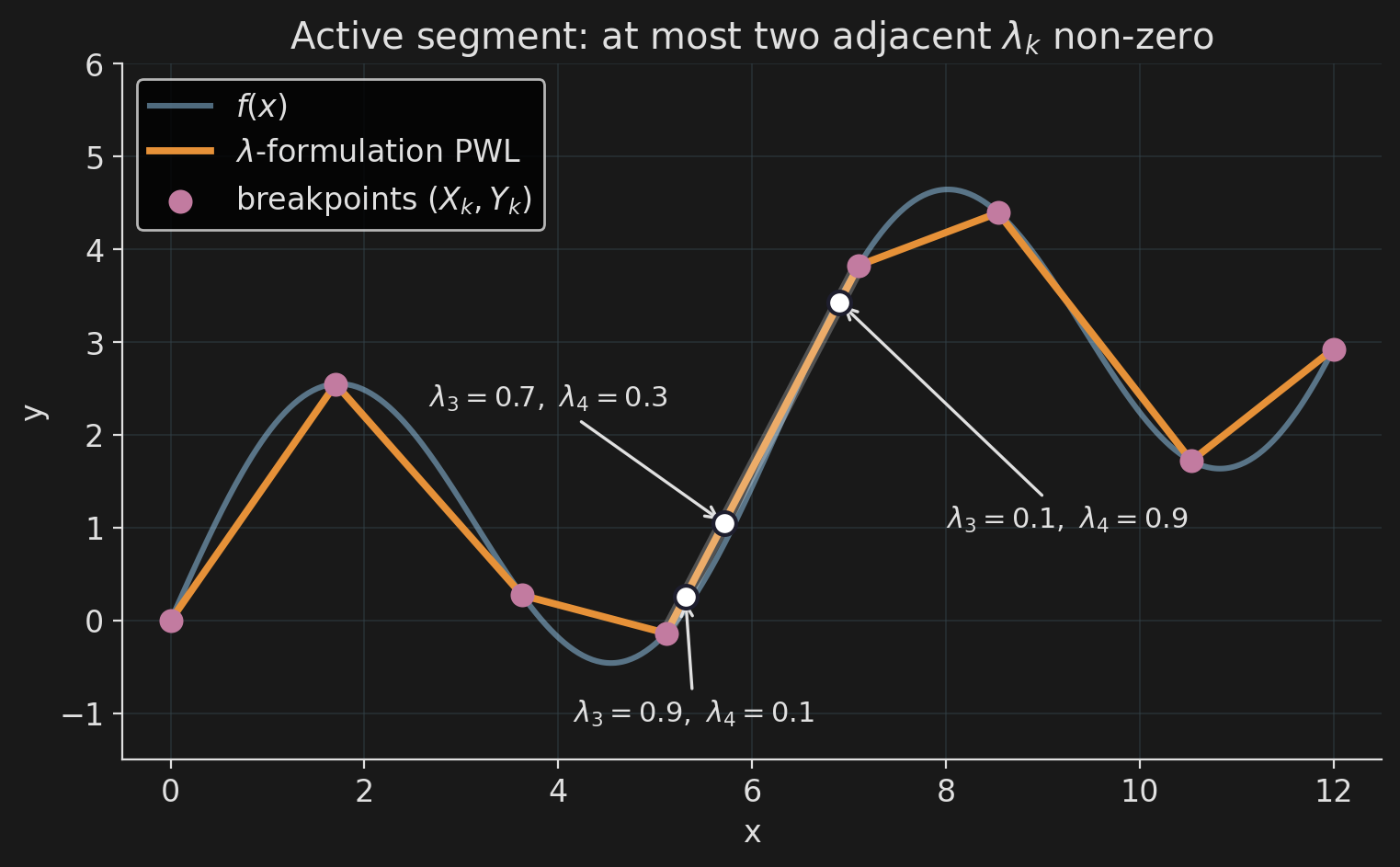
Encoding the PWLA
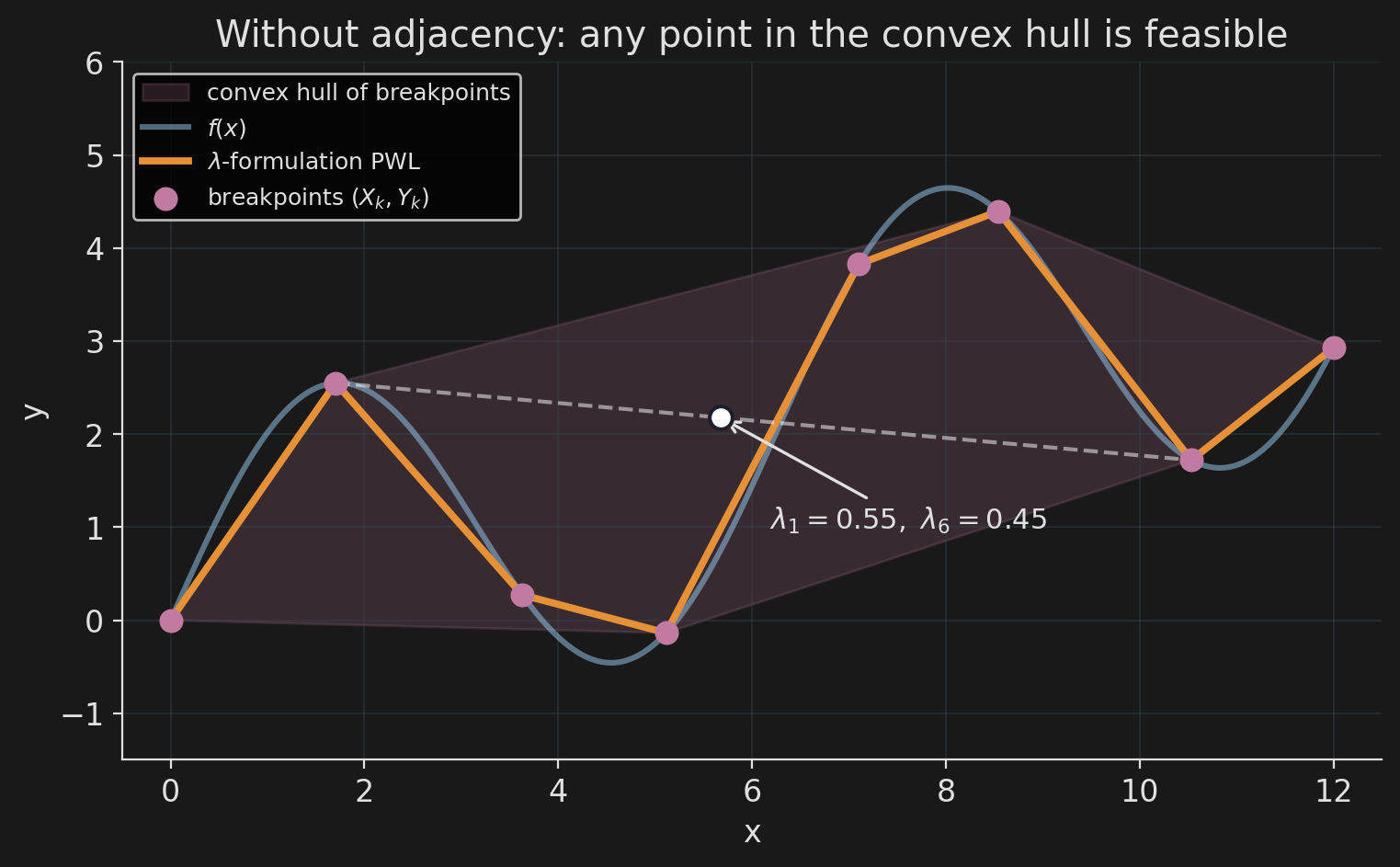
Breakpoints \((X_k, Y_k)\) are data. Each \(x\) is a convex combination of the \(X_k\); \(y\) uses the same weights:
\[ x = \sum_k \lambda_k\, X_k, \qquad y = \sum_k \lambda_k\, Y_k, \qquad \sum_k \lambda_k = 1, \;\; \lambda_k \ge 0. \]
Adjacency. Only two consecutive \(\lambda_k\) may be non-zero. One activation binary \(b_k\) per segment:
\[ \lambda_0 \le b_0, \quad \lambda_K \le b_{K-1}, \]
\[ \lambda_k \le b_{k-1} + b_k, \quad \sum_k b_k = 1. \]
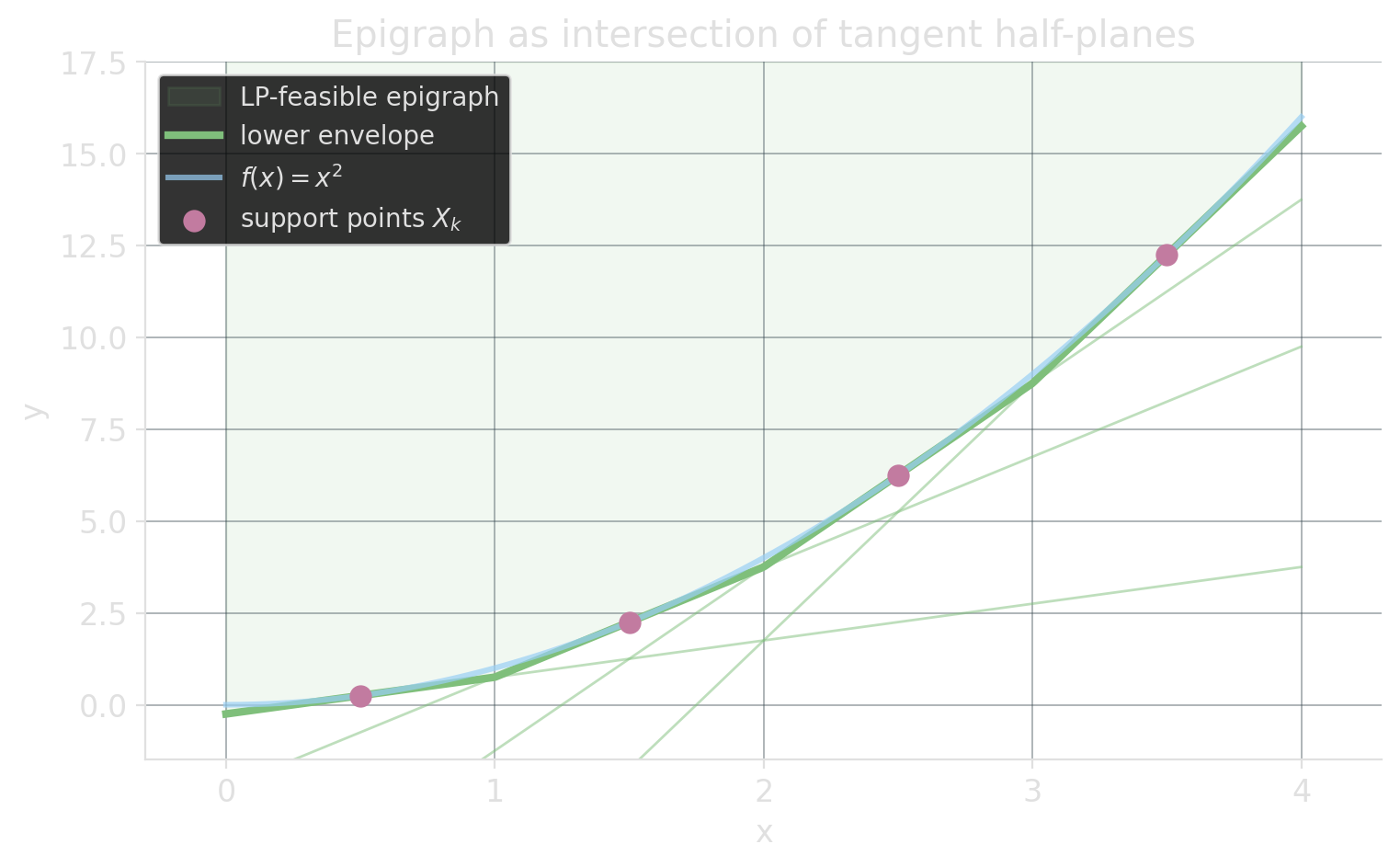
Convex functions: no binaries needed
For convex \(f\), the epigraph \(\{(x, y) : y \ge f(x)\}\) is itself convex. Tangent half-planes from below give an LP-only encoding:
\[ y \;\ge\; f'(X_k)\, (x - X_k) + f(X_k) \qquad \text{for each chosen support } X_k. \]
The LP picks the binding tangent automatically: objective pressure pulls \(y\) down to the envelope. No binaries.
Only enforces \(y \ge f(x)\). Equality \(y = f(x)\) still needs segment-selection binaries.
Non-linear solvers do PWLA in secret
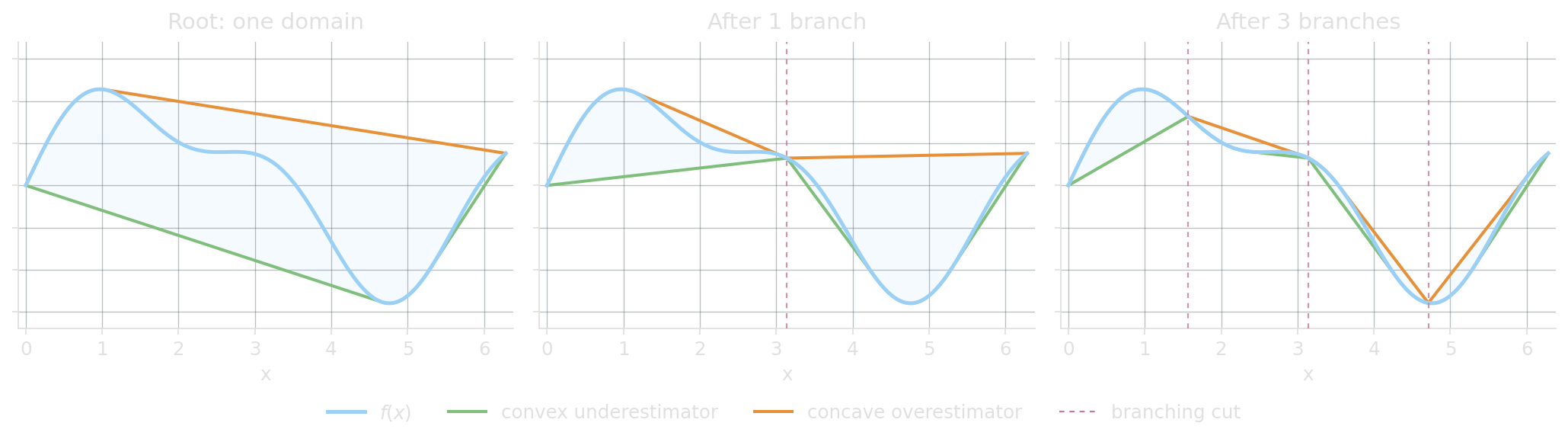
Some non-linear solvers approximate the function with convex/concave envelopes, branch on the variable’s domain, and refine the envelopes on every child node. Linear relaxations all the way down: an LP solver underneath, solving a non-linear problem.
Facility location: open some sites, serve all customers
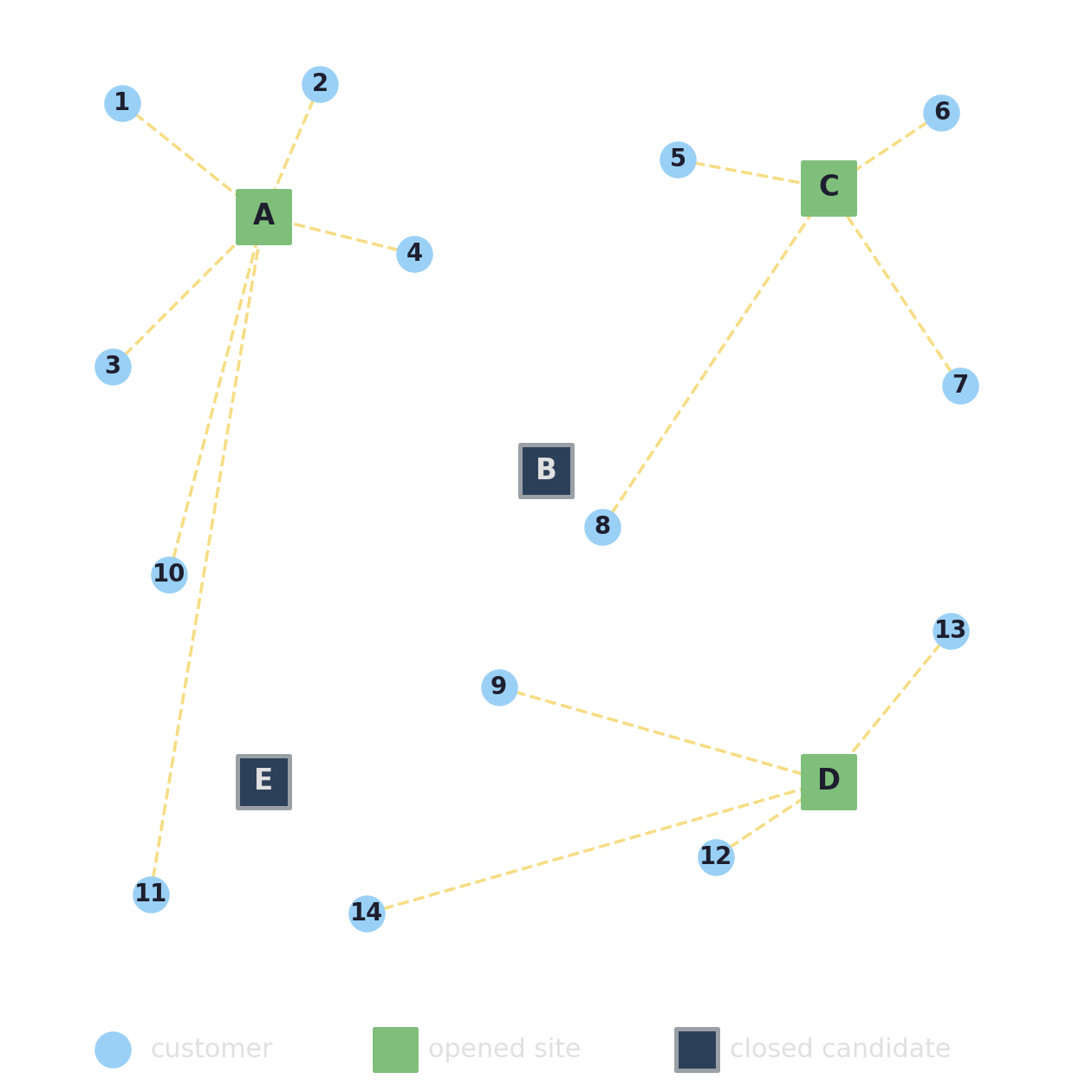
Customers need to be served from depots. Each candidate site \(j\) has a fixed opening cost \(f_j\); each pair carries a shipping cost \(c_{ij}\).
Pick which sites to open and how to assign every customer to an open site so that the total cost (opening plus shipping) is as small as possible.
The separation theorem
Grötschel–Lovász–Schrijver (1981). An LP can be optimized in polynomial time iff its separation problem can be solved in polynomial time.
Separation: given \(\hat x\), return a violated constraint or certify there is none.
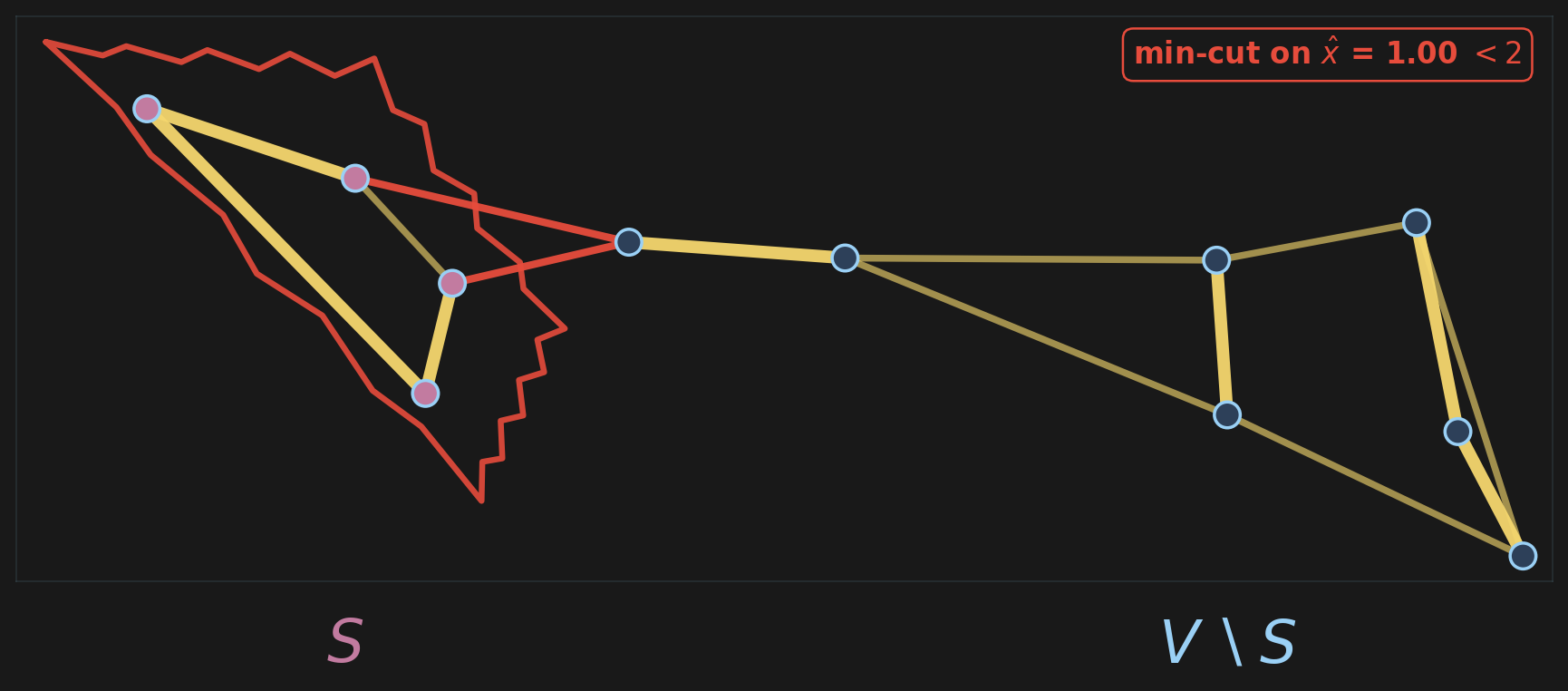 For DFJ, separation is min-cut on the graph weighted by \(\hat x\): cut value \(< 2\) yields a violated subtour inequality.
For DFJ, separation is min-cut on the graph weighted by \(\hat x\): cut value \(< 2\) yields a violated subtour inequality.
Confucypus says: under LP duality, variables are constraints and constraints are variables. The dual of separation is column generation.
The complexity of an LP is not defined by its naive size.
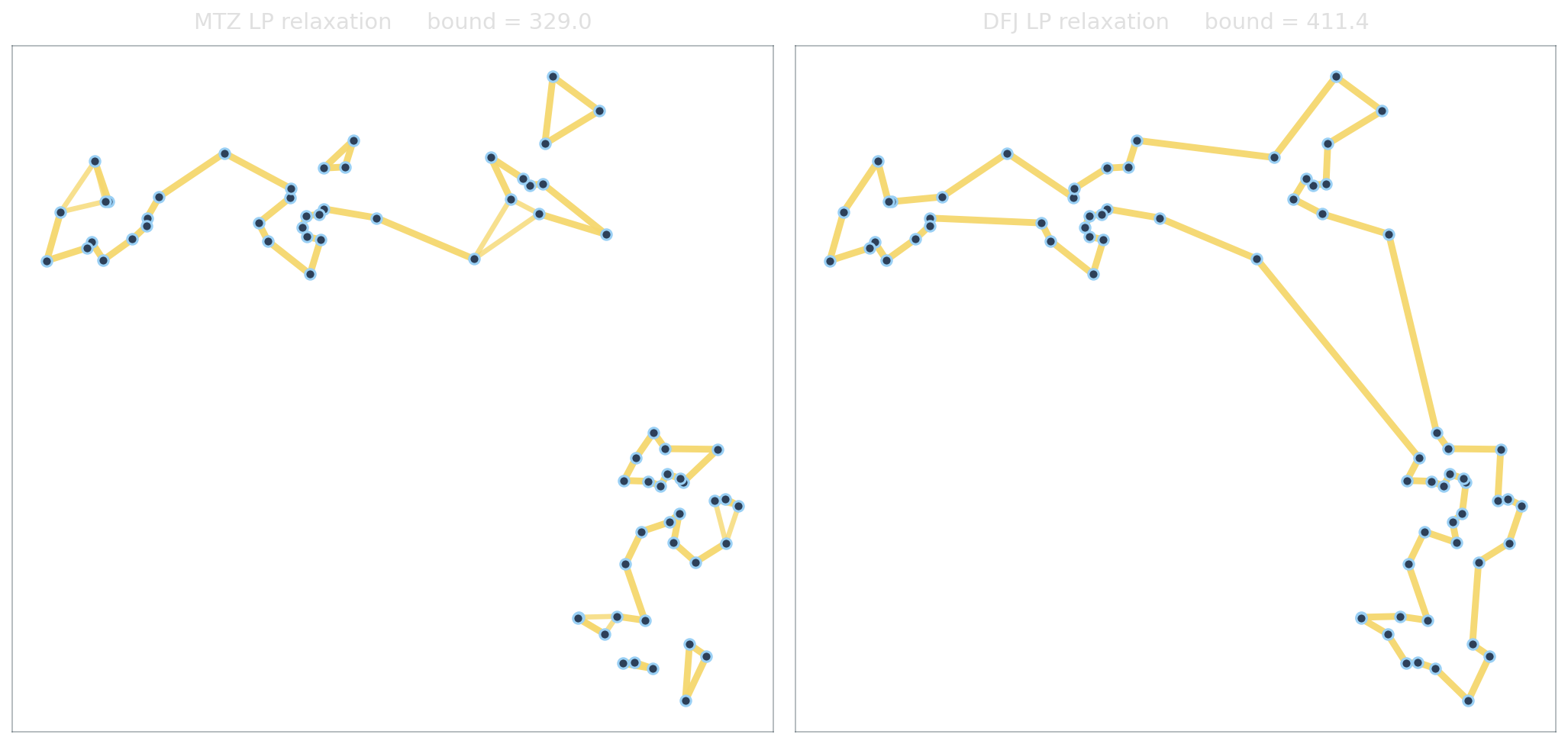
The LP relaxations, side by side